Day24-Kaggle Titanic迈进前5% part(1)
前面23天讲了这麽多,我们学会了numpy、pandas、seaborn、sklearn、pytorch
我想我们应该有足够的能力可以开始做Titanic资料集了
直接进入正题
载入会使用到的套件
这些套件前面都有介绍过,如果有忘记的部分请回头看一下前面的文章
载入资料集
在kaggle Titanic的网站即可下载到资料集,分为train.csv、test.csv、gender_submission.csv
train.csv为训练用资料,包含要训练的label
test.csv为测验资料,不包含label
gender_submission.csv为缴交范例资料,不会用到所以没有载入

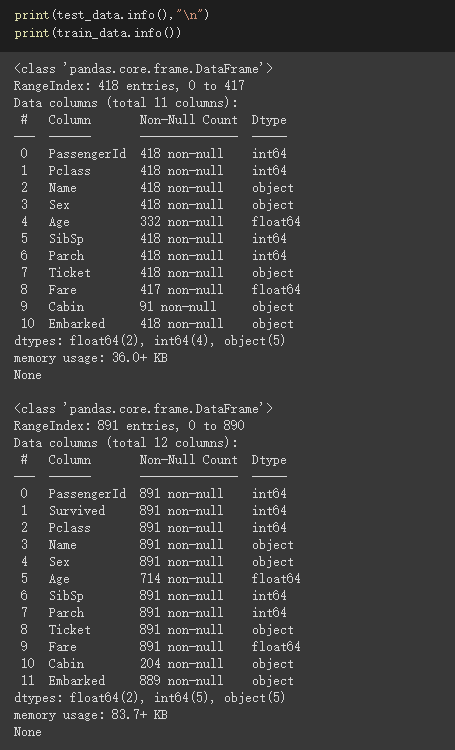
查看资料集状况
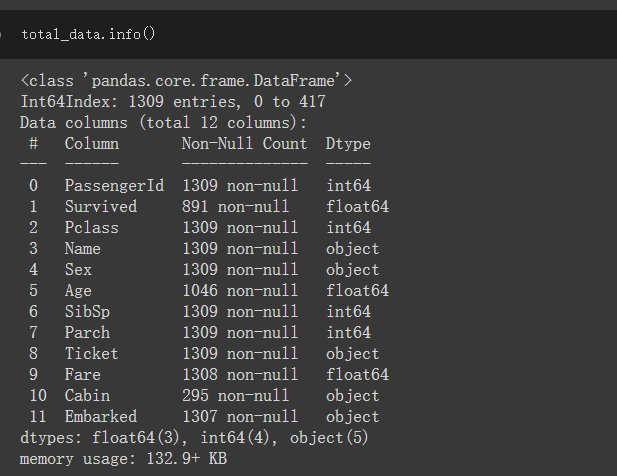
test资料有11个栏位,train资料则有12栏位,多了个Survived的栏位,此栏位就是我们要预测的值
可看出test_data、train_data都有些缺失值且各资料型态也都不太一样
所以我们要做一些前处理的工作来解决此问题
资料探勘与前处理
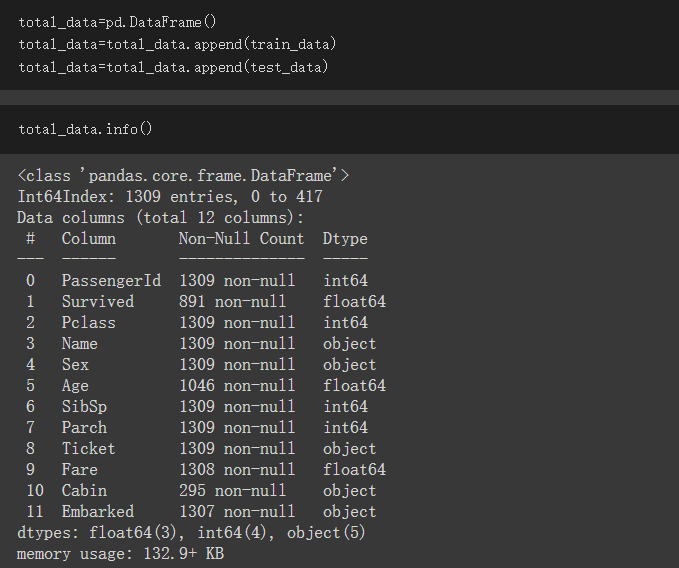
资料合并处理:
建立一个DataFrame并命名为total_data
