[常见的自然语言处理技术] 重不重要?TF-IDF 会告诉你
前言
在自然语言处理的诸多课题如信息检索( information retrieval )和文本探勘( text mining )当中,我们希望找出重要的单词或文句。在过程中我们需要将文字进行量化(转化为向量)以进行後续处理及筛选。常见的向量表示法有:
- One-Hot Encoding: 假设词汇表(vocabulary, 意为语料库中独特单词所构成的集合)有N个单词,将每个单词依序对应到一个N维向量,并且符合只有在其顺位的维度为1,其余维度皆为0的编码原则。
将词汇表中的单词进行 One-Hot 编码
图片来源:Shane Lynn

- Bag of Words: 简称为BoW,以统计单词(word)在语料库(corpus, 由多个documents所组成)中出现的个数(详见本系列第八天的文章:Bag-of-Words Model:简单直观的统计语言模型)
各个句子以BoW表示成向量
图片来源:GDCoder

- Bag of N-Grams: 简称为BoN,是为BoW的衍生表示法,统计n-gram(由n个连续单词所构成的小单位)在语料库中出现的个数(详见本系列第十天的文章:N-Gram Model 与关键字预测 (II))
各个句子以1-grams (tokens) 与 2-grams 表示成向量
图片来源:GDCoder

然而以上编码原则皆有一个共通点:每个单词都被视为一样重要。然而文件当中通常夹杂许多停用词如 a 、 the 、 be ,未能提供实际意义,却往往非常大量地出现在文本当中,因此仅凭单词出现的次数( occurrences )来说明该单词在一份文件乃至於整个语料库中的重要程度,是不具说服力的。今天我们要谈的TF-IDF就是一种衡量单词重要性的加权机制。
词频(Term Frequency, TF)
什麽是TF-IDF?
TF-IDF 全名为Term Frequency-Inverse Document Frequency,是一种决定单词对於一份文件重要程度的衡量手法。它由两个部分组成:词频(term frequecny, tf)与逆向文件频率(inverse document frequency, idf),接下来我们分别来介绍这两者。
在深入探tf与idf之前,为了避免读者的困惑,我们先解释语料库((text) corpus)、文件(document)和单词(term)之间的关系。
文件是由单词构成,例如一篇文章、一首诗词,在Python当中经常以字串的形式出现,其与单词的从属为「单词属於文件」;语料库是多份文件的集合,例如诗集,在Python当中常以list的物件出现,其与文件的从处关系为「文件属於文语料库」。
词频
词频,顾名思义就是单词出现在一份文件的频率。若某一单词在一份文件当中出现的次数越多,我们会直觉地认为它愈是重要。然而我们不能光以「次数」来衡量,必须考虑文件的篇幅。因此我们需要进行正规化,将次数再除以文件长度,於是有了以「频率」来衡量单词重要性的定义方式:

在以上定义中, 表示单词 t 在文件 d 当中的次数。
由TF衍生的加权方式
衡量单词相对於文件重要程度的定义方式并不惟一,以下列举出几项由传统词频衍生出的加权计算方式:

图片来源:Wikipedia
逆向文件频率(Inverse Document Frequency, IDF)
逆向文件频率
有许多单词,其词频非常高,却不具重要性,如 a/an、 the 等停用词(stop words)。因此由将单词出现的次数正规化而得的词频还不足以衡量单词在文本中的重要程度,我们仍需要考虑单词对於语料库的重要程度,其定义方式如下:
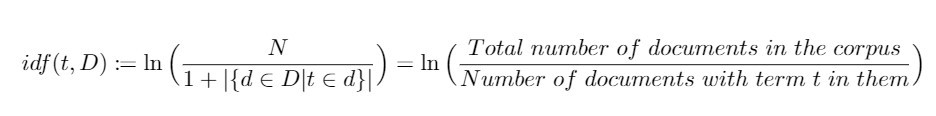
在上述定义当中, D 表示语料库,其元素为文件 d 。而分母加上1则是为了避免由於单词不在语料库中而导致分母为零(division-by-zero)的状况,是一种well-defined的表现。
藉由对数 ln() 严格递增的特性,我们可以直言:若某个单词愈是集中出现在某几份文件中,则 idf 就愈大,其之於整个语料库而言就愈重要。反之,当某个单词在大量文件中都出现,idf就愈小,我们会认为这个单词愈是一般。。
由IDF衍生的加权方式
衡量单词相对於整个语料库重要程度的定义方式也不是惟一的,以下列举出几项由传统IDF衍生出的加权计算方式:

