[神经机器翻译理论与实作] 这个翻译不大正经
前言
也许你会觉得,这个标题下得很神经。没错!因为今天要正式进入新的主题-神经机器翻译。我们今天将会从机器翻译这个课题出发,综览在自然语言处理的发展中机器翻译演算法的演进,最终深入现今主流的深度学习翻译架构。
什麽是机器翻译?
机器翻译( machine translation )就是演算法将一段文字讯息从来源语言( source language )转换为目标语言( target language )的过程,既保留语意又符合文法规则,长久以来一直都是自然语言处理中的热门研究议题。以处理方法来区分,伴随着自然语言处理的演进,机器翻译历经了四个重要时期,由早期到现代分别为: rule-based machine translation ⟶ example-based machine translation ⟶ statistical machine translation ⟶ neural machine translation ,分别由以下简述:
Rule-based Machine Translation (RBMT):1950年代至1980年代
最早期的处理手法须必须仰赖手刻来源语言和目标语言的单词对应辞典和语法规则。过程中会使用 rule-based 前处理方法如断词( tokenisation )、词性标注( POS tagging ),藉由部分语法分析( partial parsing ,详见本系列第七天关於语法分析的介绍)来确立两种语言的文法结构,以生成一段目标语言的句子。RBMT翻译系由层次低至高可分为 direct system ⟶ transfer system ⟶ interlingual system ,有兴趣的读者可参阅下方参考资料 [2]。另外,维基百科以英文翻译成德文为例解释了RBMT的一般处理流程,因此我们就不赘述。
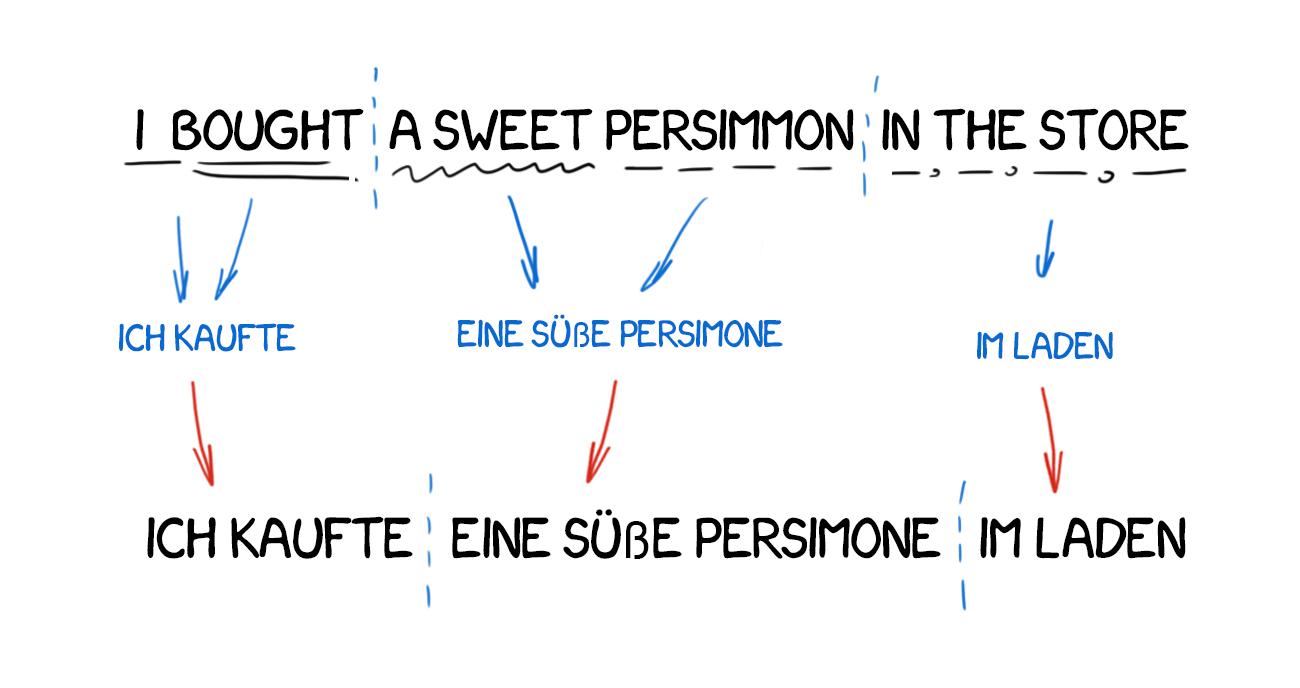
