DAY21 资料正规化与资料增强(Data Normalization & Data Augmentation)
复习一下我们之前提到的观念,想要有一个好的预测模型,拥有一个好的资料集是一件很重要的事,因此我们在做资料分析时会把大部分的时间花在资料处理上面,做影像辨识时也不例外,拥有良好特徵的图片,或是足够的训练数据,对模型学习的状况也会有所帮助,今天就要来介绍两种常见实用的图片处理方法。
一、资料正规化(Data Normalization)
不知道大家对这个词是否熟悉,是的,我们在前面介绍机器学习的特徵工程时有提到过,资料正规化是指将原始资料的数据按比例缩放於 [0, 1] 区间中,且不会改变其原本的分布,我们在进行影像辨识时,我们在进行图像预处理时,也会习惯将像素值缩放到[0,1]之间(即除以255),作法也是相当简单。
读入图片
import cv2
img = cv2.imread("husky.jpg")
img
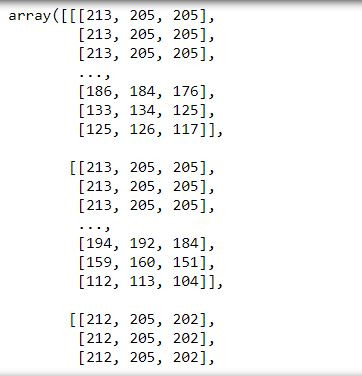
将阵列中的像素值全部除以255(最大像素值)
img=img/255.0
img

非常简单的步骤我们就可以将影像实施正规化,当然实务上我们要处理的影像不会只有一张,也有很多套件支援资料正规化的功能,我们等到後面在做介绍。
二、资料增强(Data Augmentation)
资料增强(Data Augmentation)较常用在影像处理上,我们在做机器学习的时候有提到资料不平衡的问题,影像辨识当然也会遇到,有时候我们手上的某个种类的图片很少,或是整份资料其实都不太够时,我们的神经网路会很难去学习,这时候我们就会使用资料增强的方法来"增加"我们手边的资料。
具体作法
我们利用一些物理手法,像是将图片翻转、平移、调整明暗度、调整比例尺寸後会得到一张新的图形,对我们人类来说这是一张一样的图,但对机器来说就是一张新的图像,资料增强就是透过对现有资料的变形,创造出更多的资料让我们做训练。

图片来源:https://towardsdatascience.com/machinex-image-data-augmentation-using-keras-b459ef87cd22
如何使用
我们要利用Keras这个套件来帮助我们完成资料增强,在使用前记得要先安装Keras套件,2.5版本的Tensorflow已经有支援Keras,就不必另外安装Keras。
conda install tensorflow==2.5.0
我们要使用的是Keras中的ImageDataGenerator这个功能,程序码范例如下:
载入套件
from tensorflow.keras.preprocessing.image import ImageDataGenerator
定义其参数
datagen=
ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-6,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode='nearest',
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=K.image_data_format())
