网站不想你爬
这边想说一下,关於上一篇有讲到我利用superagent()来获得网站资讯,结果抓取失败。这是因为不一定所有网站都愿意其他人随便沿用自己的东西,所以在网站後台可以让人设定禁止令之类的,防止他人搜索。
那要如何知道网站是否同意进行搜索,可以在网址根目录後加上robots.txt就会看到文字档纪录,像是用户代理、禁止目录…等等。下面是我上一篇失败网站的文字档。
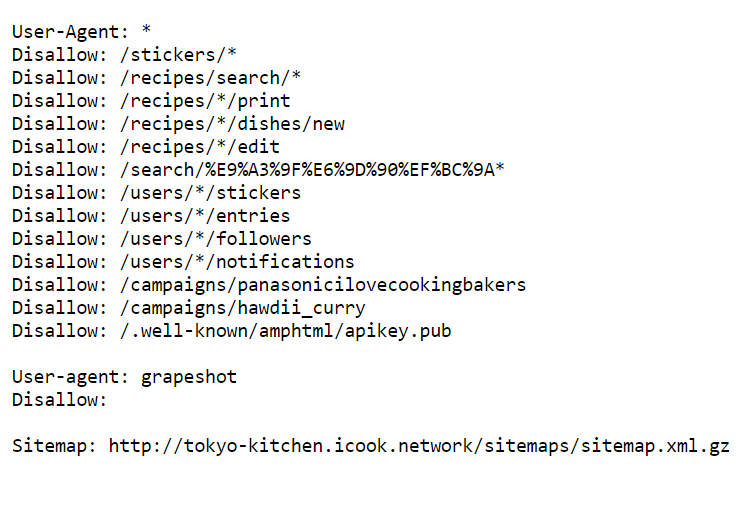
总而言之,就是禁止了很多东西,导致我抓取失败了!
之後我稍微补充下robots.txt的基本应用吧。
常见用词:
- User-agent => 对於那些搜索引擎生效
- Disallow => 禁止进入的目录,需指名路径
- Sitemap => 网站内sitemap档案位置,须完整路径
常见应用:
- 允许所有引擎检索
User-agent:*
Disallow: - 拒绝所有引擎检索
User-agent:*
Disallow:/ - 拒绝所有引擎检索/users/下所有内容
User-agent:*
Disallow:/users/ - 拒绝Google搜图检索/images/下所有内容
User-agent:Googlebot-image
Disallow:/images/
>>: 用React刻自己的投资Dashboard Day1 - 前言
【Day09】数据输入元件 - Upload
元件介绍 Upload 是一个上传元件。帮助我们能够发布文字、图片、影片、档案到後端服务器上。 参考...
Leetcode: 1627. Graph Connectivity With Threshold
打起精神来,今天有比昨天更好一点! 这题,我对他的解释是,现在有未知的图,我有些node跟node之...
Day28 Flutter—BLoC介绍(二)
MultiBlocListener MultiBlocListener是一个Flutter小部件,它...
[第06天]理财达人Mx. Ada-下单作业
前言 本文说明如何进行下单作业。 程序实作 # 设定交易标的 # 以台股上市股票:长荣 contra...
JavaScript 进阶笔记三(Primitive type VS Object type)
Primitive type VS Object type primitive 是不可改变的(Imm...