[Day 6] 非监督式学习 K-means 分群
非监督式学习 K-means 分群
今日学习目标
- 非监督式学习
- 何谓非监督式学习? 集群分析?
- 分群演算法介绍
- K-means 分群分类演算法
非监督式学习(Un-supervised learning)
在训练过程中没有所谓的标准答案,故机器会自己从资料群中找出一套分群的法则。非监督式学习的优点是不需要事先以人力标签,只给定特徵让机器想办法会从中找出规律。常见的非监督式的分群演算法有 K-means,它根据物以类聚的原理目标是根据特徵把资料样本分为 K 群。其中在训练模型时仅须对机器提供输入的特徵,并利用分群演算法自动从这些特徵中找出邻近的集群中心作为该类别。
K-means 演算法
透过分群分类演算法我们能够将多种维度的资料进行分类。K-means 演算法的概念很简单也非常容易实作,仅一般加减乘除就好不需复杂的计算公式。
- 初始化: 指定 K 个分群,并随机挑选 K 个资料点的值当作群组中心值
- 分配资料点: 将每个资料点设为距离最近的中心
- 计算平均值: 重新计算每个分群的中心点
重复步骤2、3,直到资料点不再变换群组为止

[程序实作]
载入相关套件
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
1) 载入资料集
我们今天要实作分群分类的问题,因此鸢尾花朵资料集非常适合当作范例。其资料集载入方式在第四天有提过,是一样的内容!
iris = load_iris()
df_data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= ['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species'])
df_data
K-Means
K-means 演算法在 Sklearn 套件中已经帮我们封装好了,使用者只要呼叫 API 即可将分群分类演算法快速实作。
Parameters:
- n_cluster: K的大小,也就是分群的类别数量。
- random_state: 乱数种子,设定常数能够保证每次分群结果都一样。
- n_init: 预设为10次随机初始化,选择效果最好的一种来作为模型。
- max_iter: 迭代次数,预设为300代。
Attributes:
- inertia_: inertia_:float,每个点到其他丛集的质心的距离之和。
- cluster_centers_: 特徵的中心点
[n_clusters, n_features]。
Methods:
- fit: K个集群分类模型训练。
- predict: 预测并回传类别。
- fit_predict: 先呼叫fit()做集群分类,之後在呼叫predict()预测最终类别并回传输出。
- transform: 回传的阵列每一行是每一个样本到kmeans中各个中心点的L2(欧几里得)距离。
- fit_transform: 先呼叫fit()再执行transform()。
from sklearn.cluster import KMeans
kmeansModel = KMeans(n_clusters=3, random_state=46)
clusters_pred = kmeansModel.fit_predict(X)
评估分群结果
使用者设定 K 个分群後,该演算法快速的找到 K 个中心点并完成分群分类。拟合好模型後我们可以计算各个样本到该群的中心点的距离之平方和,用来评估集群的成效,其 inertia 越大代表越差。
kmeansModel.inertia_
输出结果:
78.94084142614602
若要查看各群集的中心点,可以参考以下程序码。
kmeansModel.cluster_centers_
输出结果:
array([[5.9016129 , 2.7483871 , 4.39354839, 1.43387097],
[5.006 , 3.428 , 1.462 , 0.246 ],
[6.85 , 3.07368421, 5.74210526, 2.07105263]])
分类结果
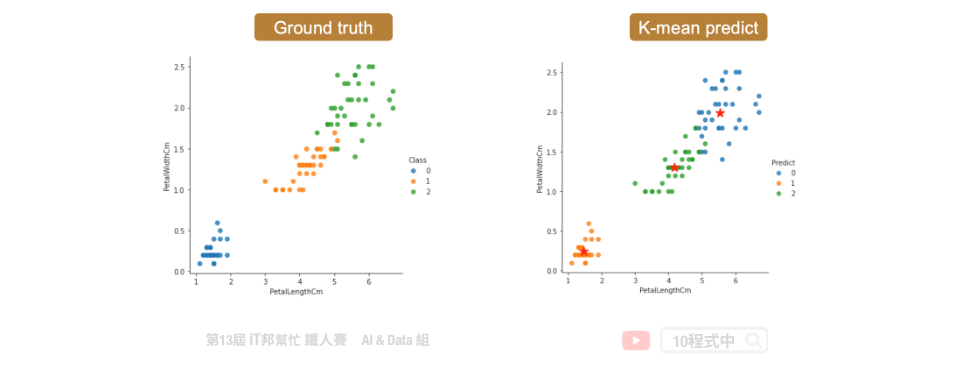
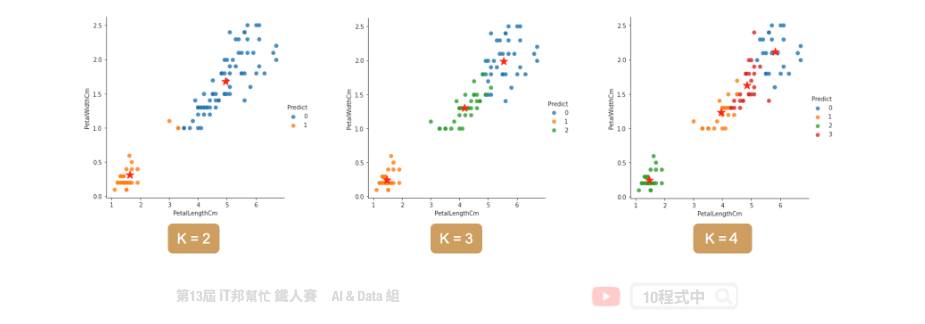
如何决定K?
