[Day 12] 决策树 (Decision tree)
决策树 (Decision tree)
今日学习目标
- 决策树演算法介绍
- 决策树如何生成?
- 如何处理分类问题?
- 如何处理回归问题?
- 实作决策树分类器
- 观察决策树是如何生成的。
- 实作决策树回归器
- 查看决策树方法在简单线性回归和非线性回归表现。
决策树
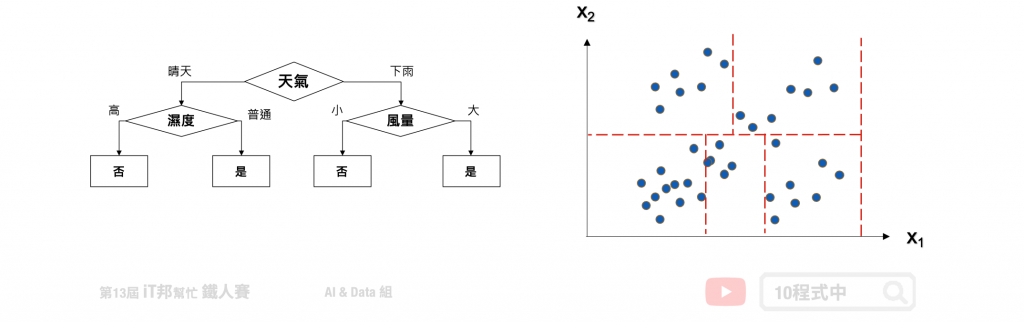
决策树会根据训练资料产生一棵树,依据训练出来的规则来对新样本进行预测。决策树演算法可以使用不同的方式来评估分枝的好坏(乱度),例如像是 Information gain、Gain ratio、Gini index。依据训练资料找出合适的规则,最终生成一个规则树来决策所有事情,其目的使每一个决策能够使讯息增益最大化。就好比我们评估今天比赛是否举行,天气因子可能站比较大的因素,而 Co2 的浓度高低可能站的因子程度较低。因此在第一层的决策中以天气的特徵先进行第一次的决策判断。接着第二层再从所有特徵中寻找最适合的决策因子,直到设定的最大树的深度即停止树的生长。
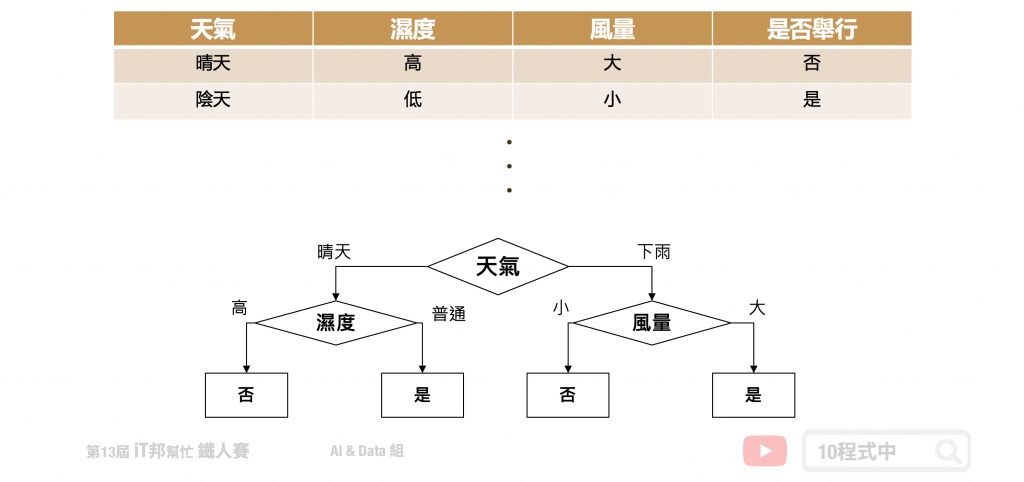
决策树如何生成?