Transfer system以分析语块分析来对应片语:
Example-based Machine Translation (EBMT):1980年代至1990年代
上述的 rule-based 翻译系统适用於语言学分支、语序接近的两种语言,如英文⟷德文,但若要从英文翻译成日文就会碰上则制定文法规则与兼顾语意对应关系十分复杂的挑战。 EBMT 不需要手刻大量的文法规则,而是透过匹配双语平行文本( bilingual parallel corpus )中的例句来进行翻译。双语文本将来源语言与目标语言具有相同语意的例句一一对应并条列出来,每行成对的例句仅在绝对位置上有少数单词的差异。
双语文本中的平行例句对:

输入文句之後,系统会搜寻来源文句中与之最接近的例句,并在辞典中找寻缺失单词对应的单词,填入空缺来生成目标文句。
EBMT的翻译流程:

Statistical Machine Translation (SMT):1990年代至2010年代
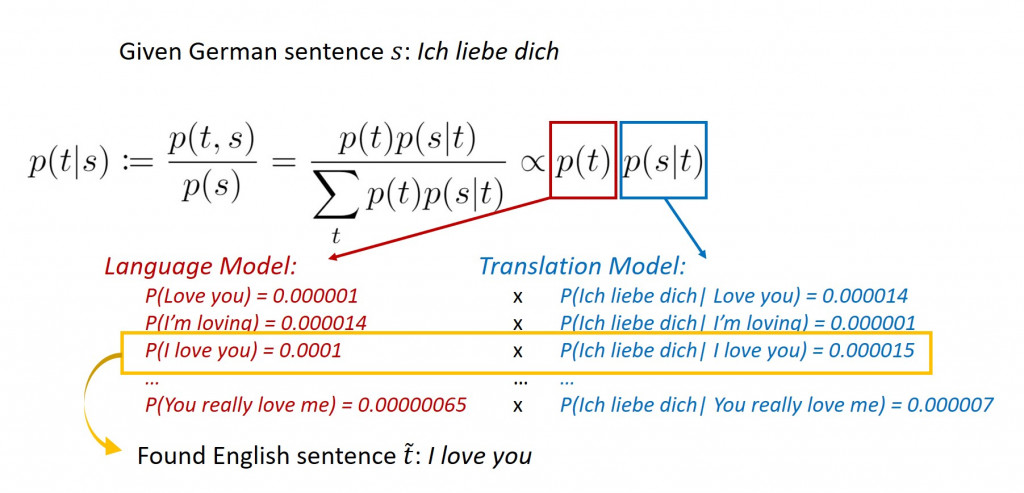
另一种翻译方式则是估计条件机率分布,其中 s 与 t 分别为双语平行文本中来源语言和目标语言的文句,并找出具有使得有最高机率值的语句
。
下图简单说明了 SMT 如何利用贝氏定理( Bayes theorem )将德文的「 Ich liebe dich 」(我爱你)翻译成英文:
Neural Machine Translation (NMT):2014年以降
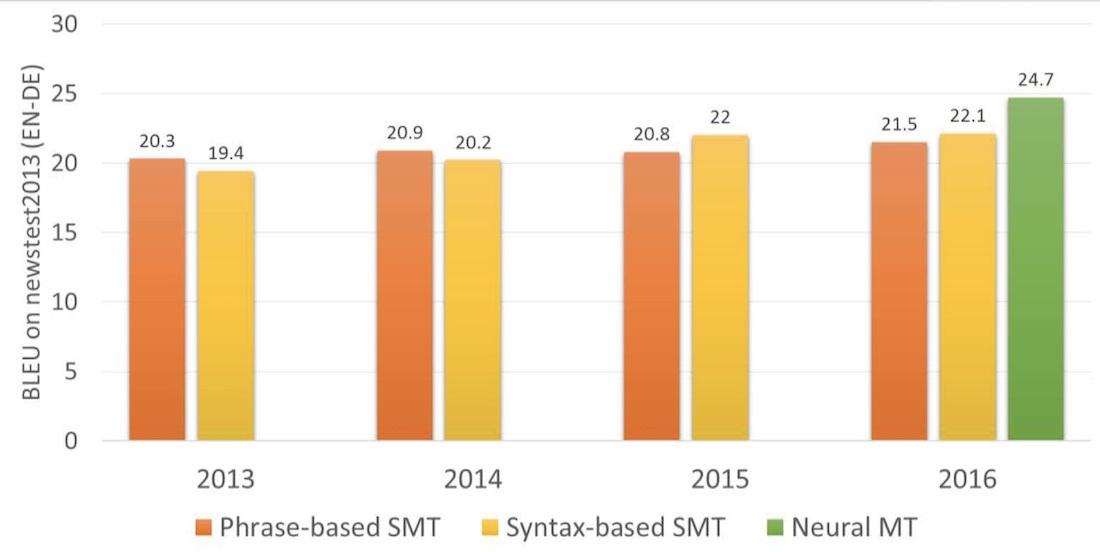
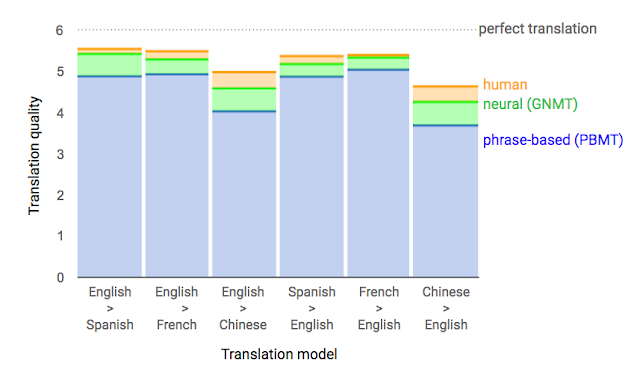
2014年 Google 团队首次发表论文将深度神经网络运用翻译任务上,使用了长短期记忆( long short-term memory, LSTM )将英文翻译成法文,开启了机器翻译的新纪元。由於文句本质上是单词与标点符号所构成的序列,翻译任务被看作是序列到序列的推论过程。神经网络架构的翻译器较先前提出的统计模型有较好的翻译表现( BLEU, bilingual evaluation understudy 是用来评估机器翻译品质好坏的指标),因此 NMT 成为了今日机器翻译领域的主流。
