Day 38 - 在 AWS Lambda 中使用 YOLO 推估 (Inference)
Day 38 - 在 AWS Lambda 中使用 YOLO 推估 (Inference)
在 Day 15 - 说明 YOLO 相关设定 以及 Day 16 - 进行影像辨识训练完成了 YOLO 自订资料集的训练,在 Day 34 - 实作 S3 驱动 Lambda 函数进行 Yolo 物件辨识 与 Day 36 - 使用 Container 建立 Amazon SageMaker 端点 分别用不同的方法来进行 YOLO 推估的任务。
彼此之间的关系如下图所示,使用者透过 API Gateway 上传 (PUT) 图片到 储存贮体 A,这个事件会驱动 AWS Lambda 函数,此时,AWS Lambda 函数 会根据事先训练好的 YOLO 模型,对於该图片进行 YOLO 推估 (Inference),接着以 IAM 角色 B 的身分,将侦测到物件画出方块框後,存到 储存贮体 B,而使用者就可以看到处理後的结果。
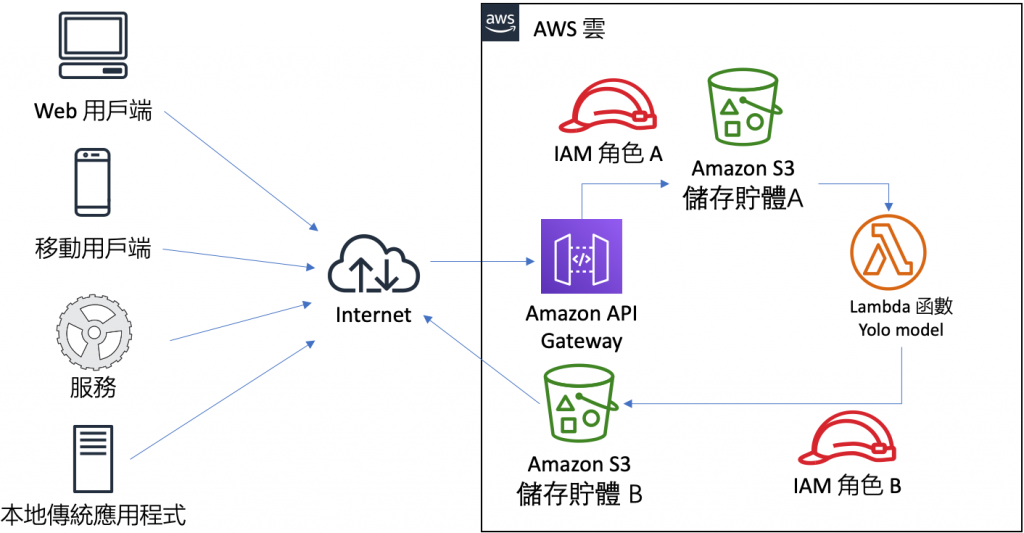
图 1、S3 驱动 Lambda 函数进行 YOLO 辨识架构图
Simple Inference Scripts for YOLO with OpenCV 这份专案中提供了一个使用 OpenCV 来进行 YOLO 推论的案例,现在我们就试着将这个案例布署到 AWS Lambda 进行测试,需要的前期准备工作如下:
- 上传 YOLO 相关档案到 S3: 训练好的权重档 (yolov3.backup) 以及待推论的图片 (02-frame-608x608-0090.jpg)
- 建立 IAM 角色,允许执行 AWS Lambda,并有存取 S3 的许可。
- 建立 AWS Lambda 函数,并设定环境变数。
- 在 AWS Lambda 建立 OpenCV 层
- 撰写 AWS Lambda 函数并完成测试
步骤 1. 上传 YOLO 相关档案到 S3
