[常见的自然语言处理技术] 文本相似度(I): Word Embeddings
前言
在我们每日使用的语言当中,我们经常能根据单词所表的意义区分出同义词与反义词,例如英文中形容词 thoughtful 与 attentive 、 considerate 同义,与 thoughtless 、 unthinking 反义。而当提及现任美国总统 Joe Biden 时,我们也许会在脑中浮现同在政坛上具有影响力的德国总理 Angela Merkel ,然而我们不容易联想到已故知名球星 Kobe Bryant,这是因为 Joe Biden 这个人名经常出现在国际政治相关的语境中。我们可以粗略地说, Joe Biden 与 Angela Merkel 较为接近,与 Kobe Bryant 较为疏远,尽管他们都具有美国籍。这里所探讨的亲疏关系,指的是语意上的相似度(Semantic Similarity)。
文字相似度(Word Similarity)
有了Bow、BoN、One-Hot Encoding 还不够吗?
在自然语言处理中,我们会透过将单词乃至文本量化以近一步表示文字之间的「距离」。之前我们介绍过三种文字的向量表示法: Bag of Words (BoW) 、 Bag of N-Grams (BoN) 和 One-Hot Encoding ,虽然皆容易理解也很好实践,然而他们却有以下致命的缺点:
- 无法衡量同原形的单词:以 BoW 表示法为例,在进行编码之前,需要进行词形还原( lemmatisation )的前处理手法,因此无法区分出同义语句。如「 I run 」与「 I ran 」的 BoW 向量皆相同,未能刻划时态上的差别所造成语意上的距离。
- 未能区分语境:starfish (海星) 、 squid (乌贼) 、 kangaroo (袋鼠)两两距离皆一致,无法比较语意上的远近。
- Out-of-Vocabulary (OOV): 无法表示出词汇表( vocabulary )中未收录的单词,若要尽可能表愈多单词,则需要的愈大的词汇量。
- 维数灾难:随着词汇量的增加,向量的维度( dimension )和资料的稀疏程度( data sparsity )会急速增加。极高的维度无异徒增电脑的计算负荷,引发维数灾难( curse of dimensionality )。
词嵌入(Word Embeddings)
既然以上的向量表示法皆无法乘载语意相似度资讯,我们另寻资讯稠密且维度低的向量表示法。
分布假说(Distributional Hypothesis)
「物以类聚」是我们耳熟能详的一句谚语。在语言学的脉络里,语言学家则认为在相同上下文中一起出现的两个单词会有相似的意义,这就是着名的分布假说( distributional hypothesis )。
Distributional Hypotheis:
Linguistic items with similar distributions have similar meanings.
-Harris, Z (1954)
"You shall know a word by the company it keeps."
-John Rupert Firth (1957)
词嵌入(Word Embeddings)
词嵌入( word embedding )也是一种文字的向量表示法,使得在相同上下文中愈常共同出现的单词能够被表示成在向量空间中距离愈靠近的向量;反之,愈少共同出现的单词,其向量距离就愈远。因此 word embedding 藉由更高的维度将语意相似度的资讯保留了起来。
word embedding 表示法具有两项优势:维度缩减( diemension reduction )、上下文相似性( context similarity )
在命名实体识别( Named-Entity Recognition, NER )、情感分析( sentiment anaylsis )和推荐系统( recommendation system )等自然语言处理的课题中皆使用了 word embedding 的技术。
意义相近的单词其向量在空间中也会更靠近
图片来源:O'Reilly