参数说明
featurewise_center:去中心值,使数据集均值为0
featurewise_std_normalization:使每个输入样本除以自身标准差
samplewise_center:去中心值,使输入样本均值为0
samplewise_std_normalization:使每个输入样本除以自身标准差(只考虑自身图片)
zca_whtening:一种PCA降维处理,减少图片的冗余信息,保留最重要的特徵
zca_epsilon:zca白话的值
rotation_range:使图片随机旋转的角度,输入一个值,演算法会使图片在这个值区间随机旋转
width_shift_range:图片水平平移的尺寸
height_shift_range:图片垂直平移的尺寸
shear_range:随机裁减的角度
zoom_range:随机缩放大小
channel_shift_range:随机改变图片的颜色
fill_mode:图片经处理後边界以外的点的处理方式
horizontal_flip:随机进行水平翻转
vertical_flip:随机进行垂直翻转
rescale:对图片的每个像素值乘上这个缩放值,可理解为图片正规化
preprocessing_function:其他的前处理功能,可自行写def定义或是使用套件提供的
附加到资料上
在我们创造一个datagen後,我们要想办法将资料集结合进来,才会达到资料增强的效果,将资料读进来的方式一共有两种,都是利用到Image.data.preprocessing里头的功能。
1. flow_from_directory
使用from_directory的话我们需要将不同标签的图片进行分类,安插在同一个资料夹下,如下图:
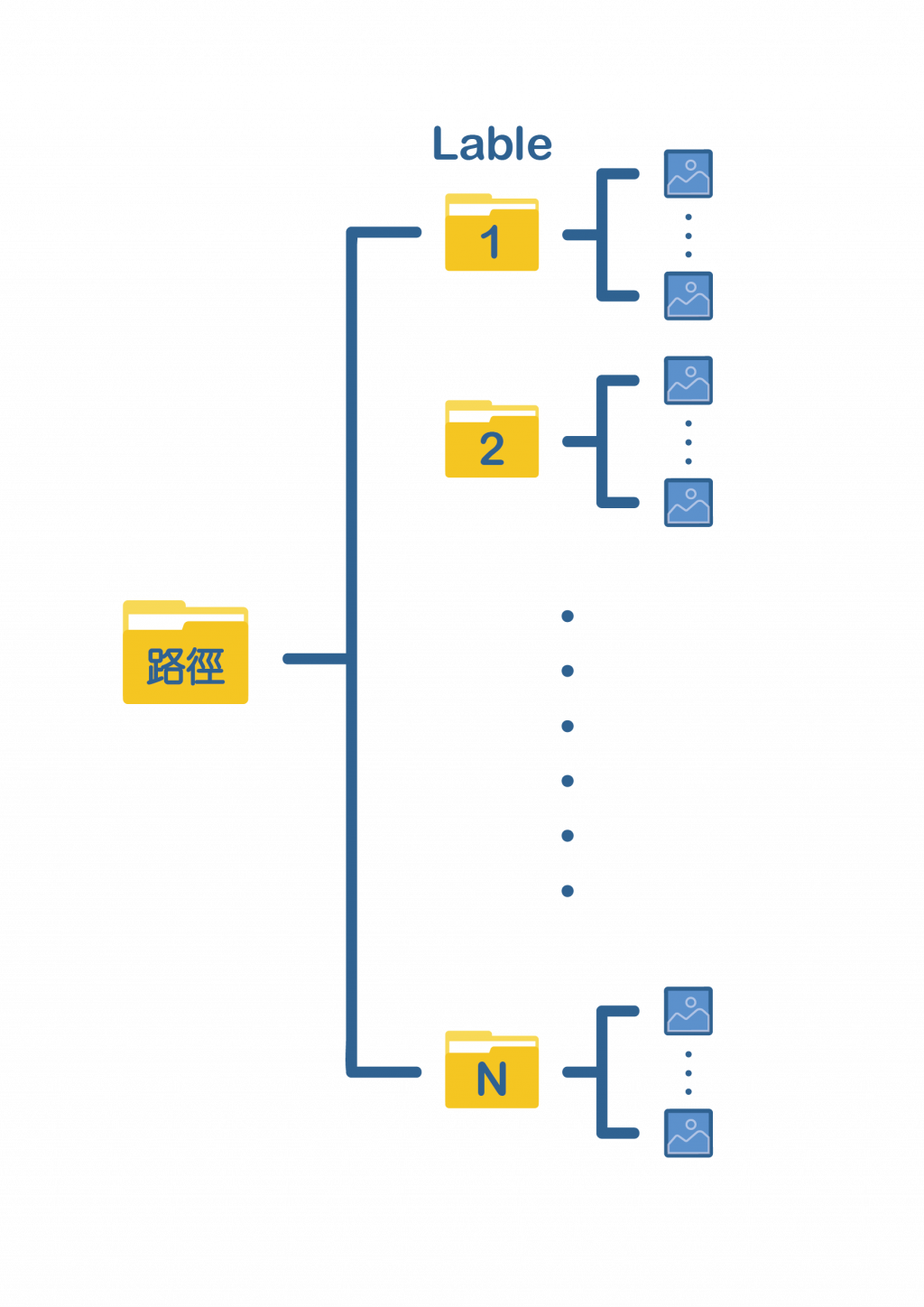
程序码
train_generator=
datagen.flow_from_dataframe(
directory,
labels="inferred",
label_mode="int",
class_names=None,
color_mode="rgb",
batch_size=32,
image_size=(256, 256),
shuffle=True,
seed=None,
validation_split=None,
subset=None,
interpolation="bilinear",
follow_links=False,
crop_to_aspect_ratio=False,
**kwargs
)
directory放置最上层资料夹的路径,labels选择"inferred",其余参数像是image_size、batch_size等皆可自行调整,详细的参数说明可至Image data preprocessing查看。
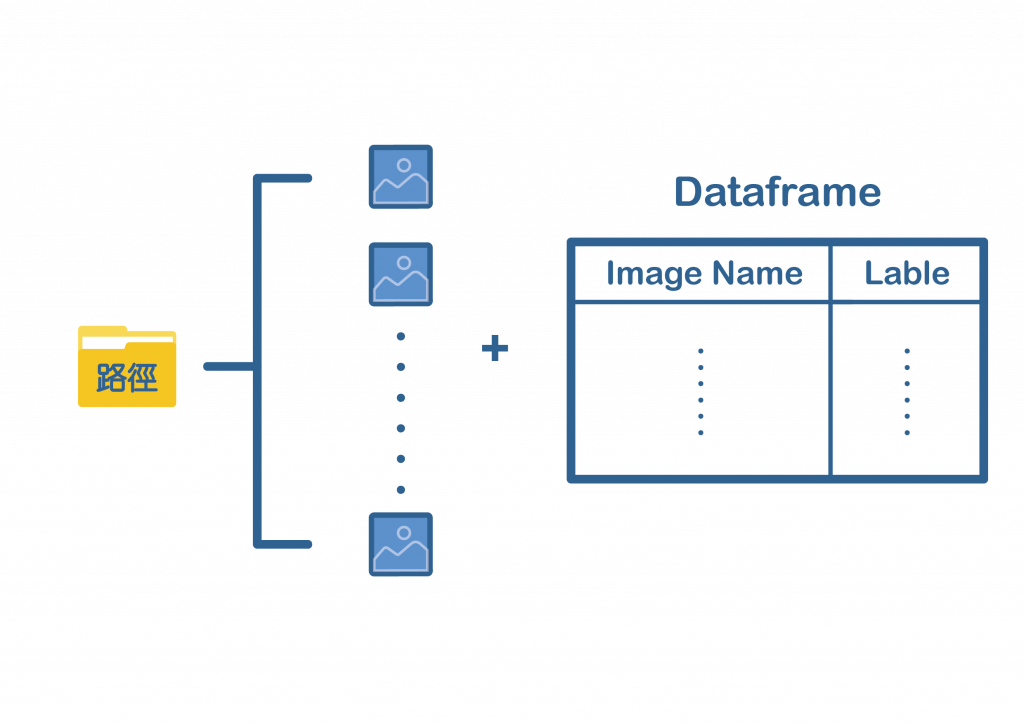
2. flow_from_dataframe
使用flow_from_dataframe可以不必将图片分类,全部放置在一个资料夹即可,但须额为制作一份DataFrame,里头要包含图片的名称以及标签,如下图:
程序码
train_generator=
datagen.flow_from_dataframe(
dataframe,
directory=None,
x_col='filename',
y_col='class',
weight_col=None,
target_size=(256, 256),
color_mode='rgb',
classes=None,
class_mode='categorical',
batch_size=32,
shuffle=True,
seed=None,
save_to_dir=None,
save_prefix='',
save_format='png',
subset=None,
interpolation='nearest',
validate_filenames=True, **kwargs
)
Dataframe要放含有图片名称跟标签的Dataframe,例如:

根据上面的例子,x_col要放"Image",y_col要放"Label",directory则是放所有图片所在的资料夹路径。
模型训练
在生成train_generator後,我们就可以丢进模型训练,这边要注意的是不能跟平常一样使用model.fit,而是要改用model.fit_generator。
fit_generator(
generator,
steps_per_epoch=None,
epochs=1, verbose=1,
callbacks=None,
validation_data=None,
validation_steps=None,
class_weight=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
shuffle=True,
initial_epoch=0)
三、结论
今天介绍了资料正规化以及资料增强,这些在影像辨识都是常用到的手法,非常重要也非常使用,模型的优劣很大程度的取决於我们的资料,这个观念请大家一定要记住,希望大家都有学习到东西,再会啦~
<<: [区块链&DAPP介绍 Day14] Solidity 教学 - interfaces
JavaScript Day 12. 每个元素都做运算的 map()
这一篇要来讨论另一个跟 filter 很相似的方法 map,在我们讨论 map 的同时,也可能会觉得...
03 - Uptime - 掌握系统的生命徵象 (1/4) - 我们要观测的生命徵象是什麽?
Uptime - 掌握系统的生命徵象 系列文章 (1/4) - 我们要观测的生命徵象是什麽? (2/...
【C#】Creational Patterns Singleton Mode
单例是设计模式的其中一种~ 它让程序在同一时间~ 只会有一个实例化的物件~ 设计的思维很简单~ 就是...
C# Linq
今天 来讲讲Linq这个好用的东西吧 不过我不会着墨在他哪些方法怎麽用(这个自己Google应该就可...
Day 5:浅谈警报 (alert) 的设计
前天使用 updown.io 架设了 status page,并且让它可以在服务无法连上的时候,自动...