因为 AWS Lambda 函数的大小限制为 256 MB,所以需要把 YOLO 的权重档 (yolov3.backup) 以及待推论的图片 (02-frame-608x608-0090.jpg) 存到 S3 中,如下图所示。
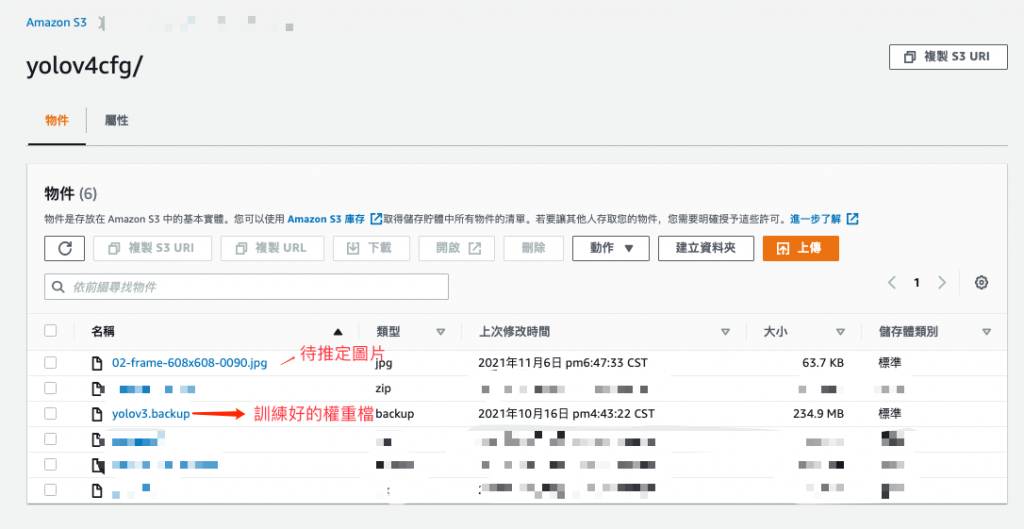
图 2、上传 YOLO 相关档案到 S3
步骤 2. 建立 IAM 角色
建立一个 IAM 角色,允许执行 AWS Lambda,并有存取 S3 的许可。进入 IAM 管理控制台,选择新增角色,接下来如下图所示,选择 Lambda 的使用案例後点击 下一个:许可 按钮。
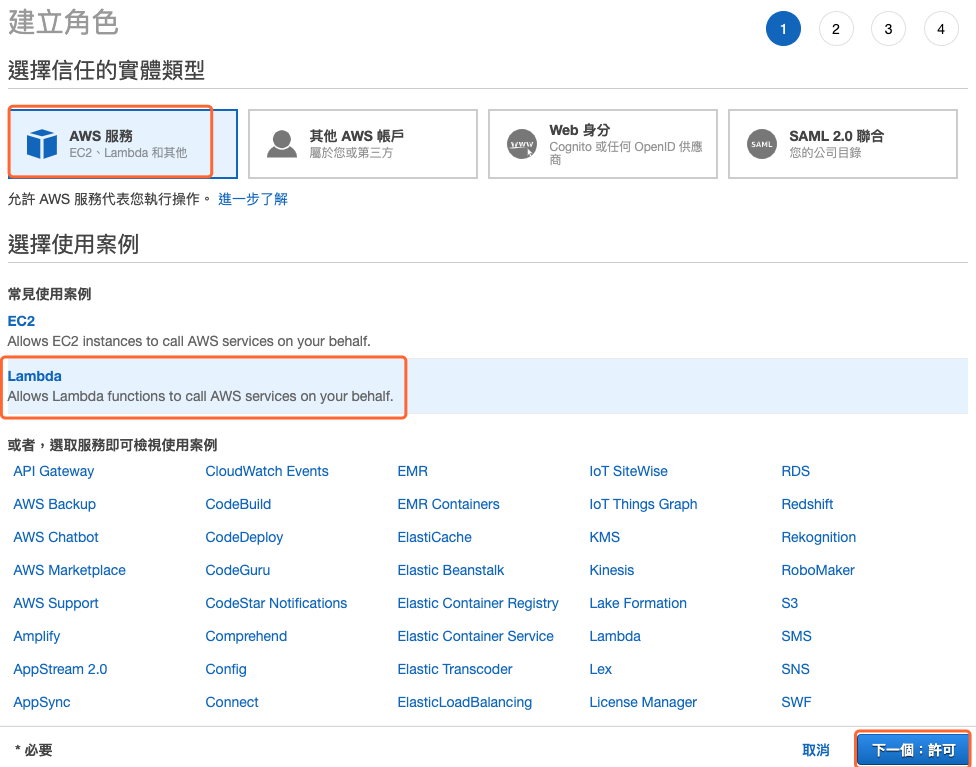
图 3、建立一个角色选择 Lambda 的使用案例
在搜寻文字框中输入 basic 找到 AWSLambdaBasicExecutionRole 进行连接,这将允许这个角色有写入 CloudWatch 记录档的全县,方便程序除错之用,如下图所示。
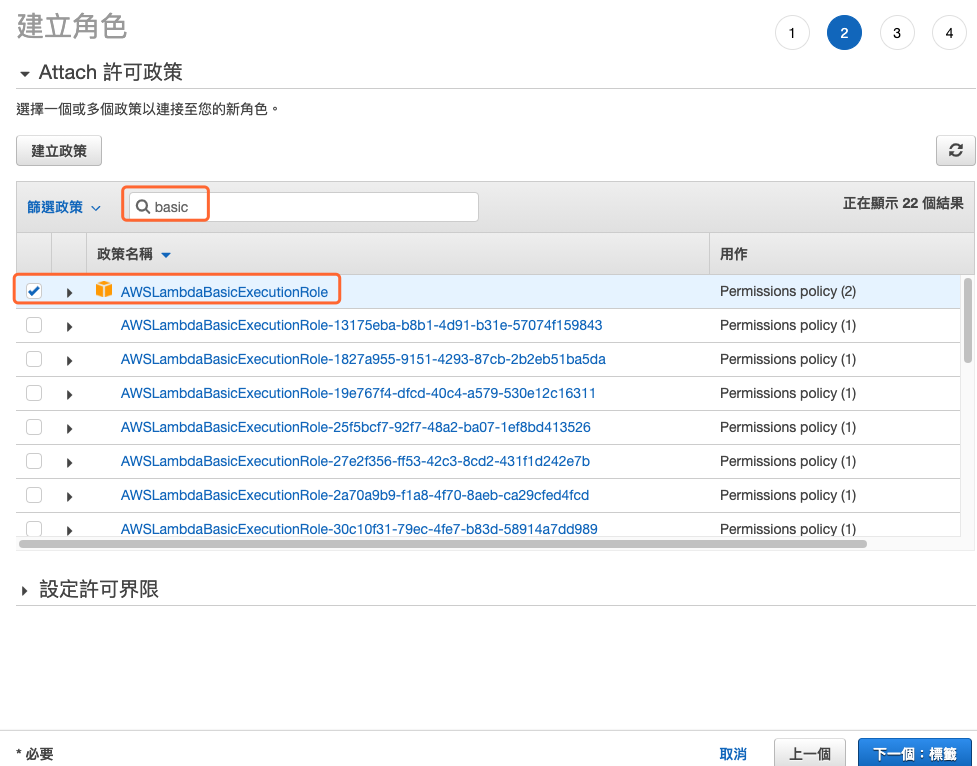
图 4、连接基础的 CloudWatch 除错用的许可政策
最後确定先前的设定後并输入角色名称後,就可以建立角色,如下图所示。
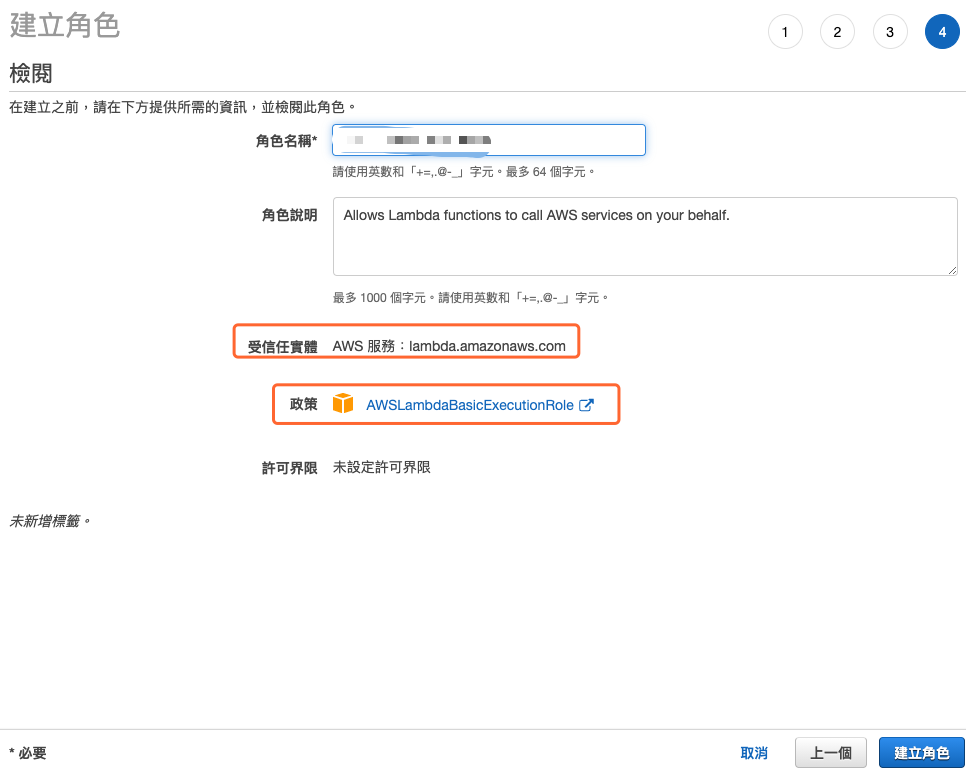
图 5、检阅设定并建立角色
编辑一个新的政策,内容如下图所示,给定读取 (GetObject) 储存贮体 A 与写入物件 (PutObject) 与权限 (PutObjectAcl) 到储存贮体 B。
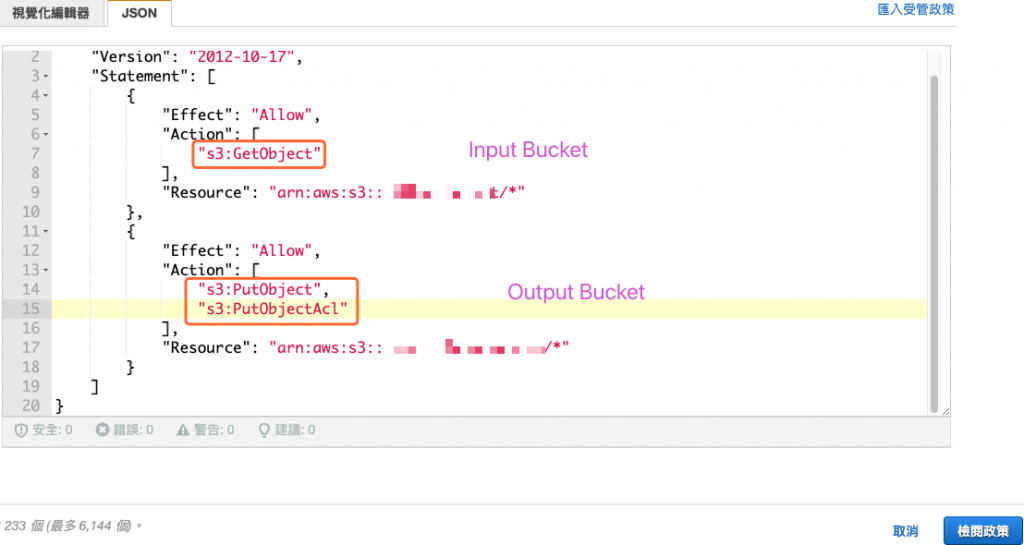
图 6、新增政策
接着到角色设定画面,将新建政策连接到角色上,如下图所示。
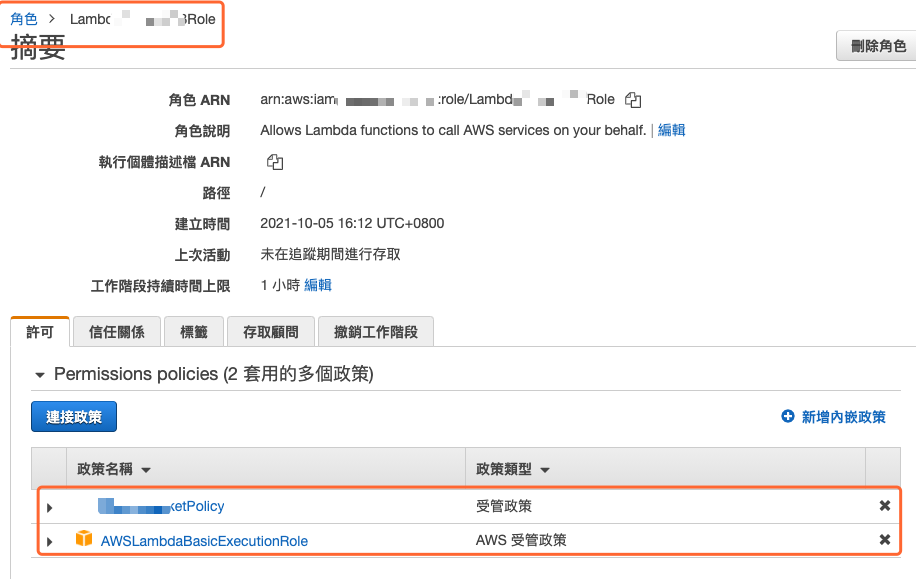
图 7、将新增的政策连接到先前的角色
步骤 3. 建立 AWS Lambda 函数