利用append方法将train_data、test_tada都放入total_data
将train_data、test_data合并後一起做前处理比较方便
注意:之後资料做视觉化时,我都会用train_data来做,不会用test_data,因为train_data资料包含Survived栏位,且我们在训练资料时,应配合train_data的状况来使用
PassengerId栏位:
此栏位的资料为乘客的资料ID,依据顺序排列,对於训练资料没有用
Survived栏位:
此栏位来记录乘客有无生存,0代表无,1代表存活,为我们要预测的栏位
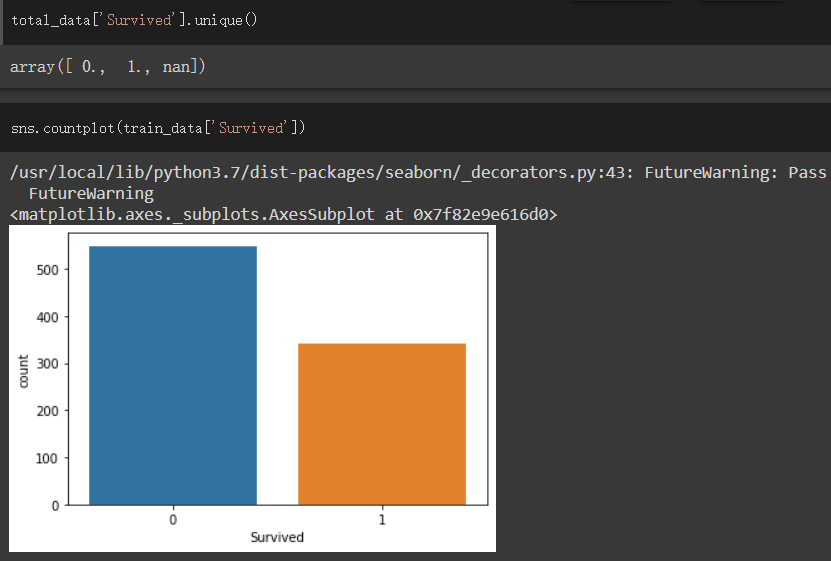
total_data['Survived'].unique()可看出里面包含三种资料0、1、空值
此空值是因为test_data没有此栏位
使用seaborn的countplot来看有无生存的资料个数
可看出生存的人数略少於没有生存的人数,差距不会到太大,不会使训练资料不平衡
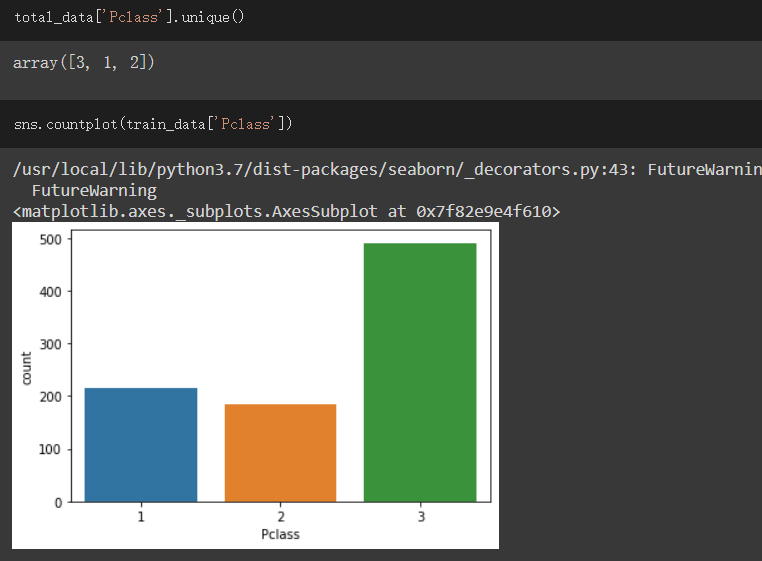
Pclass栏位:
此栏位表示舱等,分为1、2、3三种,1为最好,3为最差
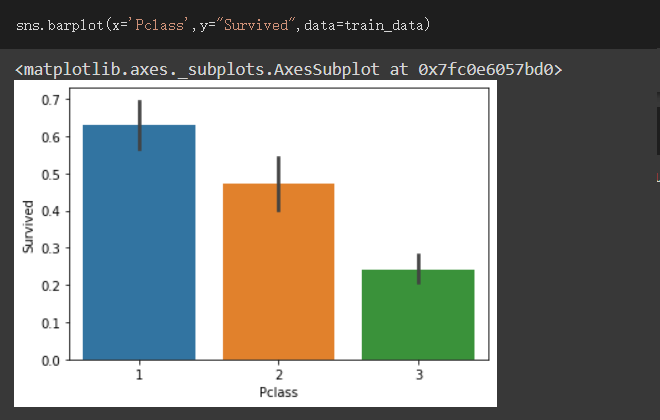
依据Pclass与Survived做资料视觉化
可看出舱等愈好生存率愈高
Name栏位:
