树选手1号:decision tree [python实例]
今天来用decision tree做一个预测肿瘤是恶性还是良性的应用,在这里就略过前期的资料处理与分割,直接从model应用开始,如果对这个分析有兴趣,我有把kaggle连结放在下方可以参考。
刚开始我先写了一个score function可以把model後续的训练和测试跑完,最後回传多种的准确率与Confusion Matrix来判断模型的好坏。
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
def score(m, x_train, y_train, x_test, y_test, train=True):
if train:
pred=m.predict(x_train)
print('Train Result:\n')
print(f"Accuracy Score: {accuracy_score(y_train, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_train, pred)*100:.2f}%")
print(f"Recall Score: {recall_score(y_train, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_train, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_train, pred)}")
elif train == False:
pred=m.predict(x_test)
print('Test Result:\n')
print(f"Accuracy Score: {accuracy_score(y_test, pred)*100:.2f}%")
print(f"Precision Score: {precision_score(y_test, pred)*100:.2f}%")
print(f"Recall Score: {recall_score(y_test, pred)*100:.2f}%")
print(f"F1 score: {f1_score(y_test, pred)*100:.2f}%")
print(f"Confusion Matrix:\n {confusion_matrix(y_test, pred)}")
我们先建立一棵树,参数完全使用原本预设的值,接下来看看training结果。
from sklearn import tree
tree1 = tree.DecisionTreeClassifier()
tree1 = tree1.fit(x_train, y_train)
score(tree1, x_train, y_train, x_test, y_test, train=True)

居然拿到了100%正确的预测,但testing的表现才是我们真正在意的,接下来看一下testing的结果,从回传的结果可以看出model似乎有些overfitting的问题。
score(tree1, x_train, y_train, x_test, y_test, train=True)

要如何解决decision tree overfitting的问题呢?主要可以从参数上来做限制:
1.max_depth(default=None): 限制树的最大深度,是非常常用的参数
2.min_samples_split(default=2):限制一个中间节点最少要包含几个样本才可以被分支(产生一个yes/no问题)
3.min_samples_leaf(default=1):限制分支後每个子节点要最少要包含几个样本
来用loop选择最适合的max_depth:
#decide the tree depth!
depth_list = list(range(2,15))
depth_tuning = np.zeros((len(depth_list), 4))
depth_tuning[:,0] = depth_list
for index in range(len(depth_list)):
mytree = tree.DecisionTreeClassifier(max_depth=depth_list[index])
mytree = mytree.fit(x_train, y_train)
pred_test_Y = mytree.predict(x_test)
depth_tuning[index,1] = accuracy_score(y_test, pred_test_Y)
depth_tuning[index,2] = precision_score(y_test, pred_test_Y)
depth_tuning[index,3] = recall_score(y_test, pred_test_Y)
col_names = ['Max_Depth','Accuracy','Precision','Recall']
print(pd.DataFrame(depth_tuning, columns=col_names))
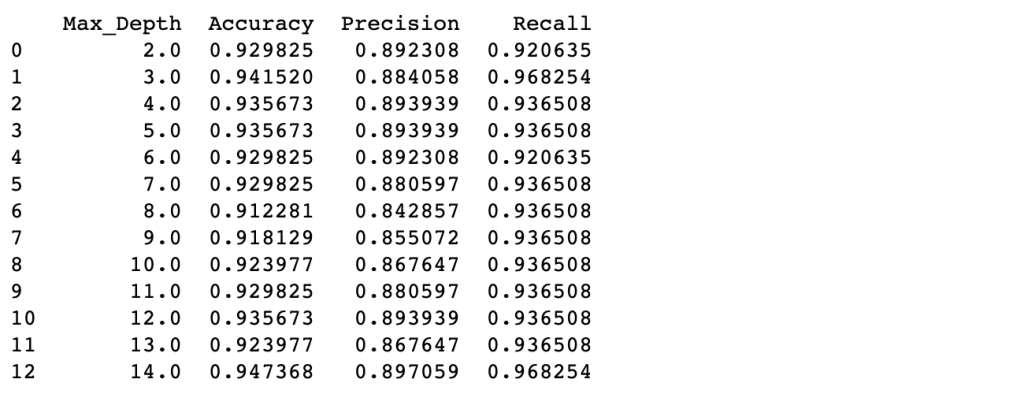
从上面的结果可以发现max_depth=3的时候就可以达到不错的效果,接下来建一颗新的树来看看:
tree2 = tree.DecisionTreeClassifier(max_depth=3)
tree2 = tree2.fit(x_train,y_train)
score(tree2, x_train, y_train, x_test, y_test, train=True)

score(tree2, x_train, y_train, x_test, y_test, train=False)

比起本来的树,设定max_depth=3之後可以获得更好的预测结果,tuning 成功!
reference:
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
http://www.taroballz.com/2019/05/15/ML_decision_tree_detail/
https://www.kaggle.com/nancysunxx/breast-cancer-prediction
<<: Day 02 - 行前说明 — 网页微切版架构 和 UI 元件
>>: Day 2 : Odoo = 免费且完整的ERP + 完善的开发平台 + 第三方的免费Addon + 多人参与的商城
[Day 9] 漂亮的输入框 TextField 文本框
Day 8 从Day8 fork一份开始 昨天提到了登入 才发现 文本框没有介绍到 可用於各项输入 ...
不只懂 Vue 语法:请示范如何使用 Vue 3 的 teleport?
问题回答 teleport 是 Vue 3 新增功能。teleport 就像是多啦A梦的「随意门」一...
Day34 ATT&CK for ICS - Impair Process Control(2)
T0856 Spoof Reporting Message 攻击者欺骗回传报告的内容,为了不让自己的...
StockAPI-错误讯息处理 (Day32)
先前我们建立的StockAPI在解析token字串时,并没有针对解析错误的情况去做错误处理,所以如果...
D21. 学习基础C、C++语言
D21. 题目练习uva350 #include <stdio.h> #include ...