决策树是以一个贪婪法则来决定每一层要问什麽问题,目标是分类过後每一群能够很明显的知道是属於哪一种类别。延续上面的例子,以分类问题来说假设要评估明天比赛是否举行。在树的第一层节点中我们要从已知的两个特徵分别是温度与特徵选一个作为该层的决策因子。假设目前训练集有五笔资料,其中正常举行的有後笔资料,取消举行的有三笔资料。在树的结构中左子树为决策正常取行,而右子树是决策取消举行。我们可以发现当特徵为天气的时候可以一很清楚的将这两类别完整分开,因此我们会将天气作为这一层判断的因子。这就是决策树在生成中的贪婪机制。然而要如何去判断每次决策的好坏,就必须依靠乱度的评估指标。
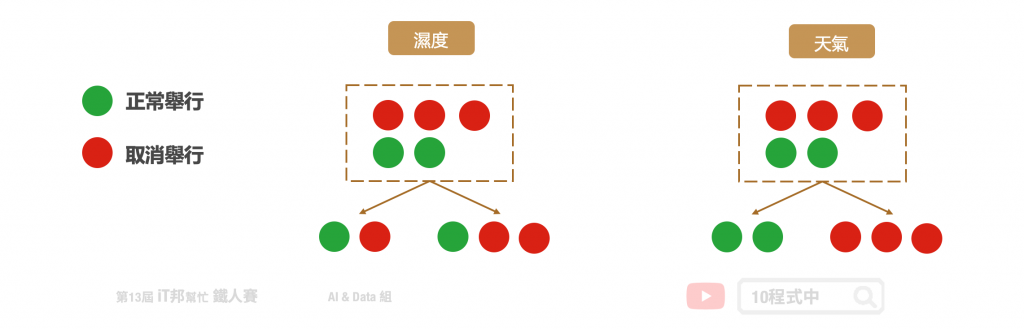
决策树的混乱评估指标
我们需要客观的标准来决定决策树的每个分支,因此我们需要有一个评断的指标来协助我们决策。决策树演算法可以使用不同的指标来评估分枝的好坏,常见的决策乱度评估指标有 Information gain、Gain ratio、Gini index。我们目标是从训练资料中找出一套决策规则,让每一个决策能够使讯息增益最大化。以上的指标都是在衡量一个序列中的混乱程度,其数值越高代表越混乱。然而在 Sklearn 套件中预设使用 Gini。
- Information gain (资讯获利)
- Gain ratio (吉尼获利)
- Gini index (吉尼系数) = Gini Impurity (吉尼不纯度)
评估分割资讯量
Information Gain 透过从训练资料找出规则,让每一个决策能够使讯息增益最大化。其算法主要是计算熵,因此经由决策树分割後的资讯量要越小越好。而 Gini 的数值越大代表序列中的资料乱,数值皆为 0~1 之间,其中 0 代表该特徵在序列中是完美的分类。常见的资讯量评估方法有两种:资讯获利 (Information Gain) 以及 Gini 不纯度 (Gini Impurity)。
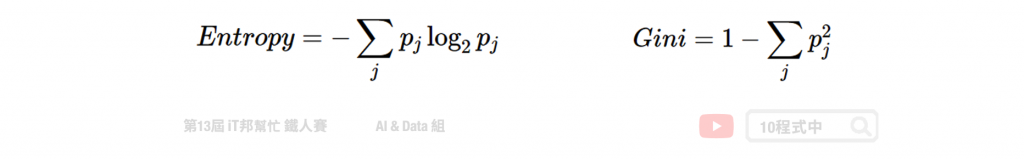
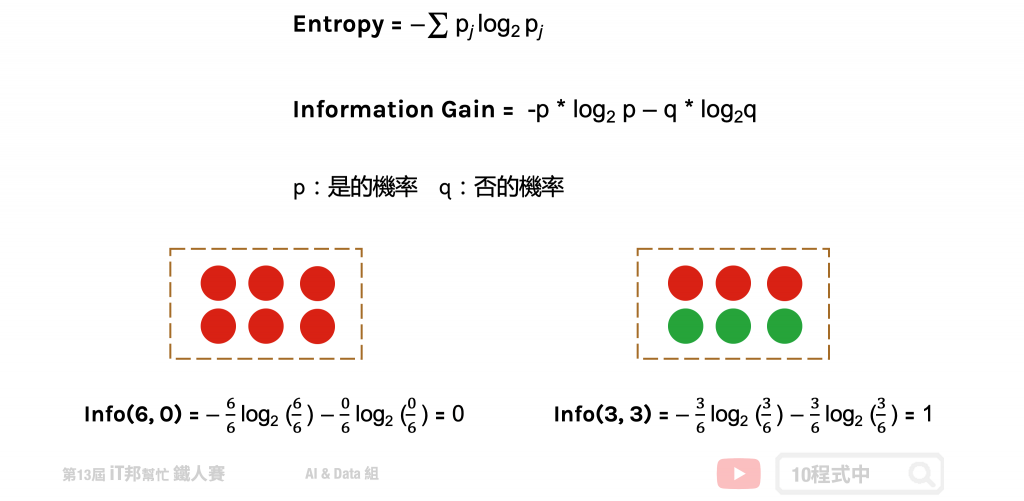
熵 (Entropy)
