关於计算机,你必须知道的事: CPU 快取
本文目标
- 记忆体层接
- 介绍快取的组成
- 常见的快取机制
- 使用快取需要面对的同步问题
进入正题
CPU 的快取被设计来解决记忆体存取过慢的问题。

透过上图的记忆体阶层图可以发现:
- 越快的记忆体容量越小
- 离 CPU 越远,速度越慢
可能会有人问说: 那我干嘛不加大 Cache 或是 Register 的大小?
答案很简单: 价格太贵了。
笔者随手抓了一颗 CPU (Intel i7-8700k) 的资料来看:
- Size of L1 Cache: 384 KiB
- Size of L2 Cache: 1.5 Mib
- Size of L3 Cache: 12 Mib
Speed: L1 > L2 > L3
根据上面的数据就可以看出 Cache 大小大约是 MB 级,若要将大小扩充到 GB 级甚至是 TB 级,那计算机应该就是有钱人的玩具了。
以目前主流市场来看,记忆体为 GB 级,硬碟为 GB/TB 级。
回到开头,CPU 中的 Register 数量不多且容量更小,只能供 CPU 做运算,无法再提供其他用途使用(储存更多记忆体位址或是重要资料)。
若没有快取的设计,CPU 就需要反覆的读取记忆体 (RAM)以取得需要的资料。
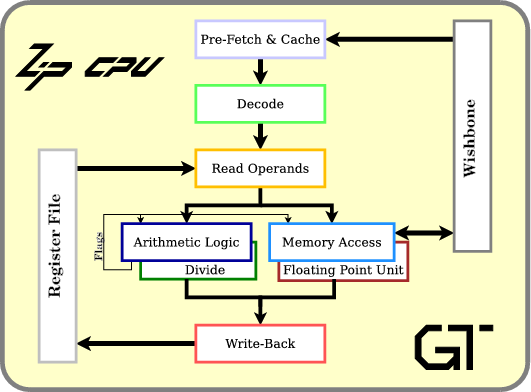
上图为处理器流水线的设计,方便下文解说。
至於 CPU pipeline 我会额外用一篇文章详细介绍。
有了 Cache,CPU 就可以在指令执行之前进行 data prefetch,将需要用到的资料事先取出来。不过,也因为 Cache 的成本关系,我们无法将所有资料都保存到 Cache 上。因此,下面也会提到 Cache 如何选择要存放的资料。
Cache 组成
- cache line
cache line 是 cache 的最小单位。
- cache set
cache set 则是 cache line 的集合,用程序来表示的话就像是这样:
cache_set = ["cache_line", "cache_line", "cache_line"]
- cache
cache = ["cache_set", "cache_set", "cache_set"]
Cache 的存取
因为成本上的考量,Cache 的大小都是有限的,所以要设计快取机制来决定哪些 Data 需要被快取。
Direct Mapped Cache
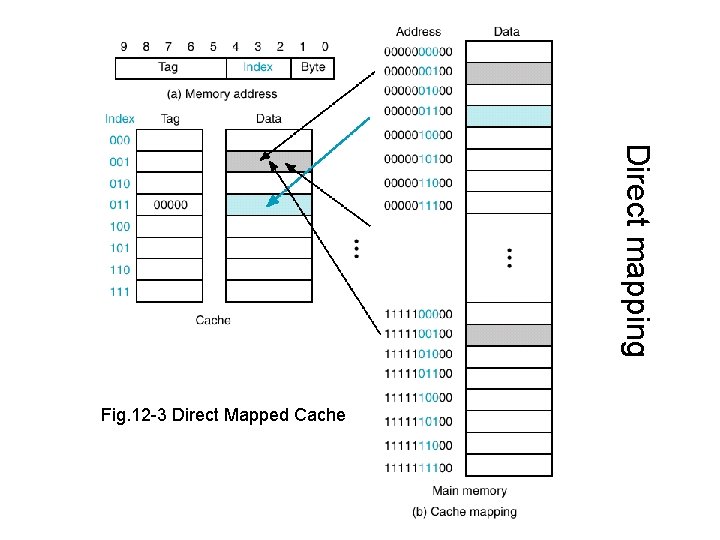
图片取自该连结。
Direct Mapped 的机制会将资料直接映射到 Cache line 上面,我们可以想像一下,一个班级有 1 - 50 号,所以 Cache 也分配了 50 个位置 (第一个位置只有座号为 1 号的同学能够入座)。
这时如果有 20 个班级,就有可能造成多个来自不同班级却同号码的学生争抢一个位置,让彼此不断的被替换出去。
Fully Associative
比起 Direct Mapped 的机制,Fully Associative 就简单多了,它会分配 50 个不需按照座号入座的位置,所以可以让不同班级座号相同的学生同时待在 Cache 当中。
不过这麽做的缺点也很明显,如果要寻找特定的同学,最差的情况下我们需要查找 50 个位置才能得知这位同学是否有入座。
N-way Set Associative Cache
Fully Associative 虽然可以避免掉同学之间不断换掉彼此的情况,却增加了查询的效率,为了改良这些缺点,电脑科学家提出了另一个方法 - N-way Set Associative。
该方法可以想成将 50 个位子拆分成 5 组,每组有 10 个位置,第一组可以让任一班级的 1 - 10 号同学入座,以此类推。
