用 Python 畅玩 Line bot - 26:爬虫(一)
这次要尝试的是将爬虫与 line bot做结合,那你可以使用 line bot 就能够查询到本周上映的新片。
首先要安装下列套件
pipenv install requests
pipenv install BeautifulSoup4
pipenv install lxml
- requests:用来处理 HTTP 请求
- BeautifulSoup4、lxml:用来解析处理requests取得的数据
import requests
from bs4 import BeautifulSoup
#GET请求
r = requests.get('http://www.atmovies.com.tw/movie/new/')
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
print(soup)
为了避免抓取到的内容用 Unicode 解析时出现乱码,我们可以设定 encoding 为 utf-8。
再来因为想要挖的是本周新片的标题与网址,那我们可以先到网页那边看看他的原始码。
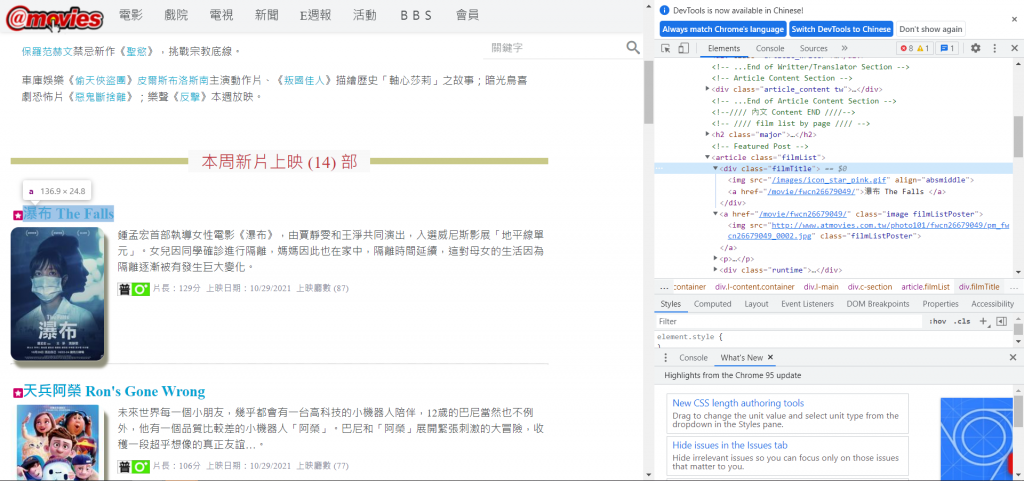
可以看到他的标题与网址部分是在 class 名称为 filmTitle 的 div 里面的 a 标签中。因此,我们可以将程序码改成下列样子。
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.atmovies.com.tw/movie/new/')
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
filmTitle = soup.select('div.filmTitle a')
print(filmTitle)
输出结果会是
[<a href="/movie/fwcn26679049/">瀑布 The Falls </a>,
<a href="/movie/fren47504818/">天兵阿荣 Ron's Gone Wrong </a>,
......
]
soup.select('div.filmTitle a')代表的是我们想要取得 class 名称为 filmTitle 的 div 中的 a 标签。
但我们只想要 a 标签内的文字跟网址部分,那就需要更精准的指令。
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.atmovies.com.tw/movie/new/')
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
filmTitle = soup.select('div.filmTitle a')
print(filmTitle[0].text)
print("http://www.atmovies.com.tw/" + filmTitle[0]['href'])
我们只要 filmTitle[0] 里的文字(也就是第一部电影的名称),所以使用filmTitle[0].text。
而 href 得内容只有 /movie/fren47504818/,还不是一个有效的网址,所以我们需要在前面加上 http://www.atmovies.com.tw/ 。
Day24 DB-NodeJS中的mongoDB
昨天讲了关联式资料库的MySQL,今天要接着介绍NoSQL中受欢迎的mongoDB,以及在NPM里m...
Day20:【技术篇】无障碍网页之前端切版基本概念
一、前言 上一篇文章提到了网页如何检测无障碍规范,但很多事情防范胜於未然,可以注意一下基本无障碍...
DAY27 - 网站正式上线前的准备
前言 今天是铁人赛的第27天,终於要进入把网站从自己的电脑里搬到云端上(服务器端) 有关於网址与网路...
LeetCode解题 Day22
1239. Maximum Length of a Concatenated String with...
[Day15] Esp32s用AP mode + Relay
1.前言 哈喽各位小夥伴,不知不觉系列文章已经进行一半了(感觉要解锁成就了),不知道各位在看完前几篇...