熵 (Entropy) 是计算 Information Gain 的一种方法。在了解 Information Gain 之前要先了解熵是如何被计算出来的。其中在下图公式中 p 代表是的机率、q 代表否的机率。我们可以从图中范例很清楚地知道当所有的资料都被分类一致的时候 Entropy 即为 0,当资料各有一半不同时 Entropy 即为 1。
Gini 不纯度 (Gini Impurity)
Gini 不纯度是另一种乱度的衡量方式,它的数字越大代表序列中的资料越混乱。公式如下所示,其中 p 代表是的机率、q 为代表的机率。我们可以从图中范例很清楚地知道当所有的资料都被分类一致的时候混乱程度即为 0,当资料各有一半不同时混乱程度即为 0.5。

回归树
决策树回归方法与分类有点类似差别仅在於评估分枝好坏的方式不同,我们又可以称作回归树。当数据集的输出爲连续性数值时,该树算法就是一个回归树。透过树的展开,并用叶节点的均值作爲预测值。从根节点开始,对样本的某一特徵进行测试。经过评估後,将样本分配到其子结点。此时每一个子节点对应着该特徵的一个值。依照这样方式进行,直至到达叶结点。此时误差值要最小化,并且越接近零越好。
回归树的生长过程很推荐看这篇文章
以下举一个例子假设 x 是输入 y 是输出,我们可以在一个平面上绘制出资料与正确答案间的分布。假设回归树的最大深度设定两层。首先在第一层中会将所有的资料从中间切一刀此断点为 x=0.496 当大於设定的值的数据点会继续往右子树下去延伸,反之小於 0.496 的资料点会往左子树走。此时将会切出一个分支出来并往下扩展并形成第二层的决策分支。一直不断持续拓展直到设定的最大深度终止,此时的节点即为叶节点也就是最终的模型输出值。
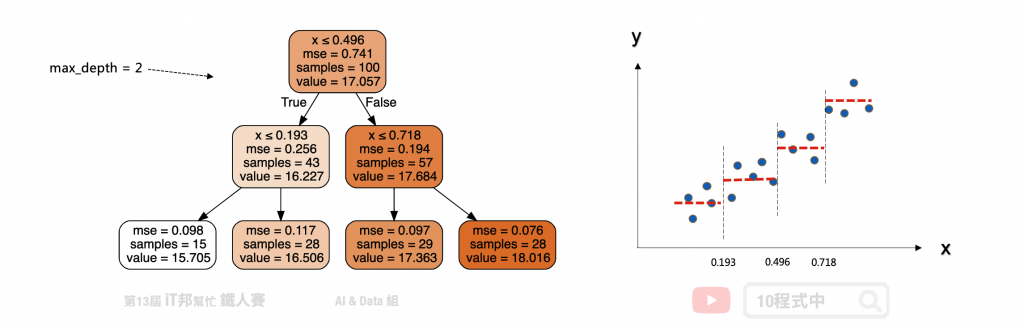
树越深模型越复杂
假设我们生成一个 f(x) = 3x+15 + noise 的资料,其中 noise 为一个 0~1 之间的随机数。从以下的测试可以看出随着决策树深度的增加,决策树的拟合能力不断上升。决策树已经不仅仅拟合了我们的线性函式 3x+15,同时也拟合了我们添加的噪音(noise)。
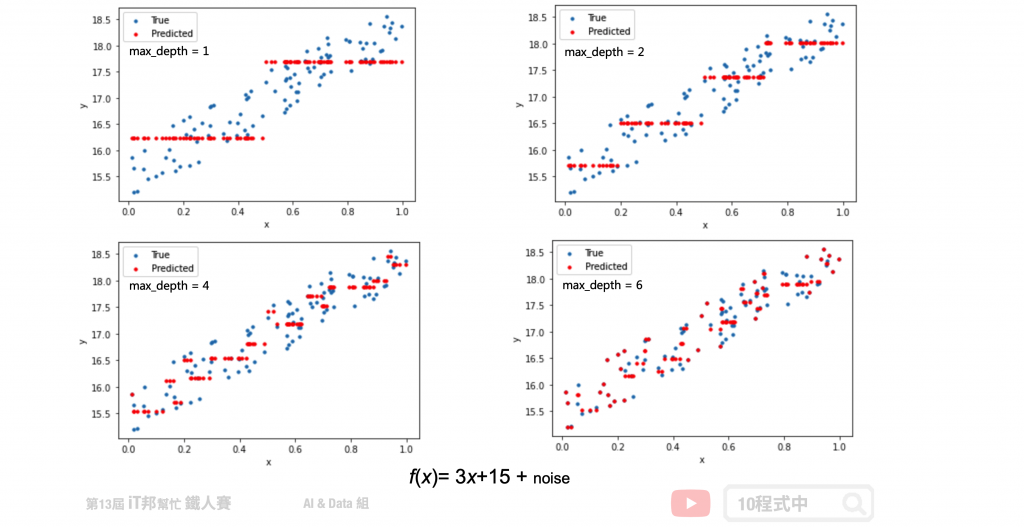
回归树该如何选择切割点?
