Day12 - 辨识模型 part1
完成了第一阶段的除噪模型之後,接下来要进入辨识阶段,利用乾净状态资料和降噪後的含有噪音的训练资料来训练两个语音辨识模型,分别是传统的HMM-GMM 模型以及CTC 模型,完成训练後将同样经过降噪後的测试资料集送入模型辨识得到最终的结果。
HMM-GMM 模型的部分我们会使用在Day07时提过的 HTK 工具。在声学模型(AM)会以全词模型(whole word model)为单位,除了数字0有两个全词模型,其他数字都会有各自的全词模型。每个全词模型有16个状态(state),每一个状态有3个高斯混合模型(GMM)。整个模型是一个由左到右的模型,不会跳过任何的状态。除了全词模型之外, 还有两个暂停模型,第一种是静音模型(silence model),包含3个可转移状态(图 1), 每一个状态是由6个高斯混合模型构成;第二种模型是短暂停顿模型(short-pause model),只包含一个状态且此状态和静音模型中间的状态共用。
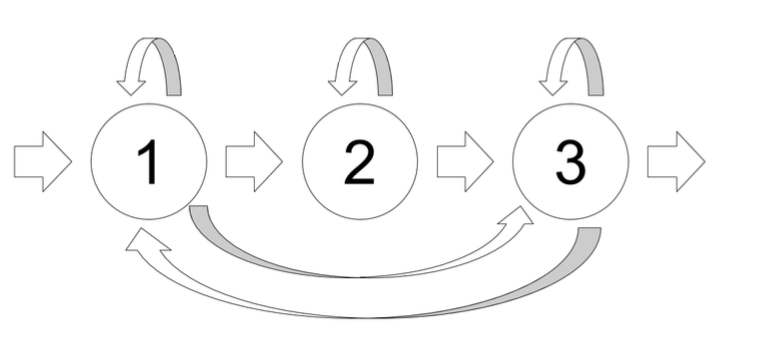
图 1: 静音模型中的3个可转移状态
在第二个模型中我们会使用递回神经网路(recurrent neural network, RNN)的架构并透过 CTC 进行训练。和除噪模型使用的全连接网路不同,RNN 会将前一个时间点的输出传递给下一个时间点,让「过去」的讯息能够被保留,使得神经网路具有记忆性。除了基本的 RNN 之外,为了让网路能够有长期的记忆性,研究学者後来提出了长短期记忆模型(Long Short-Term Memory, LSTM),和一般的RNN不同在於增加了3个闸门(gate):输入门(input gate)、遗忘门(forget gate)和输出门(output gate),输入门控制目前的输入是否进入,遗忘门控制过去的资讯是否保留,输出门控制目前的状态是否输出,透过这3个门对资料的控制,得以让 LSTM 有长期记忆的特性。
CTC 模型架构如图 2。输入是39维特徵,接着是3层的隐藏层,每一层都是双向的LSTM,每个方向的LSTM都有133个unit,3层的大小皆相同;在隐藏层内的连接方面,每一层中两个方向的输出以相加的结果作为下一层的输入。最後是输出层,一层含有14个神经元的全连接层,原因是实验使用的是全词当作输出结果,包含one, two, ..., nine, zero, oh, sp, sil 以及 CTC 会使用的 blank,一共14个。输出经过 CTC 计算後得到一个序列(sequence),这个序列就是 end-to-end 系统的预测结果。在训练 CTC 模型的超参数设定如下:
- learning rate: 0.001
- optimizer: Adam
- mini-batch size: 40
- epoch: clearn: 5 , noise: 10
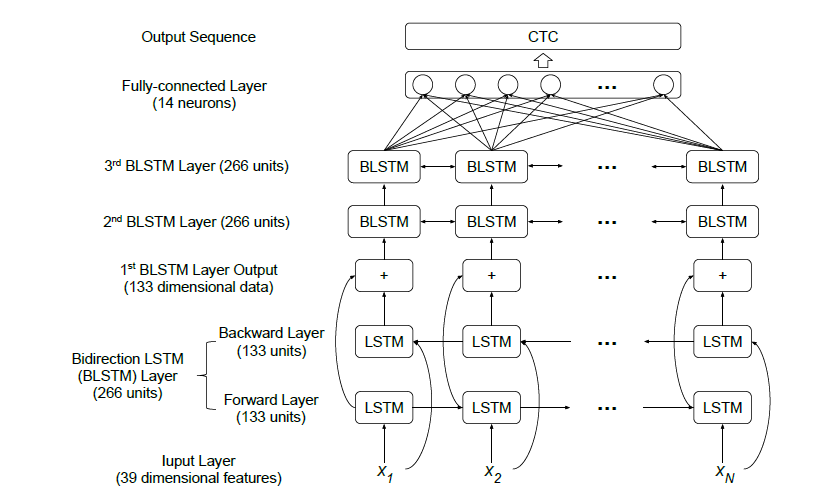
图 2: CTC 模型架构图,输入是39维的语音特徵,有3层双向 LSTM 及1层全连接层
明天将继续介绍程序实作的部分。
<<: <Day9> Contract — 取得期货(Futures)资讯
>>: 【Day 09】- 大家都爱的 BeautifulSoup
[Day 5] Course 1_Foundation - 资料分析工具及职涯探索
《30天带你上完 Google Data Analytics Certificate 课程》系列将...
Day05:Set Chat Page(设定聊天页) II
全文同步於个人 Docusaurus Blog 在本章中,要达成两个目标: 使用 JS 来动态 r...
[iT铁人赛Day14]JAVA回圈的跳离范例
上次讲完回圈的跳离,今天要用一些范例来做说明 break叙述的范例程序码如下: import jav...
Day25 NodeJS中的前端框架 I
在开发网站系统时,使用前端框架可以让资料更容易在介面中被使用、也可以建立模组化的介面,可以更有效的提...
创作App-Xcode资料库
有了基础的注册系统後,建立资料库来连接系统,用於储存用户、使用者的帐号与密码、等级等,区分版本功能。...