电子书阅读器上的浏览器 [Day20] 翻译功能 (II) 取得网页全文
接着来讲讲怎麽取得 browser 目前网页中的本文内容,然後再把它转给昨天介绍字典 App。
取得需要翻译的网页全文
网页内容千奇百怪,如果直接抓取整个网页的所有文字,其中会有很多不必要的资讯:像是标题,侧边栏,其他相关文章连结说明,留言,等等等。
这时,之前开发好的阅读模式就可以派上用场了。阅读模式正是把不相干的元件都去除,只留下真正重要的内容。如果先在网页上套用阅读模式,再抓取文字内容,就可以得到比较纯正的内容。把这些内容再拿去翻译就不会显示杂乱无章。
阅读模式功能采用的 Readability.js 很好心的提供了一个 textContent 的变数,让我可以直接拿到里头的纯文字部分。(第 563 行)

下面的程序码片段则是在将网页先切换成阅读模式,然後才去取得里头的文字部分:
suspend fun getRawText() = suspendCoroutine<String> { continuation ->
if (!isReaderModeOn) {
injectMozReaderModeJs(false)
evaluateJavascript(getReaderModeBodyTextJs) { text -> continuation.resume(text.substring(1, text.length-2)) }
} else {
evaluateJavascript(
"(function() { return document.getElementsByTagName('html')[0].innerText; })();"
) { text -> continuation.resume(text) }
}
}
实作上述三个环节後,就大功告成啦。由於这功能只支援 Onyx 的设备,所以我在工具列中加了一个全文翻译的按钮,但目前只有在 Onyx 的设备中才会显示。
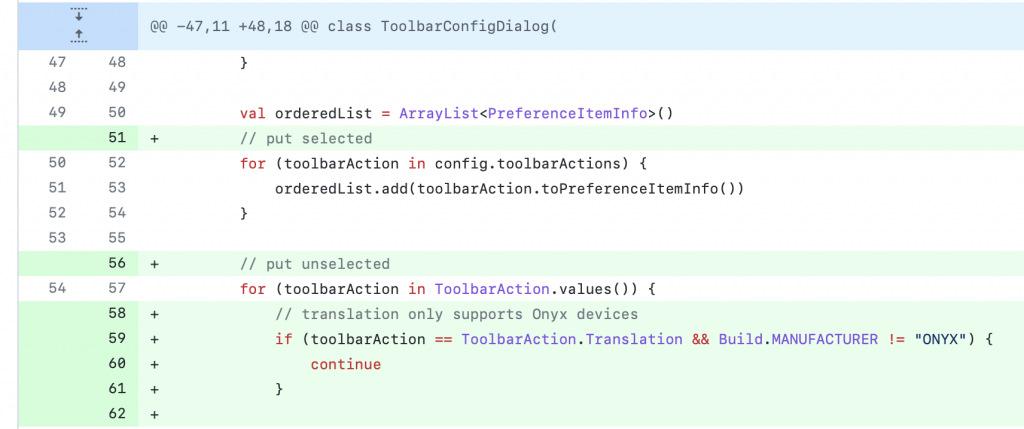
第 59 行判断设备是否 Manufacturer 为 ONYX,如果是的话,就表示这是文石生产的设备,这时才会在工具列设定中出现在这个功能让使用者选择。
示范画面
示范影片
参考原始码版本
https://github.com/plateaukao/browser/releases/tag/v8.9.0
在後续几篇会再介绍到如何加入 Google Translate 网页的全文翻译方式。这麽一来,就可以不用只受限於 Onyx 的设备。因为那部分内容有点复杂,所以也是会分成几篇来讲解。
强敌!费波那契数的哥哥登场,Ruby 30 天刷题修行篇第五话
大家好,我是 A Fei,相信大家应该都听过费波那契数(Fibonacci)的大名,又称费式数列,是...
网路设备:路由器
5 路由器 (Router) 一种专门处理封包传输的设备,透过处理路径位置来传输资料;主要工作在网路...
如果你对Microsoft 认证感兴趣
首先感谢这个技术平台让我分享一些专业的东西,今天我会分享一些Microsoft exam certi...
纯手工打造UART版资料清洗工具之 Pyside2 GUI 大补帖 - Part A
笔者想要在网路上实在很难找到好用又齐全的PySide2教学大全,那乾脆自己做一份自己想要的大补帖出来...
[重构倒数第05天] - 要如何再 Vue2 使用 Composition API
前言 该系列是为了让看过Vue官方文件或学过Vue但是却不知道怎麽下手去重构现在有的网站而去规画的系...