进入 AWS Lambda 管理控制台,选择建立 Lambda 函数,设定内容如下图所示。比较需要注意的是执行时间务必选择 Python 3.7,因为要使用 OpenCV 函式库层,而执行角色要也要记得选择上一个步骤设定的角色。
- 选择下列选项之一来建立您的函式: 从头开始撰写
- 函式名称: opencv45Func
- 执行时间: Python 3.7
- 架构: x86_64
- 执行角色: 使用现有的角色
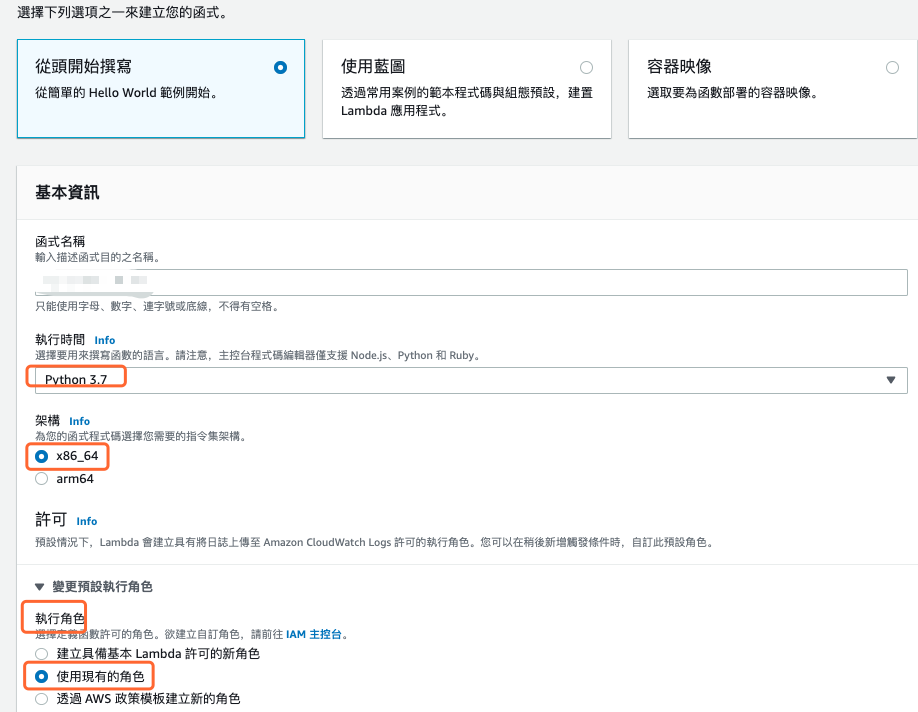
图 8、建立 Lambda 函数设定画面
在 Lambda 函数中点击 组态 页签,接着点击 环境变量,新增三个环境变量,如下所示:
- modelbucket: 存放权重的储存贮体,应该也是储存贮体 B,因为任何对 储存贮体 A 所做的写入都会引发驱动 Lambda 的事件。
- modelweight:yolov4cfg/yolov3.backup
- putbucket: 储存贮体 B
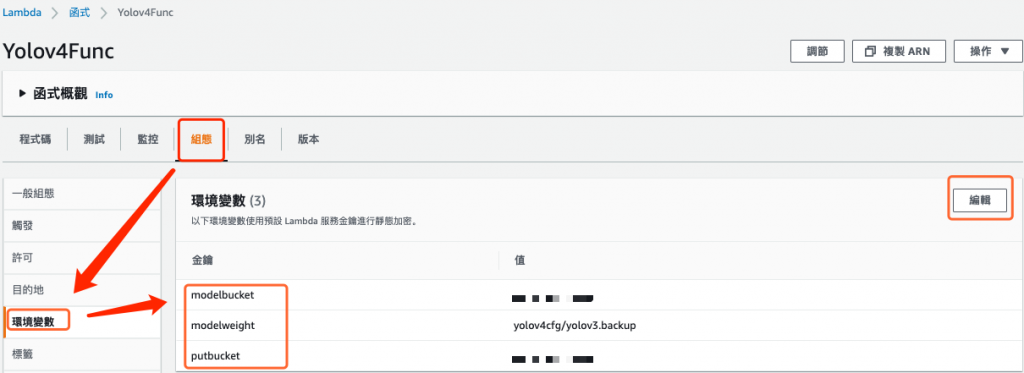
图 9、新增 Lambda 函数组态中的环境变量
步骤 4.在 AWS Lambda 建立 OpenCV 层
建立 Lambda 函数後,选择进入 AWS Lambda 函数的设定画面,在画面的最底端,为本函数 新建 Layer,如下图所示。
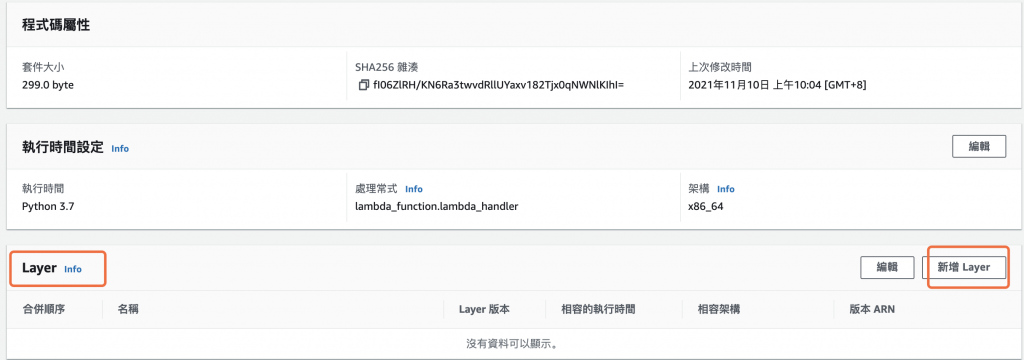
图 10、为 Lambda 函数新增 Layer
进入新增 Layer 画面後,选择层来源为 自订 Layer,接着选择先前建立的 opencv45 函式库层,如下图所示。
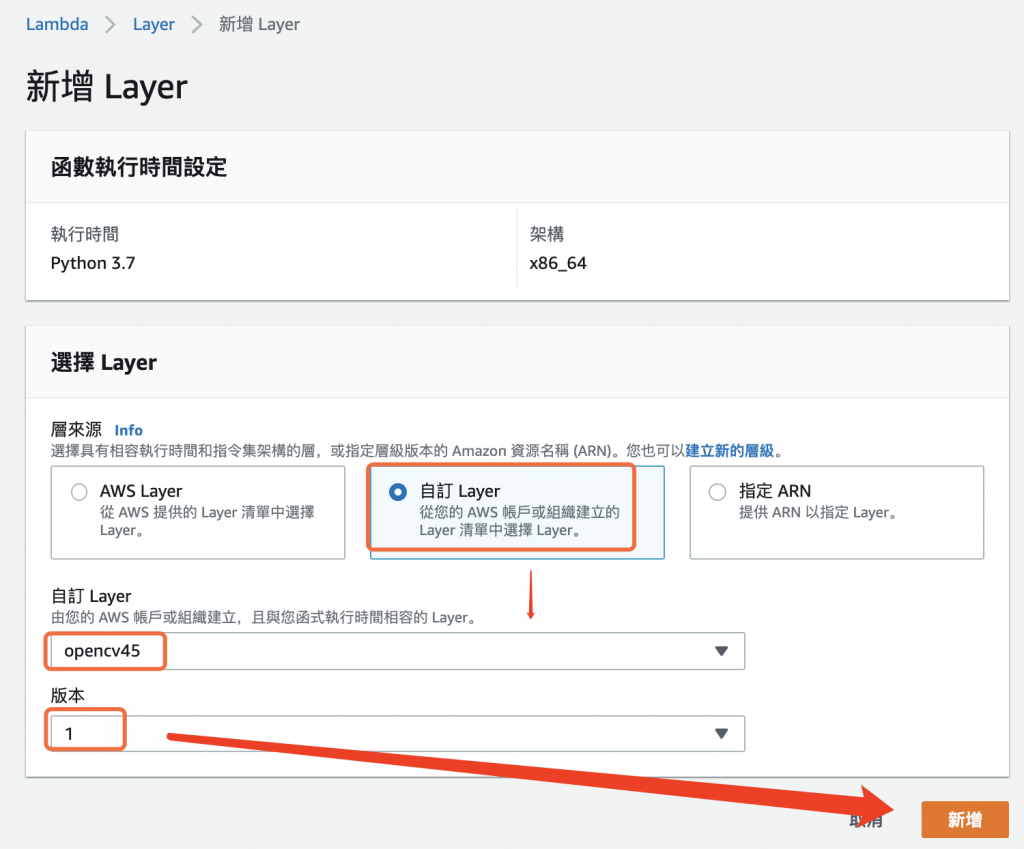
图 11、选择 opencv45 函式库层
步骤 5. 撰写 AWS Lambda 函数并完成测试
需要先建立一个目录 cfg,在目录内新增一个档案 yolov3.cfg ,这个档案的内容可以参考 Day 15 - 说明 YOLO 相关设定,而主要的推论程序为 service.py,内容如下
