AI ninja project [day 24] 决策树森林 --排名资料
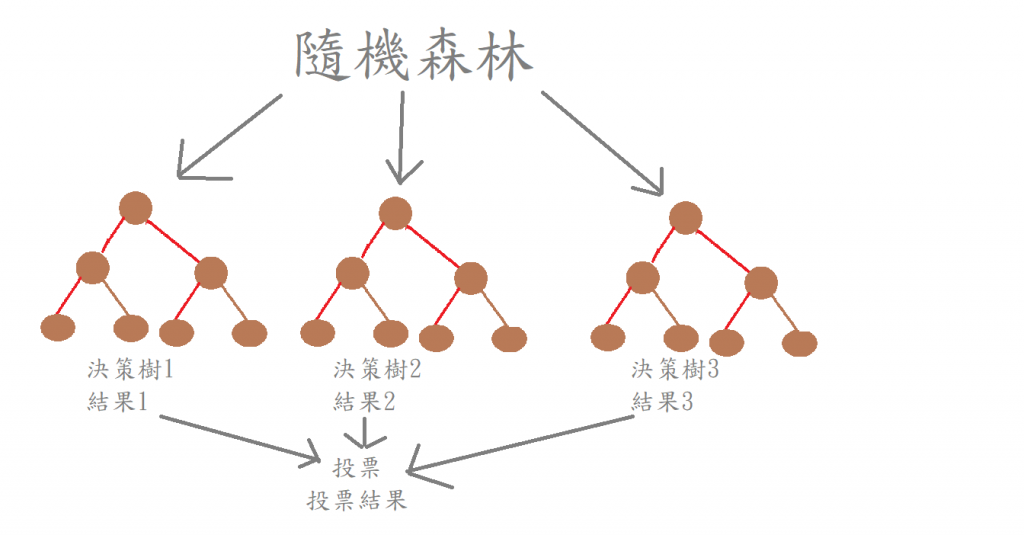
随机决策树为随机生成许多决策树,
利用取袋法来取出选中的决策树,
而每棵树的都具有执行结果,
每棵树依据执行结果来投票,
得票最高的就是最终输出结果。
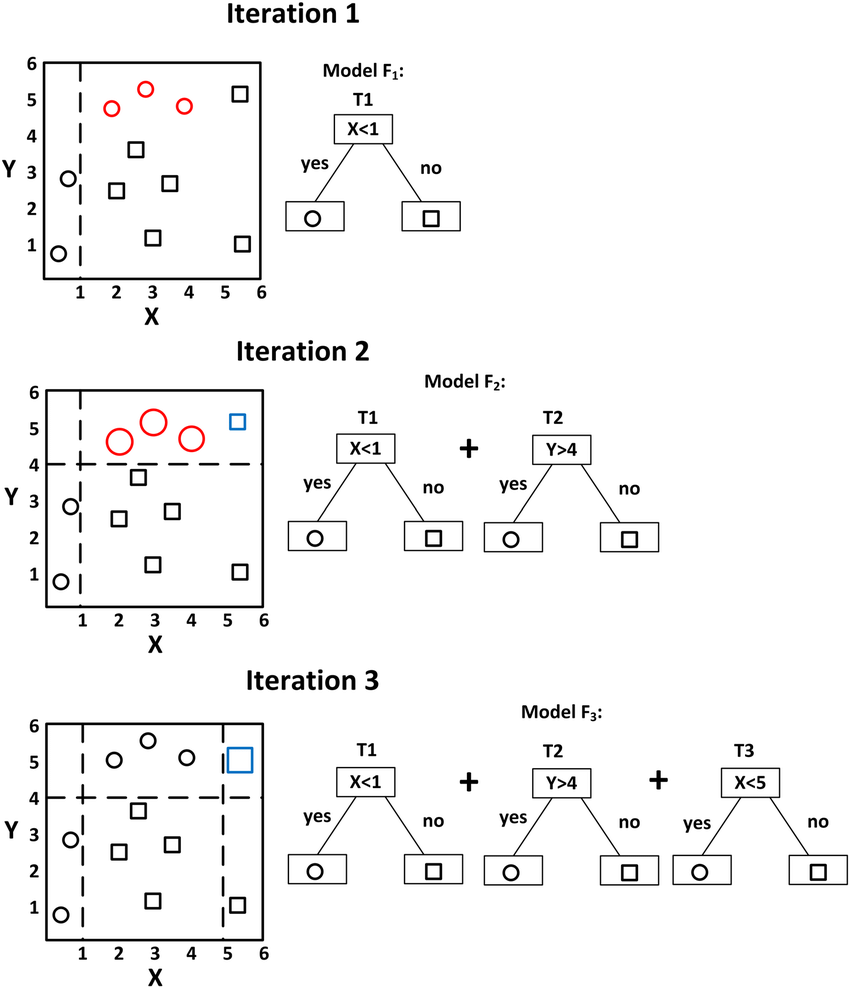
而本篇使用的是Gradient Boosting,
利用上一颗树的执行结果,
将错误划分的个体资讯加以优化,
加强划分的边界。
可以搜寻 Gradient Boosted进行参考。
决策树森林可以解决分类、回归及排名的问题,
今天来介绍解决排名的使用方式。
参考攻略colab:
https://www.tensorflow.org/decision_forests/tutorials/beginner_colab
colab中上部分有分类及回归的使用方法,
而我们从训练排名模型的章节开始:
安装套件

wurlitzer是帮助把训练时的日志资讯详细的印出,
自己创建模型时,不一定需要这个功能:

载入套件
下载排名资料的LETOR3资料集
进行清洗并查看资料结构:
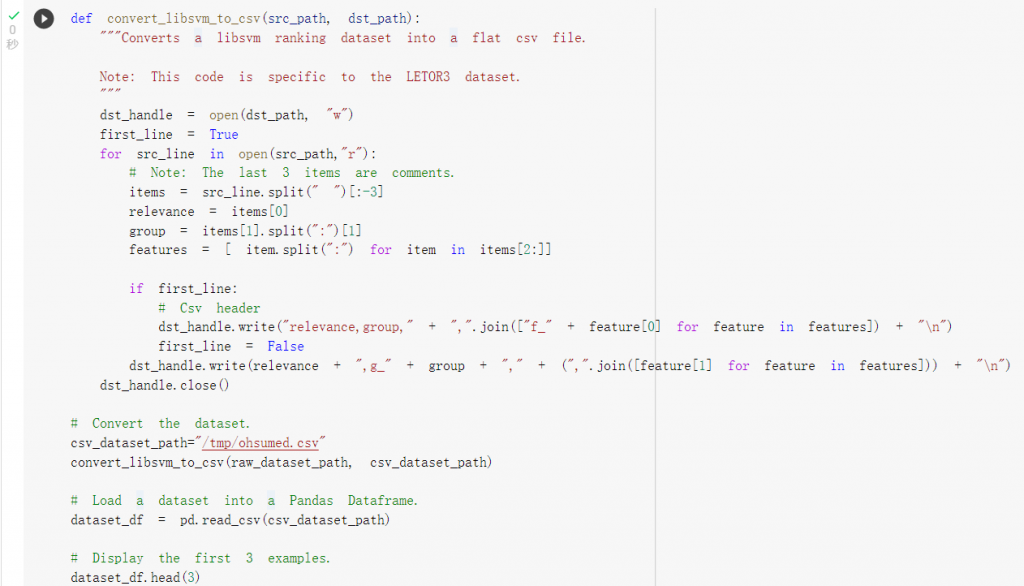
可以发现relevance为标签(label),
0代表越不相关或是越不重要,
而数字越大代表越相关或是重要。

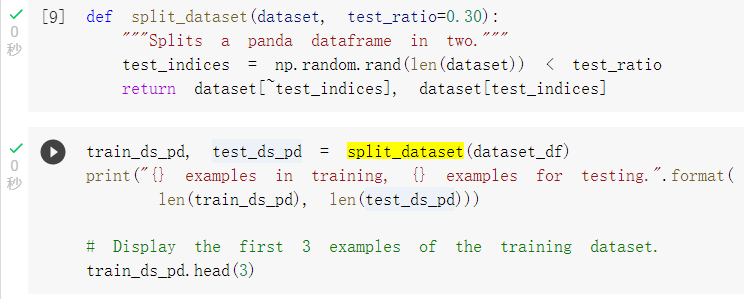
切分训练集及测试集:
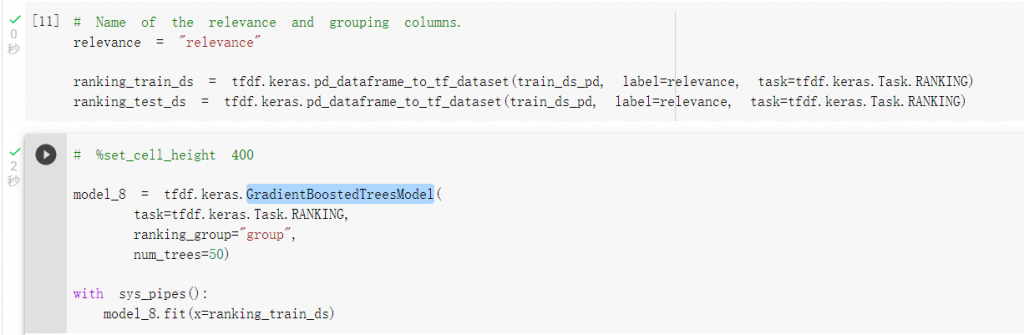
载入决策树资料集并且进行训练:
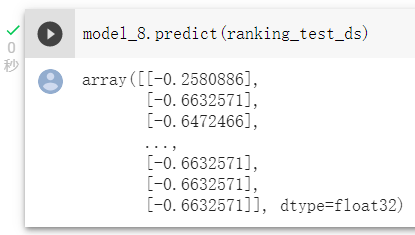
那最後我们可以对照预测结果来划分阶级:

撰写API端的第一个Flask API-以tick为例
上上篇已经写了一个Flask API的Hello World, 现在我们的Flask API要开始串...
Day11 配对品质评估 Evaluator
由於 Open-Match 在架构上,允许使用同一张 ticket,对不同的配对池进行搜寻与配对,这...
Postman pre-request script & tests
本质上是一样的东西,只是一个是在 request 前执行、一个是在收到 response 後执行,分...
[13th][Day8] docker image
回顾一下如何建立一个 基本的 container docker run -it --name eri...
新新新手阅读 Angular 文件 - Component - Day21
本文内容 阅读官方文件 Angular Components Overview 的笔记内容。 Com...