[第30天]理财达人Mx. Ada-货柜运价指数FBX
前言
本文说明使用scrapy爬虫函式库抓取海运FBX指数。
波罗的海货柜运价指数[FBX]
波罗的海货柜运价指数[FBX]
波罗的海货运指数(Freightos Baltic Index, FBX)是线上货运平台 Freightos、波罗的海交易所(Baltic Exchange)共同编制指数,反映亚洲、欧洲、美洲之间12条全球主要航线的40尺货柜现货运价,包括海运费及相关附加费(燃油附加费、旺季附加费、港口拥挤附加费、运河附加费等),不含进口关税、出发港/目的港之港口费用。FBX 指数在於其汇整国际货运承揽业 (freight forwarder) 商业资料库的实际价格,提供货柜报价的综合指数。
程序实作
安装爬虫程序函式库 scrapy
pip install scrapy
开启一个Scrapy专案
scrapy startproject crawlerFBX
建立好crapy专案後,即建立以下目录结构档案
执行scrapy genspider建立spider
scrapy genspider fbx_spider fbx.freightos.com
FbxSpiderSpider程序
於spiders目录下,建立抓取fbx.freightos.com之fbx_spider范例程序
import scrapy
import json
import matplotlib.pyplot as plt
import pandas as pd
class FbxSpiderSpider(scrapy.Spider):
name = 'fbx_spider'
allowed_domains = ['fbx.freightos.com']
start_urls = ['https://fbx.freightos.com/api/lane/FBX?isDaily=true']
def parse(self, response):
dict_day2FBX = {}
#使用body_as_unicode()方法处理unicode编码资料
jsonresponse = json.loads(response.body_as_unicode())
print("jsonresponse:",jsonresponse)
#解析Json存成dict
for item in jsonresponse["indexPoints"]:
fbxvalue = item["value"]
indexDate = item["indexDate"]
print("fbxvalue:",fbxvalue," indexDate:",indexDate)
dict_day2FBX[indexDate] = fbxvalue
print("dict_day2FBX:\n",dict_day2FBX)
#将字典( dict)结构转成DataFrame
df = pd.DataFrame(list(dict_day2FBX.items()), columns=['Date', 'FBXValue'])
df['Date'] = pd.to_datetime(df['Date'])
print("df:\n",df)
#绘图
df.plot(x='Date', y='FBXValue', figsize=(16, 9),color='red'); plt.legend(loc='best')
plt.ylabel("FBX Value")
plt.savefig("FBX.png")
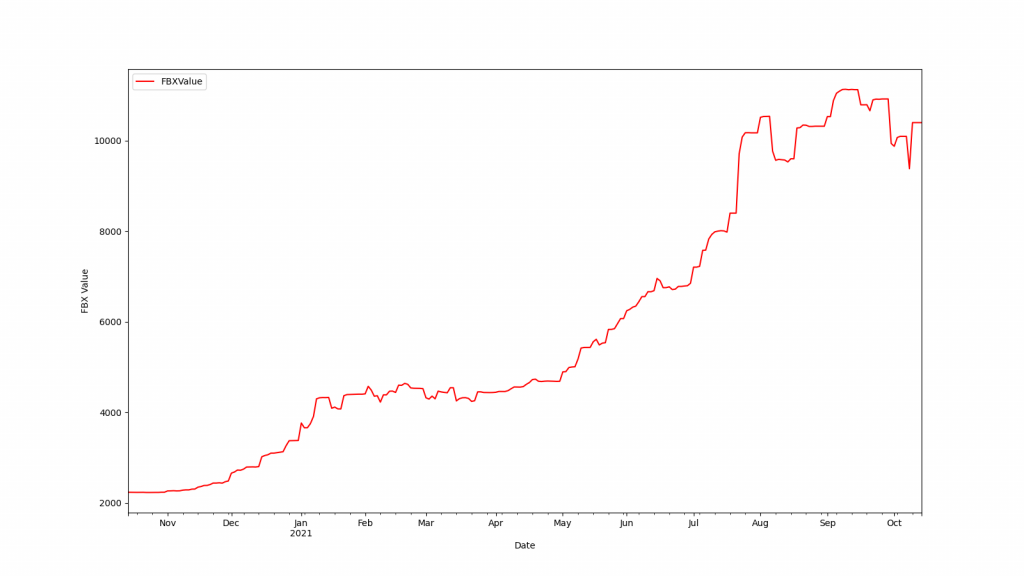
程序执行成果
scrapy crawl fbx_spider
小结
使用scrapy爬虫函式库抓取海运FBX指数及利用matplotlib函式库绘出成果。
>>: day30_arm 还是 x86? 我知道该怎麽选了
铁人赛 Day3 -- PHP 基本语法 & 常用的预设变数
PHP起手式 我PHP程序不写也在这之中,将会无法正确执行我们的程序码 <?php ?>...
创建App第一步
建立了全新的Xcard专案,并在Main.storyboard界面页中拖拉数个Image View用...
【Day 21】卷积神经网路(Convolutional Neural Network, CNN)(上)
Why CNN for Image? 我们在训练Neural Network的时候,我们会期待在这个...
React-使用JSON增加品项
这边的功能是为了想呈现网页中作品集这个项目 但是在作品集中又分了很多品项 像是平面、网页、插画等等....
Android学习笔记04
kotlin+mvvm+databinding+recyclerview 上一篇讲了一般kotlin...