相对於SMT,NMT取得较高的 BLEU比分:
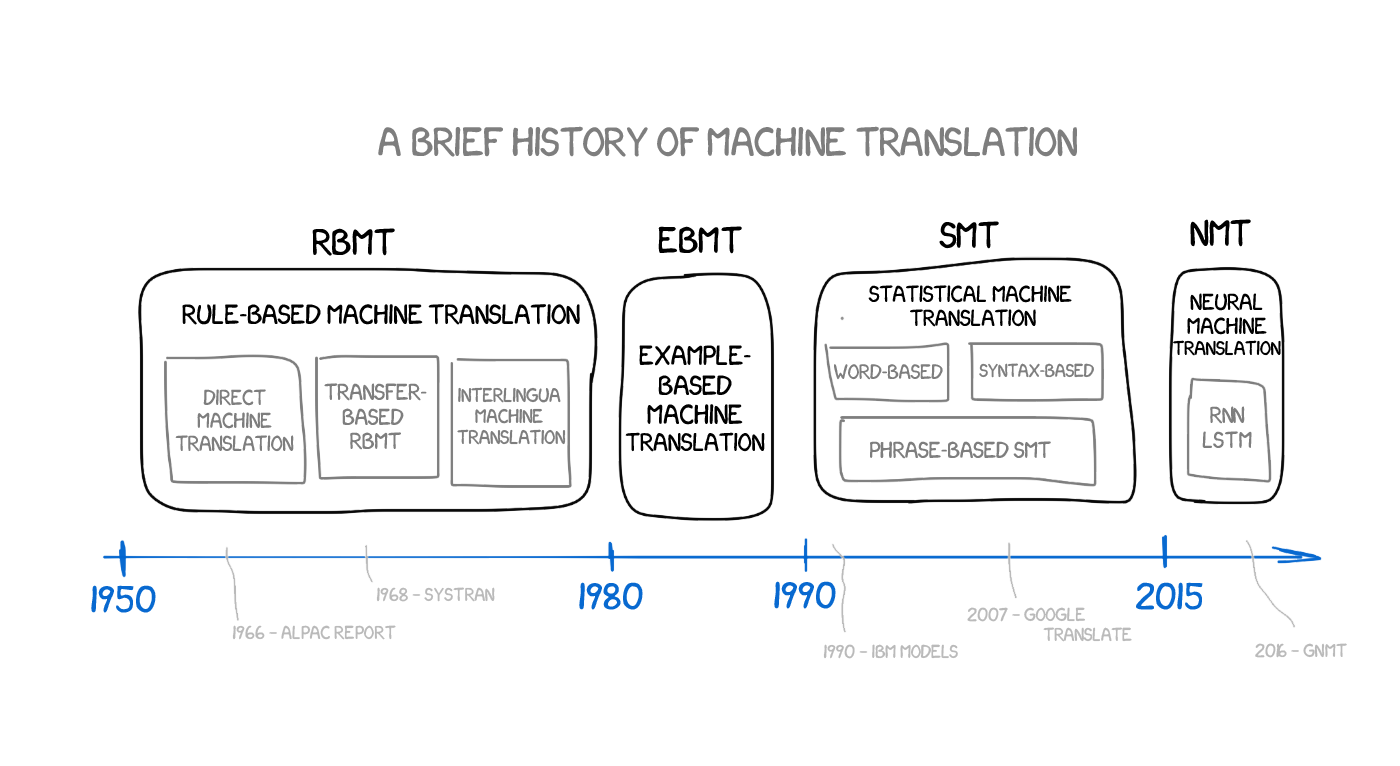
机器翻译发展的里程碑:
图片来源:translartisan.wordpress.com
神经机器翻译系统基本架构
一个神经机器翻译系统主要由编码器( encoder )与解码器( decoder )所组成。句子中的单词依序传入神经网络的神经元,先是分别在来源语言底下进行 word embedding 成为向量之後,传入由质神经网络构成的编码器进行编码。编码器内由数个记忆细胞所构成, word embedding 序列的前後依赖资讯被记录在记忆细胞中的内部状态( weight 与 bias 等参数)。编码过後的序列之後再传入解码器,解码器内部一样具有记忆细胞以纪录目标语言底下 word embedding 的次序性。差别在於当下经过预测得出的 word embedding 会作为输入值传入下一个记忆细胞。最後将依序输出的 目标语言 word embedding 还原成自然语言,完成向量序列到向量序列的翻译工作。
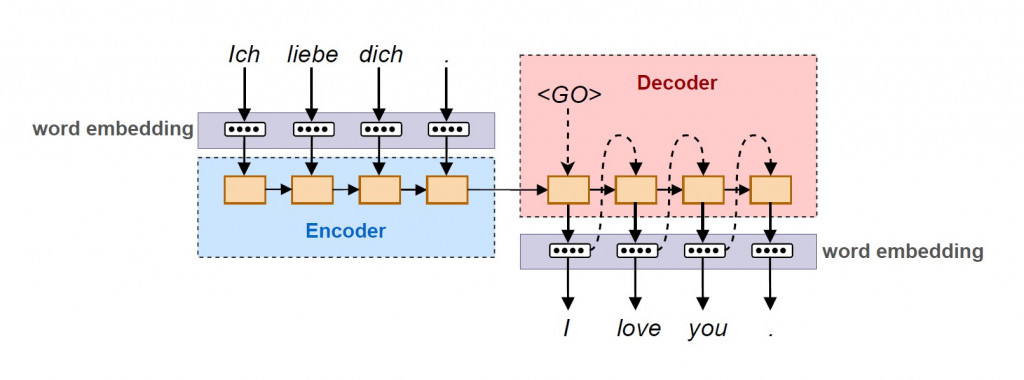
编码器可由单纯的 RNN 或其衍生模型 LSTM 、 GRU 等具有记忆性质的神经网络所构成。而 RNN 对於向量序列编码到单一向量时会出现问题,因此後期在编码器到解码器之间又出现了可以依照重要程度分派注意力的 attention 机制。
LSTM记忆细胞的设计架构:
图片来源:Designing neural network based decoders for surface codes

结语