service.py
from __future__ import print_function
import urllib.request
import os
import subprocess
import boto3
import time
import cv2
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
LIB_DIR = os.path.join(SCRIPT_DIR, 'lib')
s3_client = boto3.client('s3')
modelbucket = os.environ['modelbucket']
modelweight = os.environ['modelweight']
modelcfg = 'cfg/yolov3.cfg'
# 从 s3 下载档案
def downloadFromS3(strBucket,strKey,strFile):
s3_client.download_file(strBucket, strKey, strFile)
strWeightFile = '/tmp/' + modelweight.replace('/', '')
downloadFromS3(modelbucket,modelweight,strWeightFile)
print(strWeightFile)
# 绘制物件方块框
def draw_image(image_path, output_path, pridicts):
cv2image = cv2.imread(image_path)
for k in range(len(pridicts[0])):
x, y, w, h = pridicts[2][k]
cv2.putText(cv2image, "{:.4f}".format(pridicts[1][k][0]), (x, y-6), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 1, cv2.LINE_AA)
cv2.rectangle(cv2image, (int(x),int(y)), (int(x+w),int(y+w)), (0,255,0), 2)
cv2.imwrite(output_path, cv2image)
# yolo 推论函数
def yolo_infer(weight, cfg, pic):
frame = cv2.imread(pic)
model = cv2.dnn.readNet(weight,cfg)
net = cv2.dnn_DetectionModel(model)
net.setInputSize(608, 608)
net.setInputScale(1.0 / 255)
net.setInputSwapRB(True)
classes, confidences, boxes = net.detect(frame, confThreshold=0.1, nmsThreshold=0.4)
return classes,confidences,boxes
# lambda 程序进入口
def handler(event, context):
for record in event['Records']:
inputbucket = record['s3']['bucket']['name']
outputbucket = os.environ['putbucket']
key = record['s3']['object']['key']
imgfilepath = '/tmp/inputimage.jpg'
downloadFromS3(inputbucket,key,imgfilepath)
prev_time = time.time()
result = yolo_infer(strWeightFile, modelcfg, imgfilepath)
print('predicting time: ' , (time.time() - prev_time))
