DAY29 Aidea专案实作-AOI瑕疵检测(4/4)
经过不懈的努力!我们终於来到此次专案时做的最後一个章节,前三个部分我们已经算是达成任务,成功训练出一个模型来做瑕疵的检测,而今天呢?算是一个追求更完美的步骤,让模型"好,还要更好"!
先来看看我们将结果上传至平台後的得分。

准确度是我们还可以接受的范围,但模型大小、载入时间以及推论速度似乎还有一些进步空间,今天我们就以这两方面来做加强。
更换模型
这是一个最直接的方法,但如果要维持其速度以及尺寸的话,尽量也选择一些轻量的模型,像是MobileNetV2, MobileNetV3, SqueezeNet...等,或许可以发现比较适合的模型。
设置动态学习率
我们在前面的章节也介绍过动态学习率的好处,再使用过後我们成功让模型的准确度提升了0.5个百分点,程序如下:
#动态学习率
from tensorflow.keras.callbacks import ReduceLROnPlateau
LR_function=ReduceLROnPlateau(monitor='val_acc',
patience=5,
# 5 epochs 内acc没下降就要调整LR
verbose=1,
factor=0.5,
# LR降为0.5
min_lr=0.00001
# 最小 LR 到0.00001就不再下降
)
然後把它放进Callbacks里面在训练时执行
callbacks_list = [LR_function]
神经网路剪枝(Pruning)
这是减少模型参数、缩小模型相当实用的办法,我们在DAY23也有介绍过,程序码实现如下:
先下载所需套件
pip install -q tensorflow-model-optimization
import tensorflow_model_optimization as tfmot
设定剪掉0.5-0.8的神经元
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude
batch_size = 16
epochs = 3
validation_split = 0.2
num_images = train.shape[0] * (1 - validation_split)
end_step = np.ceil(num_images / batch_size).astype(np.int32) * epochs
# Define model for pruning.
pruning_params = {
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(initial_sparsity=0.50,
final_sparsity=0.80,
begin_step=0,
end_step=end_step)
}
一样使用MobileNet
model=tf.keras.applications.MobileNet(weights='imagenet',input_shape=(128, 128, 3), include_top=False)
x = layers.GlobalAveragePooling2D()(model.output)
outputs = layers.Dense(6, activation="softmax")(x)
model=Model(inputs=model.inputs,outputs=outputs)
#Pruning
model_for_pruning = prune_low_magnitude(model, **pruning_params)
修剪成功後,我们在将模型拿去训练,就大功告成了,我们来看看修剪後的成果:
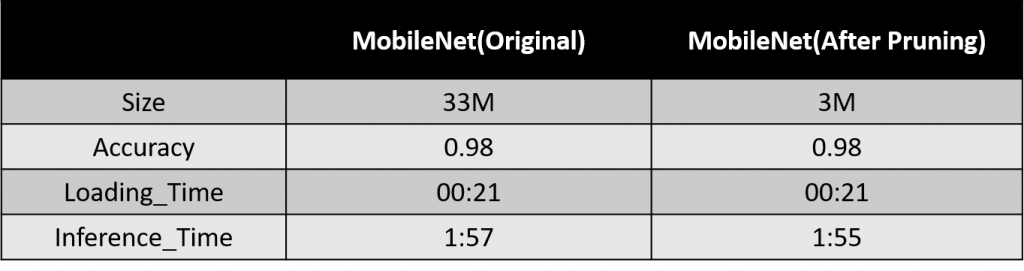
可以看到在准确率不变的状况下,我们成功将模型缩小成10倍。
改变预测方式
先厘清一个观念,你们觉得让模型"一次预测1张照片,跑五百次预测500张",跟"一次预测10张照片,跑50次预测500张"是一样快的吗?答案是否定的,让我们看看再更改了预测方式之後,推论速度进步了多少。
速度上可以说是差得非常多,将近一分半的时间,透过这个实验我们知道,尽可能让模型一次预测多张照片,效果会比一次预测一张来的好。
模型储存方式
我们在储存模型时通常会存为.h5的档案,这个档案会包括模型的架构以及权重,但我们也可以试着把架构与权重分开储存,来看看会发生什麽结果:
#储存架构
from keras.models import model_from_json
json_string = model.to_json()
with open("model.config", "w") as text_file:
text_file.write(json_string)
#储存权重
model.save_weights("model_weight.h5")
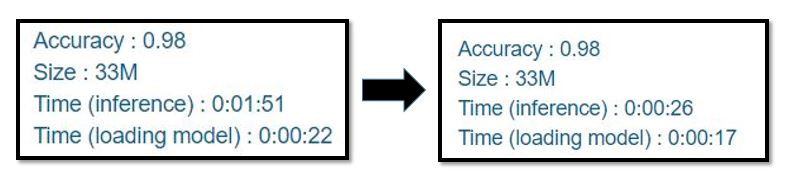
执行上方的程序码後我们会得到两种档案,一种是模型的架构,另一种是权重,见下图:

经实验,分开储存後得到的模型会比原来的小,载入时间也会提升,下图为比较:

以上是这次比赛中我们用来优化模型的一些方法,其实在用了这些方法後我们已经可以得到一个不错的分数了,当然如果想要再进一步的话,也还有许多方法等着你们去发掘、去尝试,小编就担任一个引路人的脚色,希望能有抛砖引玉的效果,我们这次的专案时做就到这边告一段落,希望大家的学习都有收获。
容器化的安全原则(the security principles of containerization)
-容器技术架构 容器映像是由开发人员创建和注册的包,其中包含在容器中运行所需的所有文件,通常按层组...
D16 - 用 Swift 和公开资讯,打造投资理财的 Apps { 加权指数 K 线图实作.4 - 在 X 轴标上每一根 K 棒的日期 }
目前我们已经做出台股加权指数的 K 线图,但目前进度的线图的 x 轴没有时间,所以当使用者看到这张图...
[区块链&DAPP介绍 Day10] Solidity 教学 - units and globally available variables-1
今日来介绍一些单位跟全域变数相关的东西 Ether Units 在任何数字後面加上 wei、gwei...
Day 28 | Unity游戏开发 - 介面设置及场景转换
在上一篇文章提到对话系统的管理,今天我们要来说明主画面设定及场景资料转换。 需要注意的是,介面的素材...
[Android Studio] 每日小技巧 - 在 Android Studio 中快速向 Google 作关键字搜索
身为开发时程紧凑的工程师 遇到问题或是疑惑时必须要能快速的排除 通常在专案中遇到不熟悉的物件,想到 ...