当你手边有一群资料,且无法一眼看出有多少个中心的状况。可用使用下面两种方法做 k-means 模型评估。
- Inertia 计算所有点到每群集中心距离的平方和。
- silhouette scores 侧影函数验证数据集群内一致性的方法。
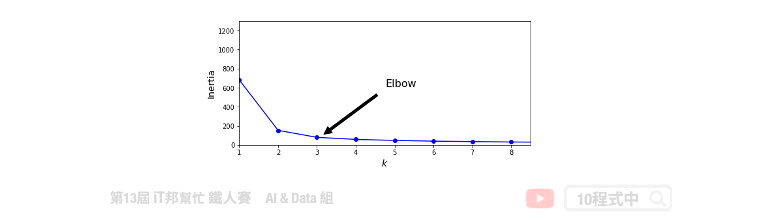
使用 inertia 做模型评估
当K值越来越大,inertia 会随之越来越小。正常情况下不会取K最大的,一般是取 elbow point 附近作为 K,即 inertia 迅速下降转为平缓的那个点。
# k = 1~9 做9次kmeans, 并将每次结果的inertia收集在一个list里
kmeans_list = [KMeans(n_clusters=k, random_state=46).fit(X)
for k in range(1, 10)]
inertias = [model.inertia_ for model in kmeans_list]
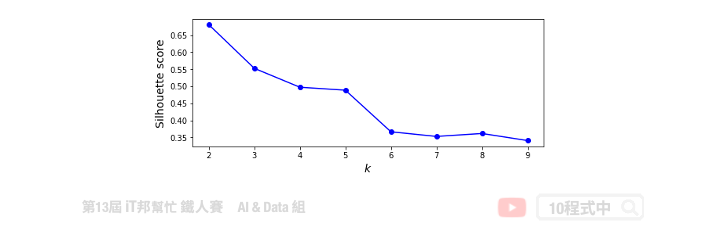
使用 silhouette scores 做模型评估
另外一个方法是用 silhouette scores 去评估,其分数越大代表分群效果越好。
from sklearn.metrics import silhouette_score
silhouette_scores = [silhouette_score(X, model.labels_)
for model in kmeans_list[1:]]
本系列教学内容及范例程序都可以从我的 GitHub 取得!
>>: 【Day 04】 Data Analytics Pipeline 对应於 AWS 中的服务 ( 2 )
Day24 Vue 认识Porps(3)
以物件做props的传递 我们先来看看一个例子! 在这里我们先用props把外层元件的data里的i...
ADXL335三轴加速度晶片结合Arduino nano传数据
小弟想询问 因为专题需制作一个透过硬体记步数的功能 如何将Arduino nano蒐集起来的资讯 转...
[Pytorch] torchvision.transforms()
torchvision.transforms() Transforms are common im...
JavaScript Arrow Function(箭头函式)
箭头函式 箭头函式功能与一般函式的用法大致差不多,不过写法却比一般函式还要简洁的多。 这里就直接来时...
模型的内容01
到此为止,若一切顺利,表示NNI安装正确,功能一切正常。但整个流程究竟在做甚麽事情呢? 首先,我们在...