tmpkey = key.replace('/', '')
upload_path = '/tmp/process-{}'.format(tmpkey)
draw_image(imgfilepath, upload_path, result)
s3_client.upload_file(upload_path, outputbucket, key,ExtraArgs={'ACL': 'public-read','ContentType':'image/jpeg'})
return 0
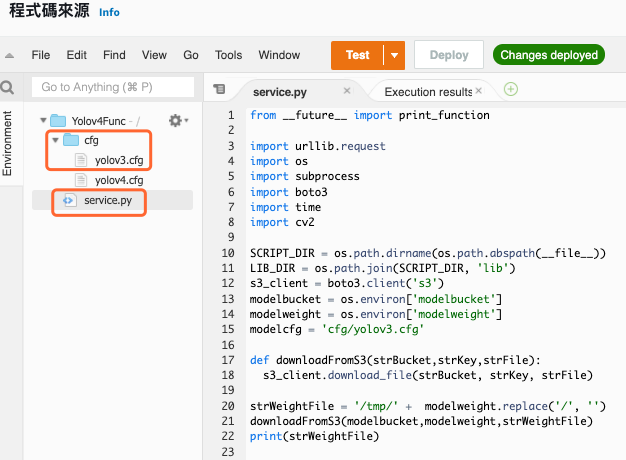
图 12、AWS Lambda 程序码
建立新测试事件,事件范本选择 hello-world,事件名称输入 fromS3Bucket,内容所下图所示,这是用来模拟当 S3 触发 Lambda 函数後所传过来的参数内容,记得将 [INPUT_BUCKET] 改成实际的输入储存贮体名称,而[INPUT_OBJECT]要确保有这个档案。
{
"Records": [
{
"s3": {
"bucket": {
"name": "[INPUT_BUCKET]",
"arn": "arn:aws:s3:::[INPUT_BUCKET]"
},
"object": {
"key": "[INPUT_OBJECT]"
}
}
}
]
}
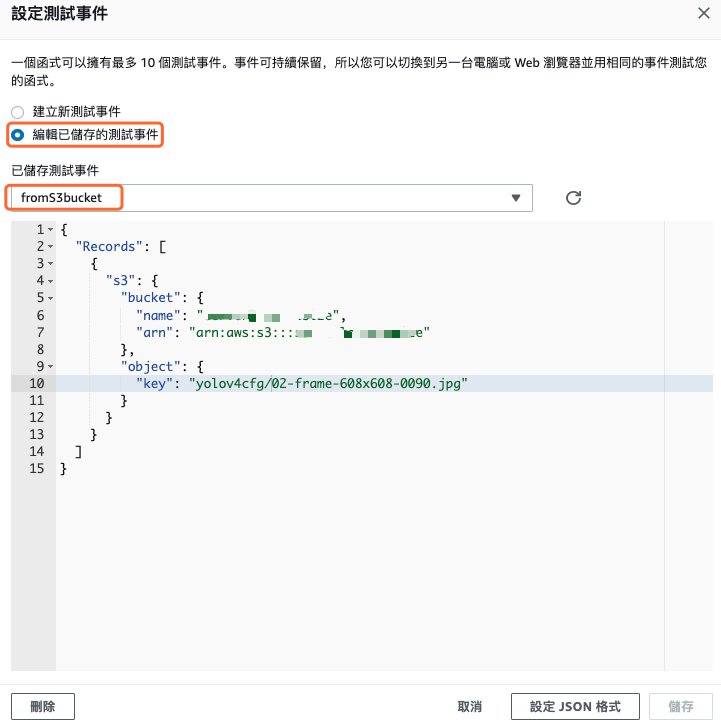
图 13、设定 Lambda 函数测试事件
拉到画面下方,修改 执行时间设定,将 处理常式 指定为 service.handler,如下图所示。
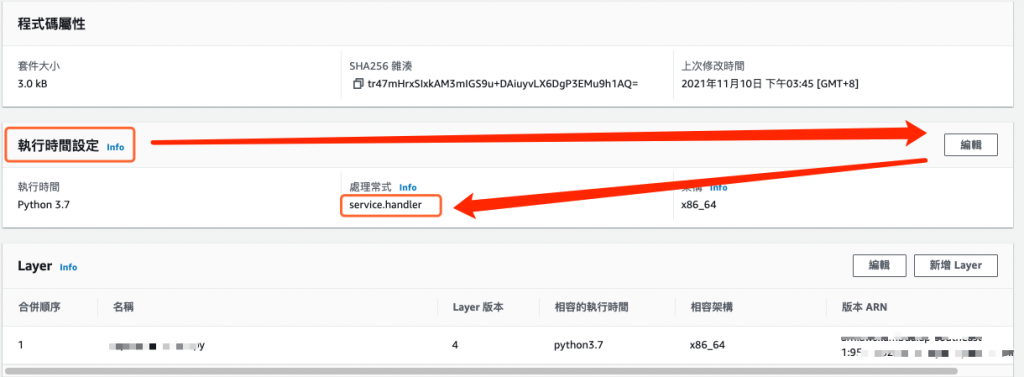
图 14、修改执行时间设定中的处理常式
最後点击 Test 进行测试,得到的结果如下图所示,推论时间约 1.75 秒,所需记忆体为 990 MB。
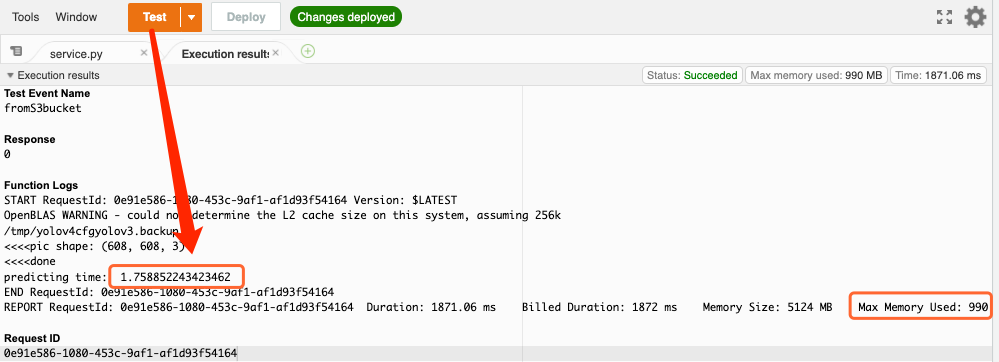
