图的资料结构
3 图的资料结构
今天来介绍我们储存一张图的时候,几种常见的资料结构:相邻矩阵(Adjacency Matrix)、邻接链结串列(Adjacency Linked List)、边列表(Edge List)。
3.1 相邻矩阵 Adjacency Matrix
意思就是一个二维阵列啦,其中 (i, j) 格子里面放的是「到底有没有一条从 i 到 j 的边」之类的讯息。
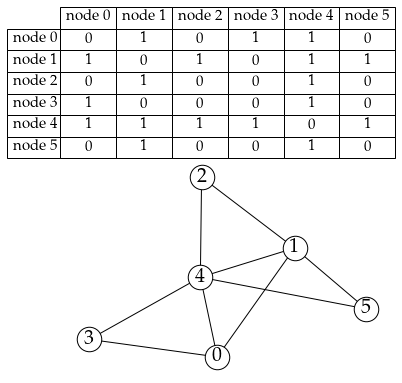
3.2 邻接链结串列 Adjacency Linked List
简单来说就是用链结串列记录下所有一个点的邻居。
嗯...用 networkx 画 linked list 感觉还是太勉强了哈,上面那张相邻矩阵画了好久...
3.3 边列表 Edge List
如果一条边很重的话,就让他们保持在输入时候的样子,此外我们再用一些指标来表示「这个点的下一条相邻边在哪里」之类的讯息,就可以有效率的存取罗。
3.4 选择障碍
大家可以先想看看这个问题:如果我要修改这个图怎麽办?如果我想要支援 "增加一条边" 和 "删除一条边" 的操作,使用哪种资料结构比较好?
一个粗浅的答案是:这取决於图的种类与不同操作的频率。考虑一个无向图,那麽当你增加一条边的时候,相较於边列表而言,可能要处理 A[i][j] 和 A[j][i],这可能牵涉到两次分页错误(page fault)。当你删除一条边的时候,如果使用相连链结串列,相较於相邻矩阵来说,可能得花更多时间找到那条要删除的边。
完美的资料结构并不存ㄗ
(这句话好像不是这样用的)
笼统地说,资料结构就是在电脑中储存资料的形式。但其背後蕴含的意思,则是结合了类似 API 和封装(encapsulation)的效果(可参考维基百科)。根据不同的使用需求,而修改或设计出相对应的资料结构,才会让演算法变得更有效率。
3.5 根据需求变更设计
如果我们所要解决的图论问题,其输入都有一定的特徵,那麽我们可以特化资料结构,并能实作出更有效率的演算法。列举一个简单的例子,通常我们使用邻接链结串列,是因为我们无法保证每一个点的度数(degree)有多少。然而,如果对於程序的运行有所理解的话,会知道存取链结串列这件事情,会让程序需要在记忆体中零散地存取多处,从而造成很多的快取失误,进而拖累程序的执行效率(虽然说现在大家都用 vector 了就是...)
假设现在我们考虑的图,是固定度数的(这类图我们称之为正则图 regular graphs),那麽我们在设计资料结构的时候,只需要预先帮每个节点开设好固定大小的空间,便能更有效率地存取这些邻接表格。
如果输入的图并没有一定的规则,但说不定能事先将之转换为固定规则的图,再存起来,也可以达到类似的效果。举一个例子来说,如果我们不确定一棵树里面,每个节点的孩子数量为何,我们可以把这棵树以左子右兄弟(left-child right-sibling)的方式,转换为一棵二元树,这样每个点的度数就不超过 3,此时也就能够用一个简单的 struct 就能描述一个节点了。
3.X 冷笑话
完全图和稀疏图谁的节点看久了会近视呢?答案是完全图,因为它们都是高度数。
>>: [Day3] 人脸侦测 (Face Detection)
自动化 End-End 测试 Nightwatch.js 之踩雷笔记:select option
相信 E2E 一定有做过遇到这种需要选择的部分,结构大致上会长这样 <select class...
谁温暖了资安部-赛後感想
谢谢iT邦帮忙,今年又办了iT邦帮忙铁人赛! 今年,比较特别,在看到官方的开赛日期、最後发文日期後,...
Python - Video to Ascii 影片转 Ascii 套件参考笔记
Python - Video to Ascii 影片转 Ascii 套件参考笔记 参考资料 Gith...
【Day6】窗涵式,n_fft ,hop_length 到底什麽意思啊?
回填之前的坑 在往 Vocoder 迈进之前,我们先回顾一下之前我们在做 melspectrogra...
IOS、Python自学心得30天 Day-5 TensorFlow 辨识图片
前言: 前面模型也都训练好了,接下来就是辨识的部分 程序码: 方案一遇到一点问题,就暂时不放上来了 ...