在分类模型中决策树是以乱度作为决策树生成时候的评估指标。但是回归树透过是 MSE 或 MAE 来评估模型,并找出误差最小的值作为树的特徵选择与切割点。其中前者是均方差,後者是和均值之差的绝对值之和。

CART 决策树
在 Sklearn 套件中决策树演算法是采用 CART (Classification and Regression Tree) 演算法,并且可以被拿来做分类和回归的预测。在决策树的每一个节点上都是采用二分法,也就是每一个决策节点只分枝出两个子节点。并且不断地往下拓展,直到设定的最大深度为止,此时最大深度的节点称为叶节点即为模型的预测输出。
决策树模型的优缺点
建立决策树的过程就是不断的寻找特徵进行决策,透过这些决策尽量的使这些资料被分为同一个类别,且试着让混乱程度越小越好。切记树的深度越深不一定越好,他可能会造成过度拟合的问题。训练好的模型我们能够视觉化决策树的结构,相对的可解释性就变高。此外与其它的ML模型比较起来,决策树执行速度是它的一大优势。因为是树状结构,因此在进行机器学习的时候每个决策阶段都相当的明确清楚,不是 0 就是 1。

决策树总结
决策树透过所有特徵与对应的值将资料切分,来找出最适合的分枝并继续往下拓展。若决策树深度越深则决策的规则将越复杂,模型预测也会越接近真实答案。但若训练集中含有过多的杂讯,太深的树就有可能产生过拟合的情形。因此单一的决策树肯定是不够用的,我们可以利用集成学习中的 Boosting 架构,对回归树进行改良升级。

[程序实作]
分类决策树
一个决策树会根据训练资料自动产生一棵树。决策树会根据资料产生很多树状的规则,最终训练出来的规则会对新样本进行预测。
Parameters:
- criterion: 乱度的评估标准,gini/entropy。预设为gini。
- max_depth: 树的最大深度。
- splitter: 特徵划分点选择标准,best/random。预设为best。
- random_state: 乱数种子,确保每次训练结果都一样,splitter=random 才有用。
- min_samples_split: 至少有多少资料才能再分
- min_samples_leaf: 分完至少有多少资料才能分
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
- get_depth: 取得树的深度。
from sklearn.tree import DecisionTreeClassifier
# 建立 DecisionTreeClassifier 模型
decisionTreeModel = DecisionTreeClassifier(criterion = 'entropy', max_depth=6, random_state=42)
# 使用训练资料训练模型
decisionTreeModel.fit(train_reduced, y_train)
# 使用训练资料预测分类
predicted = decisionTreeModel.predict(train_reduced)
# 计算准确率
accuracy = decisionTreeModel.score(train_reduced, y_train)
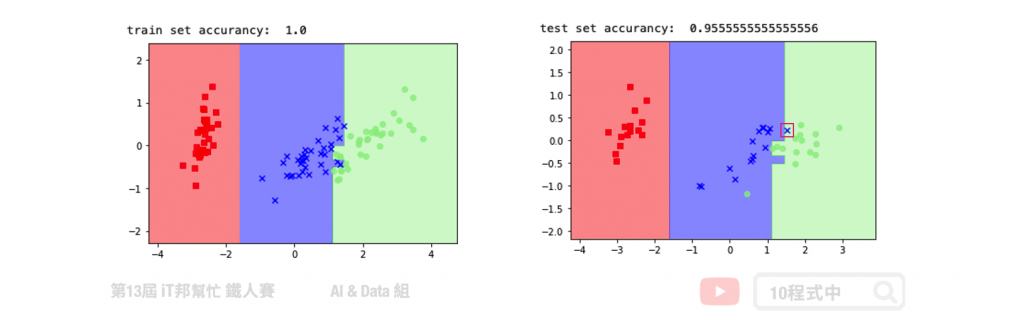