Cache miss
Cache miss 有三种情况:
- Compulsory misses
又称为 cold start misses,第一次存取未曾在 cache 内的 block 而发生的 cache miss,这种 miss 是不可避免的。
- Capacity misses
因为在程序执行期间,cache 无法包含所有需要的 block 而产生的 cache miss。发生在一个 block 被取代後,稍後却又需要用到。
- Conflict misses
发生在 set-associative 或 direct-mapped caches,当多个 blocks 竞争相同的 set,也称作 collision misses。
Cache 的替换策略
当 conflict misses 发生,有三种方法替换方法
- FIFO (first in first out, 先进先出)
将集合中最早进入的区块加以取代,实作上非常容易,不过也容易将重要资料替换掉。
- random (随机选取)
挑选集合中随机一个区块替换掉。
- LRU (least recently used, 最近罕用)
取代掉最不常用的资料,这种替换策略在实作上会比 FIFO 要来的复杂,但可以避免频繁使用的资料被换掉。
Cache 机制的其他应用场景
除了 CPU 中使用了 Cache,我们更可以在现今大大小小的资讯设备或是应用上看到 Cache 的影子,以作业系统的档案系统为例:
我们都知道磁碟的速度是非常慢的,如果所有资料都是等系统要用时才去磁碟上读取,整个作业系统的 IO 延迟会非常高。为了解决这个问题,作业系统端会在档案系统中实作一层 Buffer cache,将一些资料存放在 RAM 当中,至於替换机制就可以采纳 LRU 策略,让作业系统可以随时取得常用的资源。
Cache 这麽方便,有没有缺点?
Cache 的出现可以大幅度的提升处理器的效率,不过,在多核心的世代,Cache 也为资料的同步带来了一些麻烦。假设一颗处理器之中有 4 个实体核心,每个核心都有独立的 Cache,当复数个实体核心都 Cache 了一笔资料并对其做了修改,这样不就让资料发生非预期的运算结果了吗?
60 分的解法
谈到这边,学习过系统程序的同学可能会想到: 那我用 Lock 的机制保护这些资料呢?这样是不是就可以保护这些资料的正确性了?
如果你有这个想法非常好,不过换个方式思考,Lock 的实作也是仰赖记忆体变数做纪录,如果今天多个实体核心的 Cache 都保存了同一道锁的状态 (未上锁),这样不就又让复数个核心存取同一笔资料了吗?
机制完整的解法
谈到这边,会出现两种观众:
- 不了解 Lock 机制的人
- 理解 Lock 机制却不知道详解的人
这边就让笔者卖个关子,等到学习完作业系统的知识後再回头学习 Lock 与它的演进版本吧!
Reference
Day3.编译器运作流程介绍
编译器做了什麽? 我们知道使用机器指令撰写程序码是非常麻烦的事情,也会使开发程序的效率不高,编译器就...
Day21 - 铁人付外挂设定介面(三)- 自订栏位
先来回顾一下目前铁人付金流外挂的资料夹结构: iron-pay ├── composer.json ...
D16 - 那个圆圆的东西 - 物件原型 & 原型链
前言 Object.prototype.like = '舌尖上的JS' 请在任意的 JavaScri...
iOS APP 开发 OC 第六天, 面向过程&面向对象
tags: OC 30 day 什麽是面向对象? 实现需求之一: Ex:要如何将大象放入冰箱? 打开...
Day16 - Ajax 加上 Antiforgery Token (一)
这篇内容延续上一篇的部份,来加上 Antiforgery Token 的给定及验证 ! Case01...