图 15、使用 OpenCV 进行 YOLO 推论
因此,这似乎是一个可以接受的解决方案,表 1.列出目前为止的所有 YOLO 辨识部署解决方案。
表 1、 使用 EC2/Lambda/SageMaker 进行 YOLO 辨识比较
| 使用 EC2 | 使用 Lambda (darknet) | 使用 SageMaker | 使用 Lambda (OpenCV) | |
|---|---|---|---|---|
| 成本(USD) | 0.736/hour | 0 | 1.0304/hour | 0 |
| 时间(秒) | ~ 0.1 秒 | > 60 秒 | 1秒 左右 | 1-3 秒 |
| 可用性 | 较差 | AWS 托管 | AWS 托管 | AWS 托管 |
参考资料
- Simple Inference Scripts for YOLO with OpenCV, https://github.com/erentknn/yolov4-object-detection/blob/master/yolo_image.py
- Day 34 - 实作 S3 驱动 Lambda 函数进行 Yolo 物件辨识, https://ithelp.ithome.com.tw/articles/10282495
- Day 35 - Amazon SageMaker 简介, https://ithelp.ithome.com.tw/articles/10282504
- Day 36 - 使用 Container 建立 Amazon SageMaker 端点, https://ithelp.ithome.com.tw/articles/10282519
- Day 37 - 在 AWS Lambda 建立 OpenCV Layer, https://ithelp.ithome.com.tw/articles/10282533
- yolov4-SageMaker, https://github.com/jackie930/yolov4-SageMaker