我们透过鸢尾花朵资料集进行 PCA 降维并训练一个决策树模型。透过绘制训练决策边界可以看到,在下图右手边的训练集完整地将三个类别切割开来。而在右边的测试集中仅有一笔红色框起来的资料预测错误。
回归决策树
Parameters:
- criterion: 评估切割点指标,mse/friedman_mse/mae。
- max_depth: 树的最大深度。
- splitter: 特徵划分点选择标准,best/random。预设为best。
- random_state: 乱数种子,确保每次训练结果都一样,splitter=random 才有用。
- min_samples_split: 至少有多少资料才能再分
- min_samples_leaf: 分完至少有多少资料才能分
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- get_depth: 取得树的深度。
from sklearn.tree import DecisionTreeRegressor
# 建立 DecisionTreeRegressor 模型
decisionTreeModel = DecisionTreeRegressor(criterion = 'mse', max_depth=4, splitter='best', random_state=42)
# 使用训练资料训练模型
decisionTreeModel.fit(x, y)
# 使用训练资料预测
predicted=decisionTreeModel.predict(x)
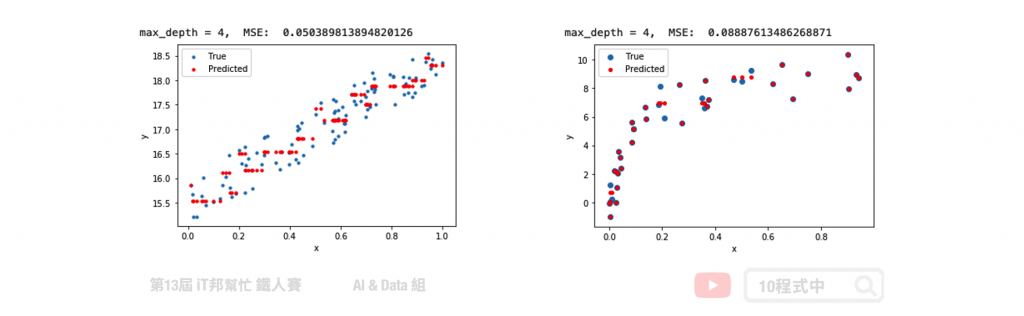
在回归决策树中我们使用了简单线性回归与非线性回归两种资料集进行数据拟合实验。在简单线性回归中我们将数据点添加一些噪音让资料分布在斜直线上。左图是回归树在最大深度为 4 的训练结果,可以隐约地看到模型决策的方式呈现阶梯状态。如果我们尝试的将数的深度增加,模型相对复杂因此可以拟合得更好。而右边是透过随机产生的非线性资料进行模型训练。从训练结果可以发现在最大深度为 4 的时候,训练结果就还不错了。大家可以试看看调整模型的树最大深度以及其他的超参数对模型训练结果的影响。
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: [铁人赛 Day09] React Context(上)-单纯的用法
出生第48天 铁人完赛日
请不要在意我标题出生日期一直跳,育儿的日子没那麽多废文可以写XD~而且中间很多天在干嘛其实也忘了囧...
画一个三角形(下)
大家好,我是西瓜,你现在看到的是 2021 iThome 铁人赛『如何在网页中绘制 3D 场景?从 ...
第30天~TTS(文字转语音)+STT(语音转文字)
TTS(文字转语音) 开新档案 布置XML档- 按钮也是要绑onClick- 步骤: 1.先宣告 2...
DAY 4:Guarded Suspension Pattern,你不会死的,因为我会保护你
什麽是 Guarded Suspension Pattern? 如果 thread 执行时条件不符,...
[30天 Vue学好学满 DAY7] 监听器(Watch)
Watch 监听器 具比较传(old & new) 无回传值(return) 监听变数发生异...