此栏位为各乘客的名字,这里我们不会使用到
Sex栏位:
表示性别,male、female
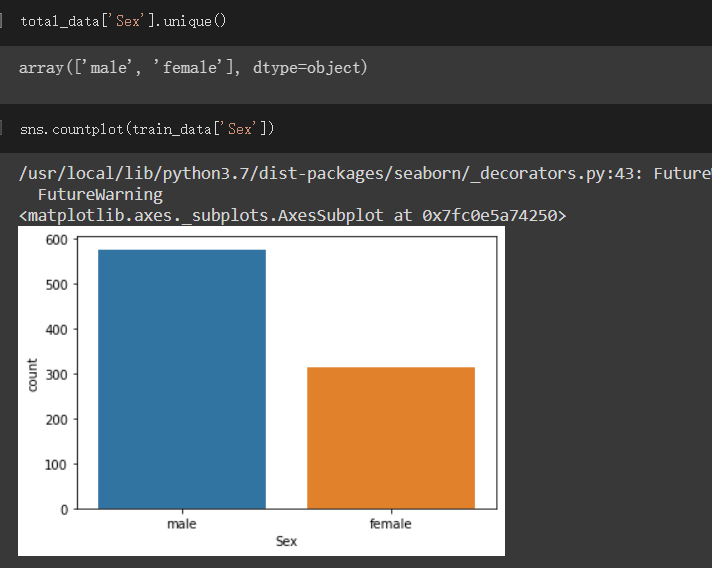
因为male、female都不是数值,我们必须将它们转为数值才能拿下去train
这边使用LabelEncoded解决此问题
Age栏位:
表示乘客的年龄
透过total_data.info()可看出此栏位有不少缺失值,等等观察完资料要思考要用什麽值去填补缺失值
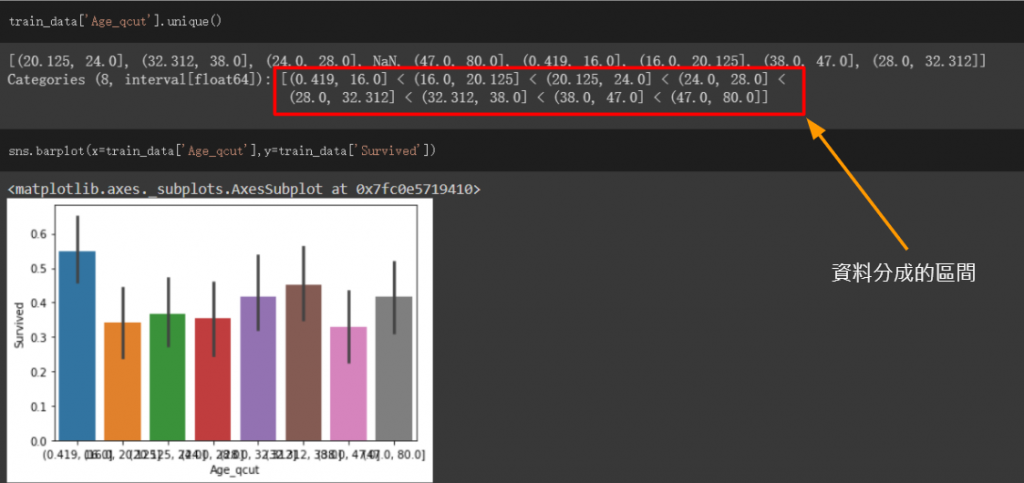
因为年龄为连续性的资料,我透过DataFrame的qcut方法来对资料进行分组
qcut第一个参数传入要进行动作的栏位,後面填入要分成几组,之後会根据资料的比例平均分组
例如:如果我填入4,资料就会分为0%~25%、25%~50%、50%~75%、75%~100%,而这边我分为8组
并将结果传入新的栏位,此栏位命名为Age_qcut

之後进行资料视觉化
可看出0~16的区间生存机率有比较高,而其他都还算平均
观察原资料分布情形
发现大部分资料大概都位於15到40之间,其他部分都还好
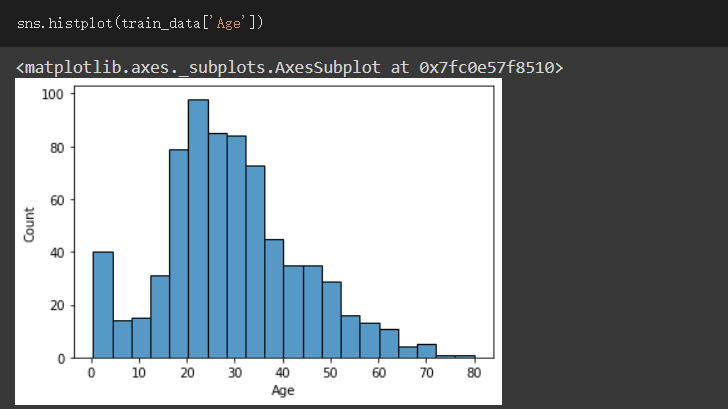
根据以上的观察
我将Age<=16的资料设为1
其他都设为2,表示空值也跟着被设为2,把空值也设为2是因为如果设成1会提高生存机率,但我们有不少的缺失值,怕把样补充会影响到资料的预测结果