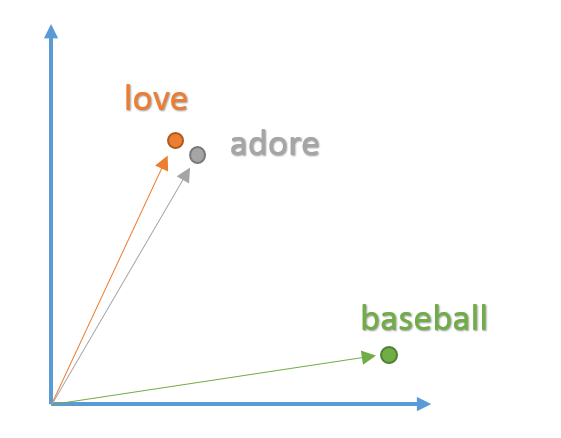
在不同语境中相依与相对单词的向量分布
图片来源:Medium
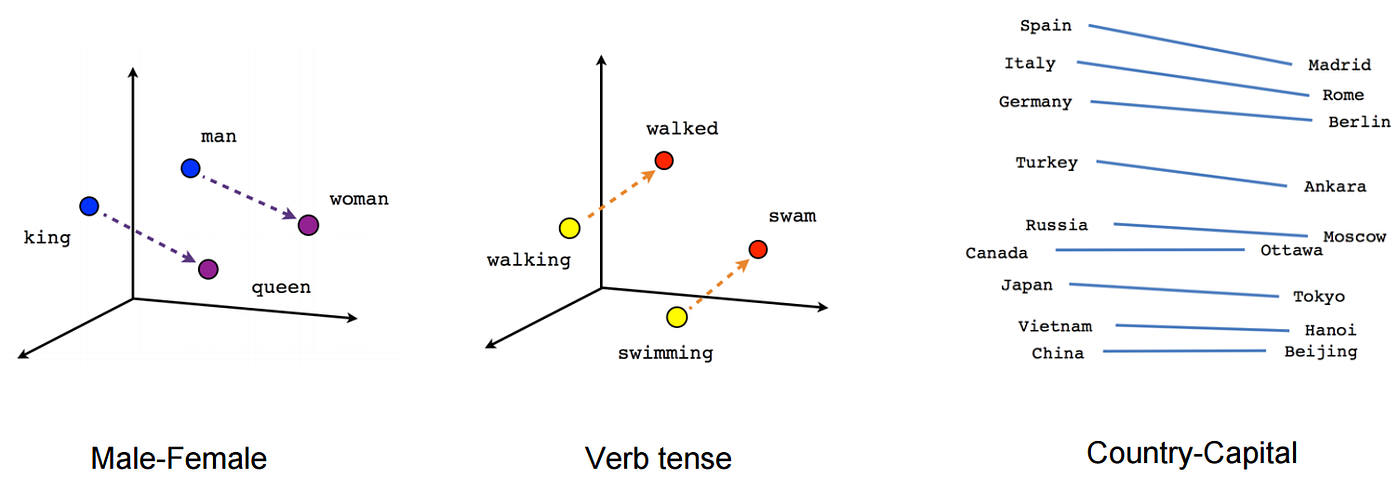
使用spaCy进行单词的向量化
在深入探讨 word embedding 的架构之前,我们使用开源的 Python 套件 spaCy 中已经训练好的 word embedding models 来进行文字的向量化并检视其维度。 spaCy 内建了多国语言模型,支援英文、德文、法文等欧洲语言,亦包含中文和日文,甚至提供多语言( multi-language )模型。
spaCy支援多国语言
spaCy 现行版本有四个英文词嵌入模型,我们选择最轻量的 en_core_web_sm。
第一步:在终端机下载 spaCy 并安装模型
$ pip install -U spacy
$ python -m spacy download en_core_web_sm
接着来到 Python 编辑环境,首先引入 spaCy 模组,并载入刚才下载好的语言模型:
import spacy
# Load an English word embedding model
nlp = spacy.load("en_core_web_sm")
重头戏登场,依照自己的喜好输入英文字词,并透过模型的 vector 属性将单词表示成向量:
# vector representation of word "python"
python_vec = nlp("python").vector
print("Word Embedding Representation of 'Python': {}".format(python_vec))
检视一下 python 这个单词的向量表示:
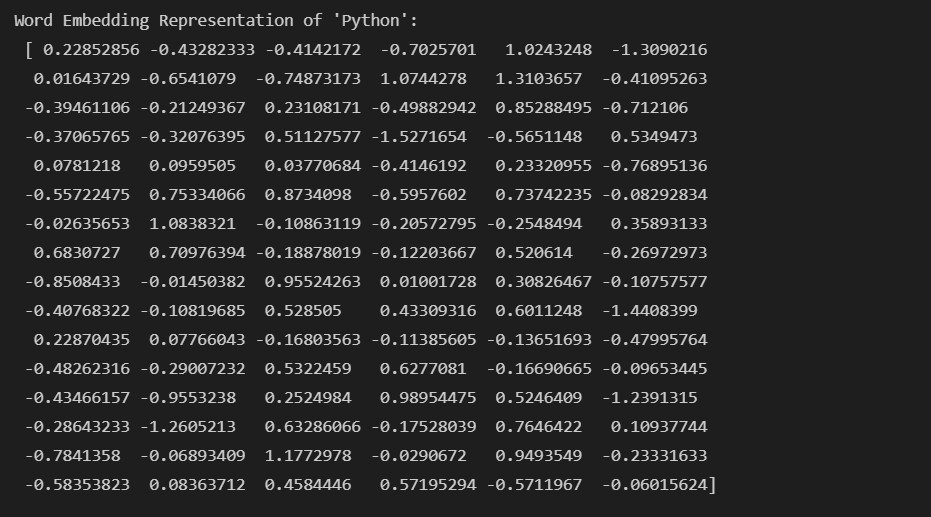
我们好奇向量的维度(不同模型会依照使用的语料库建构出不同维度的向量空间),可以使用 len(python_vec) 取出向量的维度:
# obtain vector size
vector_length = len(python_vec)
print("We have a {}-dim vector.".format(vector_length)) # We have a 96-dim vector.
Hmmm... 96维的向量!乍看之下维度非常高,但记得, BoW 、 One-Hot Encoding 表示法会因着所需的词汇增多而使得向量的维度飙涨,所以使用 word embedding 模型已经大幅缩减向量空间的维度了!
讲到这里,我们还没见识到 word embedding 的真正威力-语意相似度。别急着敲碗,明天将会介绍如何衡量向量之间的距离,敬请期待下一篇,晚安!
阅读更多
- Word Embeddings in NLP and its Applications
- Pre-trained English Word Embedding Models| spaCy
- Trained Models & Pipelines| spaCy
<<: Day 05-其他常结合Chatbot的云端服务器介绍
Day 13:100. same tree
今日题目 题目连结:100. same tree 题目主题:Tree, Depth-First Se...
企业资料通讯Week5 (1) | Catche 网页快取
完整参考连结在底下 甚麽是网页快取? 想一想大型网站如FB、IG,或是虾皮等购物网站,如果一次有很多...
JavaScript基本功修练:Day26 - Promise的语法糖:async/await
除了Promise之外,还有async/await语法来处理非同步程序,它背後的操作原理与Promi...
Numbers
myint = 7 print(myint) myfloat = 7.0 print(myfloat...
[07] telegram 回声各种讯息种类
请跟查看官方提供的文件 https://core.telegram.org/bots/api#ava...