今天我们快速浏览了各时期的翻译手法,最後驻足在以神经网络为基础的翻译模型,也是今日的主流。在 Google 将神经网络全面投入翻译系统之後,笔者亲自感受到其翻译品质的大幅提升,许多令人啼笑皆非的翻译结果都已成为过去式。
图片来源:Google AI Blog
最後补充一下,翻译的过程可分为前期的语言分析(包含了语法分析、型态分析和语意关联性分析等)与後期产生文句两阶段,因此明天我们将会花一些心思探讨文本生成( text generation ),它也是自然语言处理中的主要任务之一。今天的文章就写到这儿,明天继续!
阅读更多
- Rule-based Machine Translation
- Machine Translation. From the Cold War to Deep Learning.
- Introduction to Statistical MT (YouTube Video)
- BLEU | Wikipedia
<<: JavaScript入门 Day20_function介绍3
>>: [Day11] C#实作解密Response讯息内文(Message)
[Day14] THM Root Me
网址 : https://tryhackme.com/room/rrootme IP : 10.1...
Day13:SwiftUI—Navigation
前言 上篇文章介绍了 SwiftUI - List, 这篇来讲如何在一个 list 上导航到不同的 ...
SQL与NoSQL的连结(一)
对於资料库管理员而言, 另一项重要任务是异质平台之间的资料沟通. 接下来实作从SQL到NSQL的资料...
D28 - 压测
开始对TiDB进行测试,测试环境如下: 服务 vcpu ram 数量 TIDB/PD 8 20G 3...
DAY4 Kubernetes丛集资源监-Prometheus 前言
2021 IT铁人赛 DAY4 在昨天我们已经将kubernetes安装好,也建立了一个自己的丛集,...