我们的基因体时代-AI, Data和生物资讯 Day21- 基因注释资料在Bioconductor中物件:IRanges和GenomicRanges
上一篇我们的基因体时代-AI, Data和生物资讯 Day20-注释基因资讯的BED档案格式和bedtools上一篇主要先介绍一下BED档案格式和bedtools,因为这算是整个基因注释很重要的格式,也因此理解其巨大的可扩展性,只要所有的东西以基因序列的位置作为共同对照,即能整合这些资讯在一起,所以每几年有新的检验技术来量测DNA上的变化时,就会有新的资讯可以形成track来做注释。
这边再往下分享这些BED档案在R里面怎麽处理,相对於BED档案可以直接用字串处理工具如awk, sed等方法处理,但实际上也可以利用R语言,相对於使用bedtools在命令行环境下直接单纯做处理,在R里面它的操作可以更为复杂和精致,在R中处理,主要是利用一个Bioconductor专案中的软件包,用这些软件包来帮助处理相关之问题。目前Bioconductor是一个含有936以上个R语言packeges的开源软件平台,於2001年开始这个专案,其原始开发团队由加拿大生物统计学家Robert Gentlemen领军,由美国的Fred Hutchinson Cancer Research center领头发展,成立的目的是为了提供高通量基因体学研究资料更好的分析工具,相对於R的发展开源且没有任何资金赞助,bioconductor其实是一个有接受NIH资助的计画,目的便是发展直接处理高通量资料的工具。
理解所谓的BED档案格式後,就会发现这其实就是单纯用资料表达一段区域,在Bioconductor中则有两个包用来建构在R里面处理这类资料。
基因组的知识本质是由一段段线性序列组成
基因组学的知识本质上就是由一段段线性序列分布在不同染色体上所建立的,这样的知识或称作注释可以分为两类,一类是所谓的基因模型(哪边是外显子、哪边是内显子,哪个区域决定某个最终蛋白质)、转录因子的结合位置、特定区域的GC比例、区域的多型性,这类资讯可由各式各样的生物资料库所取得,另一类资讯则是实验室的量测结果如定序资料的等等,为了建议一个可以在R中处理这大类基因注释资料,Bioconductor团队里面的科学家便提出了Ranges的架构。
这个Ranges的资料可以有下面的一些操作:
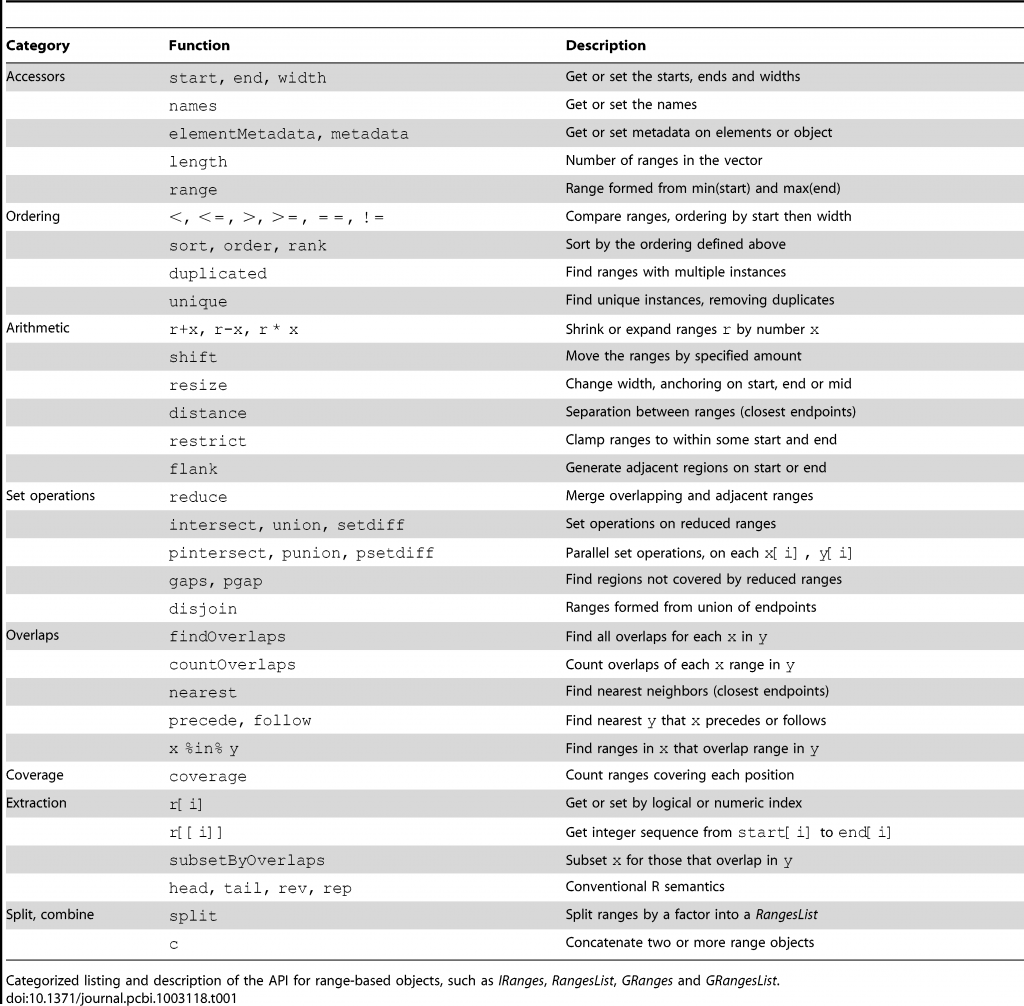
下面的示意图可以看到在最基础的Ranges架构中有的计算逻辑,最後建立了这个IRanges和GenomicRanges函数(这边可以发现跟bedtools部份功能其实是一样的),你可以去计算两串区域资料间的一些关系,藉此去进行筛选、合并、取值等等功能。
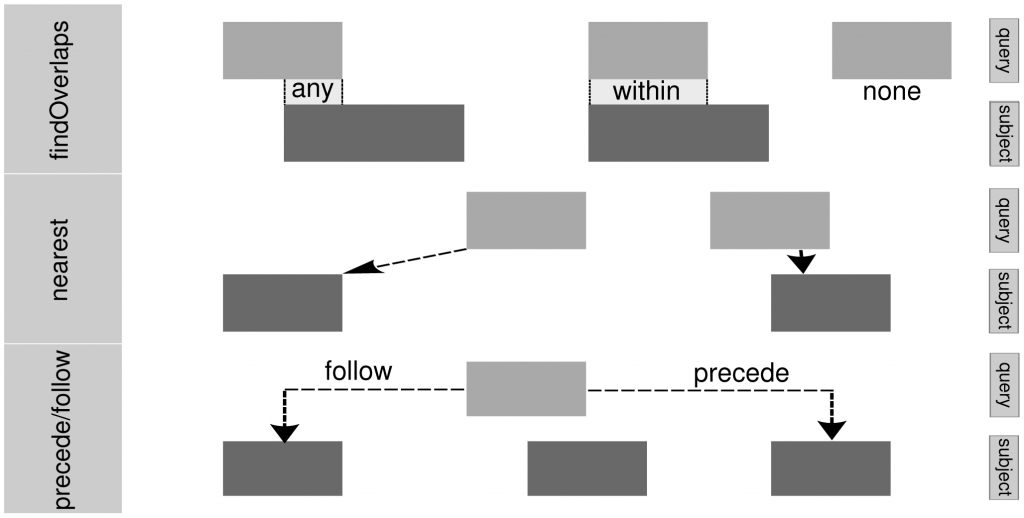
这边稍微来介绍一下,这边需要在R环境中先安装IRanges和GenomicRanges两个封包才能执行相关的函数。
在R环境中执行,因为这两个封包是在Bioconductor下面的,相对於一般R的library,使用install.packages来安装,要安装Bioconductor下面的library,则必须使用Bioconductor的安装工具,像在边就是使用BiocManage封包来进行安装。
BiocManager::install(c("IRanges", "GenomicRanges"))
安装完後,在读取到环境中即可
library(IRanges)
library(GenomicRanges)
IRanges 物件
一个IRanges物件可以藉由给予四个参数:start, end, width, names就能完成,但最少只要给予start和width即可,两个的数列必须要等长的,如同下面这样。在IRanges物件中不包含所在染色体资讯、正负股、或其他复杂注解资讯。