为什麽我会这麽做呢?因为根据观察,小於等於16岁的生存率有比较高,且资料分部在那部分的数量也不会太少
所以把这当作一个特徵

今天先讲到这里,明天会把剩下的栏位讲完
这里先放上整个资料处理及训练过程
https://colab.research.google.com/drive/1l--rkdk0sCxrEAGyETSxFCMrJmS147tX?usp=sharing
>>: Day13.进入 ARM 世界: ARM Instruction Sets
.NET Core第3天_使用CLI来创建.NET Core专案_专案架构解析
预设不管是透过visual studio 或者额外下载安装完.NET Core SDK 我们能够利用...
007-小工具
今天分享一些实用的网站,应该大部分都知道,但一样是做个纪录。 1.https://www.nngro...
Google Script+LINE 打造聊天机器人 #1-工具介绍
专案简介 起源:方便自己与亲友查询汇率和日期,以及定时提醒汇率以利购买外汇。 功能:查询(1)即时汇...
Day30 赛後心得
在这30天的比赛中,不知不觉的到最後一天了,虽然中间发生了点小插曲导致没有成功,但我还是希望能照样将...
Day19 跟着官方文件学习Laravel-Coverage
今天要来看看 PHPUnit 提供 Coverage 的使用方法 我们可以利用 PHPunit 来测...