Day03 - 端到端(end-to-end)语音辨识
在前一天的最後有提到说透过类神经网路(DNN)使得从输入端到输出端只透过一个模型就完成语音辨识,像这样的方法我们称作端到端(end-to-end)。目前常见的方法有 Sequence to sequence (Seq2seq) 和 Connectionist Temporal Classification(CTC)。
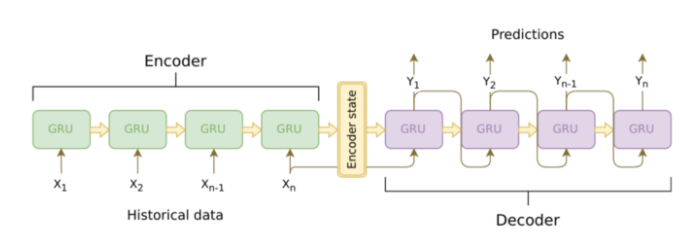
Seq2seq 顾名思义就是输入一个序列,模型会输出另一个序列,这种模型架构最重要的地方在於输入序列跟输出序列的长度是可变动的。Seq2seq 模型主要包含了 encoder, decoder ,因此也被称作 encoder-decoder framework,基本架构如下图:
Seq2seq 架构图,图片来源: https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/
Encoder 与 decoder 通常会采用递回神经网路(RNN)的架构,以上图的例子就是采用 GRU (Gate Recurrent Unit)。
Encoder 是负责处理输入的序列转换成机器能够理解的 encoder state (也被称为 context vector, thought vector),而decoder 再将 encoder state 解码成最後预测输出的文字序列。
context vector 可以理解成是一个包含所有输入序列讯息的向量并且负责 encoder 与 decoder 之间讯息的传递,在实际神经网路的运作过程中,context vector 也就是 encoder 中的最後一个 hidden state (如上图encoder最後一个GRU的输出)。因此 encoder 会将输入序列转换、压缩成固定长度的 context vector。但如果输入的序列的长度较长的话,固定长度的 context vector 所产生的辨识效果就会变差,为了解决此问题,研究人员研究出了注意力模型 (attention model)。
今天的内容就到这边了,明天将会来介绍注意力模型(attention model)。
成衣裁剪计划
前一篇的裁剪计划使用Excel设计, 现已将其系统化, 由系统安排裁剪计划并开立开裁通知单 不习惯看...
Day15 互动式CSS按钮动画(下)
由下向上填满 HTML <div class="shape-ex6">...
Day4 参加职训(机器学习与资料分析工程师培训班),记录学习内容(6/30-8/20)
上午: 人工智慧AIoT资料分析应用系统框架设计与实作 初步介绍网站,WWW的历史以及各个浏览器的演...
[Day22] 网格交易机器人-报价接收
首先先在StockPrice以外,新增Bid和Ask,还有Lock(多线程读写资料避免打架的工具) ...
Swift 新手-使用者介面(UX/UI/Core)
什麽是使用者介面? 使用者介面是介於使用者与硬体而设计彼此之间互动沟通相关软件,目的在使得使用者能够...