[常见的自然语言处理技术] N-Gram Model 与关键字预测 (I)
前言
当我们在 Google 搜寻引擎输入 The most incredible 时,系统会推荐你高热度的关键字:
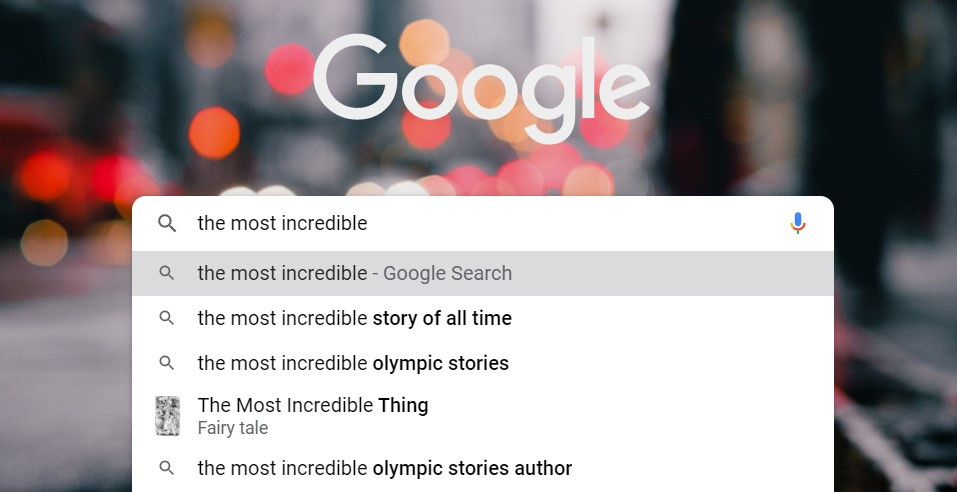
我们不禁产生疑问:系统是如何预测关键字的呢?
我们在前一回开头提到语言模型的定义为描述一个文字序列出现的机率分布,在昨天我们介绍了以单词出现在语料库中的频度作为预测准则的词袋模型( Bag-of-Words Model ),今天我们聊聊其他的统计语言模型。
根据输入的句子来预测下一个单词
图片来源:A Comprehensive Guide to Build your own Language Model in Python!

N元语法(N-gram Model)
试想,这个句子应该下一句会出现什麽单词?
「 Research shows that both having and deciding how to spend leisure time can be very ... 」
你认为出现 stressful 的机率有多高?[文字出处]
也就是说我们想知道如何估计机率值。
若我们考虑:
则我们将要计算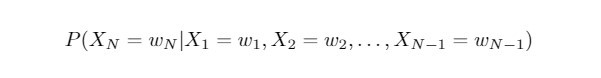
我们基於历史字串 "Research shows that both having and deciding how to spend leisure time can be very" 来预估当下输入的单词 "stressful" 的条件机率。在这里我们假设马可夫性质( Markov property )成立,亦即当下任何单词的出现,仅依赖於前一个单词。这无疑简化了我们的问题:
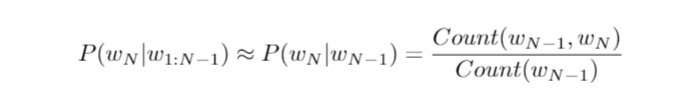
右侧的 Count() 指的是计算词组在语料库中的个数,分子为 "very stressful" 单词序列的个数,分母为单词 "very" 的个数,整体的比值则是 "very stressful" 一起出现的相对频率( relative frequency )。而计算词组出现的频率,则取决於语料库内单词或词组的个数。
不难发现,以上我们的文字预测,只关乎由两个单词所连成的字串,这种语言模型被称为二元语法( bigram model )。而上一篇我们所介绍的词袋模型,由於只采计单词出现的次数,与语序、语意、文法皆无关,即是一种单元语法( unigram model )。我们可以推广这个概念:若当下输入的单词,只与过去的 N-1个单词序列有关,则是为N元语法(N-gram)。以下我们将示范利用三元语法来进行文字预测。
词袋模型的难题
我们来看下列两个句子:
俄国人说: I love vodka but I hate gin.
英国人说: I love gin but I hate vodka.
我们将上面句子当作小型的语料库,并利用词袋模型来表示 gin 与 vodka ,由於两者出现的次数一致,向量化後的结果并无二致,因此必须选用 N≥2 的N-gram model。
小结
由於时间关系,今天我未能详细介绍 N-gram Models 的 Python 实际应用。明天我将会示范如何利用这个统计模型来进行文字预测,じゃあね!
阅读更多
>>: 【刷题平台】中英 LeetCode、HackerRank、CodeSignal、牛客网
Python - 安装 PyAudio 套件报错解决方式参考笔记
Python - 安装 PyAudio 套件报错解决方式参考笔记 参考资料 资料来源:I can't...
Day18 简易资料库RealmSwift小实作5
接续昨天~ 第四行id.count>0是做说明若是realm里的资料大於0比(因为阵列是从0开...
Ubuntu巡航记(3) -- Docker 安装
前言 Docker 是一种虚拟化技术,可以透过容器(Container)建立多个虚拟机,也可以将虚拟...
display:block及display:inline 差别
display:block及display:inline 差别 每个不同tag都会对应不同预设值设...
欢迎下载 PDF分解器 PDFdissector【免费】
欢迎下载本人自制 PDF分解器 PDFdissector【免费】 PDFdissector.msi ...