- Pytorch-YOLOv4, https://github.com/Tianxiaomo/pytorch-YOLOv4
- YOLO v4-v3 CPU Inference API for Windows and Linux, https://github.com/BMW-InnovationLab/BMW-YOLOv4-Inference-API-CPU
- pytorch_YOLO_OpenVINO_demo, https://github.com/Chen-MingChang/pytorch_YOLO_OpenVINO_demo
- Real-time Object Detection on CPU, https://towardsdatascience.com/real-time-object-detection-on-cpu-9f77d32deeaf
<<: Java 开发 WEB 的好平台 -- Grails -- (2) 新增一个 Grails 专案
>>: Believing These Myths About Assignment Helper Will Not Let You Grow
Day07-流量限制(二)
前言 昨天介绍了在 Node.js 跟 Go 里面要怎麽用 middleware 来做限流,虽然看似...
[DAY30]完赛心得
经过了这次的铁人赛,收获颇丰,因为我本身的知识量无法凑足30天,有蛮多部分都是另外去学的,让我学到了...
【Docker】01 安装与入门
1. 基本概念 image: 映像档。只能读取。可以从网路下载或是自己建立。 container: ...
Day04【JS】Promise、Async 和 Await
Promise 保证执行之後才会做什麽事情 对於「未来的值」的独立封装 状态 pending:尚未被...
Day05 X Code Minimize & Uglify
从今天开始终於要正式进入介绍前端效能优化各种技巧的章节了,如果到今天还愿意继续坚持看下去的读者记得...