IRanges物件
Gene_range <- IRanges::IRanges(start=c(1,3,5,8,9), width=c(1,2,2,2,2))
将其显示出来就会长这样
> Gene_range
IRanges object with 5 ranges and 0 metadata columns:
start end width
<integer> <integer> <integer>
[1] 1 1 1
[2] 3 4 2
[3] 5 6 2
[4] 8 9 2
[5] 9 10 2
GenomicRanges 物件
GenomicRanges则是在IRanges物件上赋予生物意义,加上每个区域所在之染色体位置、正负股、其他注解,在GenomicRanges物件上的操作,会跟IRanges一样,这也是library开发者为了让使用者体验有一致性所加上的考量。
GenomicRanges物件建立主要需要有三个参数seqnames,ranges,strand,seqnames和strand给予其一个Rle物件,一个是用来给染色体资讯,一个则是用来定义正负股,ranges给予其一个IRanges物件,这个参数的vector长度都要一样。
genomic_ranges <- GRanges(
seqnames = Rle(c("chr1", "chr2", "chr1", "chr3"), c(1, 3, 2, 4)),
ranges = IRanges(101:110, end = 111:120, names = head(letters, 10)),
strand = Rle(strand(c("-", "+", "*", "+", "-")), c(1, 2, 2, 3, 2)))
将其显示出来会像这样
> genomic_ranges
GRanges object with 10 ranges and 0 metadata columns:
seqnames ranges strand
<Rle> <IRanges> <Rle>
a chr1 101-111 -
b chr2 102-112 +
c chr2 103-113 +
d chr2 104-114 *
e chr1 105-115 *
f chr1 106-116 +
g chr3 107-117 +
h chr3 108-118 +
i chr3 109-119 -
j chr3 110-120 -
-------
seqinfo: 3 sequences from an unspecified genome; no seqlengths
但GRanges最重要的特性是可以无限往後面延伸资讯,这边就让人想到BED档案或是VCF档案格式,比如下面这个就是给每一个Ranges加入统计分数,和GC比例之资讯。
genomic_ranges <- GRanges(
seqnames = Rle(c("chr1", "chr2", "chr1", "chr3"), c(1, 3, 2, 4)),
ranges = IRanges(101:110, end = 111:120, names = head(letters, 10)),
strand = Rle(strand(c("-", "+", "*", "+", "-")), c(1, 2, 2, 3, 2)),
score = 1:10,
GC = seq(1, 0, length=10))
将其显示出来会像这样
> genomic_ranges
GRanges object with 10 ranges and 2 metadata columns:
seqnames ranges strand | score GC
<Rle> <IRanges> <Rle> | <integer> <numeric>