图片来源:Wikipedia
整合起来:TF-IDF加权分数
当我们将 tf 和 idf 相乘起来,就可以反映出一个单词在语料库中对於一份文件有多麽重要。於是我们可以来正式定义今日的主人公 tf-idf :
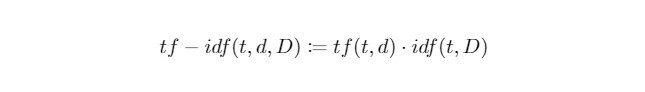
tf-idf Score与文件矩阵(Term-Document Matrix)
接下来我们示范如何计算单词对於文件的 tf-idf 权重。
首先我们定义好含有三份文件(单一句子所构成的字串)的小型语料库,并且对语料库进行前处理:
from preprocessing import preprocess_text
# sample documents
document_1 = "This is the first sentence!"
document_2 = "This is my second sentence."
document_3 = "Is this my third sentence?"
# corpus of documents
corpus = [document_1, document_2, document_3]
# preprocess documents
processed_corpus = [preprocess_text(doc) for doc in corpus]
scikit-learn 函示库中收录了计算 tf-idf 的物件 TfidfVectorizer ,直接引入即可。将刚才前处理後的语料库当作训练资料进行拟合,我们即可得到每个单词相对於各个文件的权重:
from sklearn.feature_extraction.text import TfidfVectorizer
# initialise TfidfVectorizer
vectoriser = TfidfVectorizer(norm = None)
# obtain weights of each term to each document in corpus (ie, tf-idf scores)
tf_idf_scores = vectoriser.fit_transform(processed_corpus)
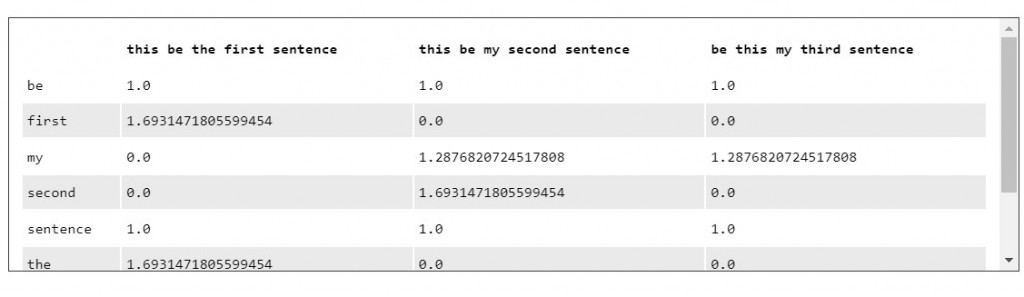
文件矩阵(term-document matrix)用来表示各个单词在整个语料库中之於文件的重要性,其由 tf-idf scores 所构成。
我们透过转换为 pandas dataframe 将结果呈现出来:
# get vocabulary of terms
feature_names = vectoriser.get_feature_names()
corpus_index = [n for n in processed_corpus]
import pandas as pd
# create pandas DataFrame with tf-idf scores: Term-Document Matrix
df_tf_idf = pd.DataFrame(tf_idf_scores.T.todense(), index = feature_names, columns = corpus_index)
print(df_tf_idf)
时不我与,今天的介绍就到这边,我们明天见!
阅读更多
- Corpus Vocabulary
- One-Hot Encoding of Text Data in Natural Language Processing
- Document and Query Weighting Schemes
<<: [day-4] 一切的开端,认识你所使用的工具,Visual Studio Code !(Part .2)
Day30 Redis架构实战-Redis Request Routing/效能监控与调教
Redis Request Routing 在Redis Server丛集中所有的操作透过Reque...
[Day9]参观乙太链与区块链
那我们就实际上网去看一下乙太链跟区块链长怎麽样吧! 参观乙太链 这边分别是最近新增的区块以及最近完...
DAY 30 - 殭屍女孩 (3) 完
大家好~ 我是五岁~ 今天来把殭屍女孩完成吧~~ 话说本日的我选颜色有点失常阿~ 哈哈哈哈阿~~ 不...
Day 24 [Python ML、资料视觉化] 如何选择图表型态
你学到了甚麽? 我们可以将学到的图表分为3类 Trends - 可以定义一种变换的模式 sns.li...
DAY 21 制作 Nav Bar - FontAwesome
FontAwesome FontAwesome 让我们可以快速方便的使用 Icon 的设计,不过他有...