a chr1 101-111 - | 1 1.000000
b chr2 102-112 + | 2 0.888889
c chr2 103-113 + | 3 0.777778
d chr2 104-114 * | 4 0.666667
e chr1 105-115 * | 5 0.555556
f chr1 106-116 + | 6 0.444444
g chr3 107-117 + | 7 0.333333
h chr3 108-118 + | 8 0.222222
i chr3 109-119 - | 9 0.111111
j chr3 110-120 - | 10 0.000000
-------
seqinfo: 3 sequences from an unspecified genome; no seqlengths
参考阅读:
Software for Computing and Annotating Genomic Ranges, 2013, PLoS Computational Biology
我们的基因体时代-Bioconductor:基因体学研究的好帮手(一)
我们的基因体时代-理解Bioconductor系列(一):Bioconductor中的Annotation资源
An Introduction to the GenomicRanges Package. 2021. Bioconductor
Lee, S., Cook, D. & Lawrence, M. plyranges: a grammar of genomic data transformation. Genome Biol 20, 4 (2019). https://doi.org/10.1186/s13059-018-1597-8
Herve Pages, Michael Lawrence. A quick introduction to GRanges and GRangesList object. 2015
Herve Pages. 10 things(maybe) you didn't know about GenomicRanges, Biostrings, and Rsamtools. 2016
trackViewer Vignette: Change the track styles
Florian Hahne, Robert Ivanek. The Gviz User Guide.2021
Common Bioconductor Methods and Classes
Soroor Hediyeh-Zadeh, An introduction to Bioconductor and it's data structure
这个月的规划贴在这篇文章中我们的基因体时代-AI, Data和生物资讯 Overview,也会持续调整!我们的基因体时代是我经营的部落格,如有对於生物资讯、检验医学、资料视觉化、R语言有兴趣的话,可以来交流交流!
Day 11 : 函式的介绍
学完前面的一些程序观念後,我想来简单说一下函式的概念。 函式(function)简单来讲就是一个小程...
下有对策 - CORS
前言 虽然还没实际碰过 CORS 错误,但实在太好奇了,所以到处看了文章,得出两个感想: 查不到解法...
MacOS 透过 NVM 管理 Node.js 的版本管理器(Node Version Manager)
NVM 是一个非常方便的 Node 管理器,你可以安装任何上线的 Node.js 版本并随时切换,以...
DAY28-VSCODE简写
输入简写: .class#id //没有标签名称时生成class="class"...
Day27 NodeJS实作 I
NodeJS的学习终於接近尾声,接下来就是要进行实作,为了熟悉刚学完的工具,预计用最後几天的时间完成...