Day7-AI Performance
原文写於2019如无法执行请阅读官方文件
2. Label and Label Selector
接下来是Label 透过Label我们可以将IO强大的节点分配给Data Base,拥有众多计算能力的节点分配给AI系统,具体来说我们可以创造一个Label:GPU=K80并把它贴在有K80 GPU的节点上,并在我们Deployment,Statefulset的yaml中添加Label Selector加上GPU=K80字段,那POD运行时K8s系统就会帮我们把POD分配到有Label:GPU=K80的节点上,如果是使用Spark官方提供的bin/spark-submit方法只要在参数加入--conf spark.kubernetes.node.selector.GPU=K80即可。
步骤A:
在IAM申请GPU配额,申请後约1~2个工作天就会收到GCP回应
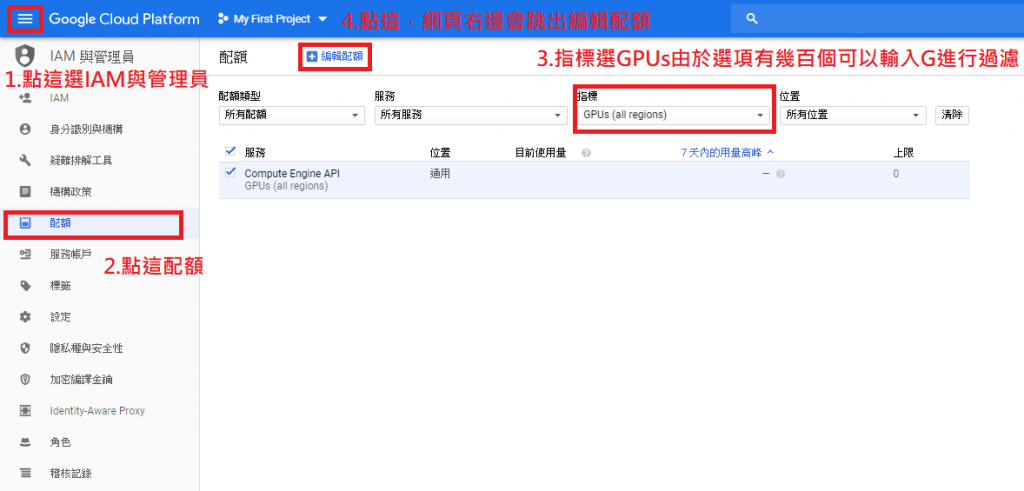
步骤B:
在GKE选GPU加速运算,并点击更多选项,请注意并不是每个区域都有支援GPU运算
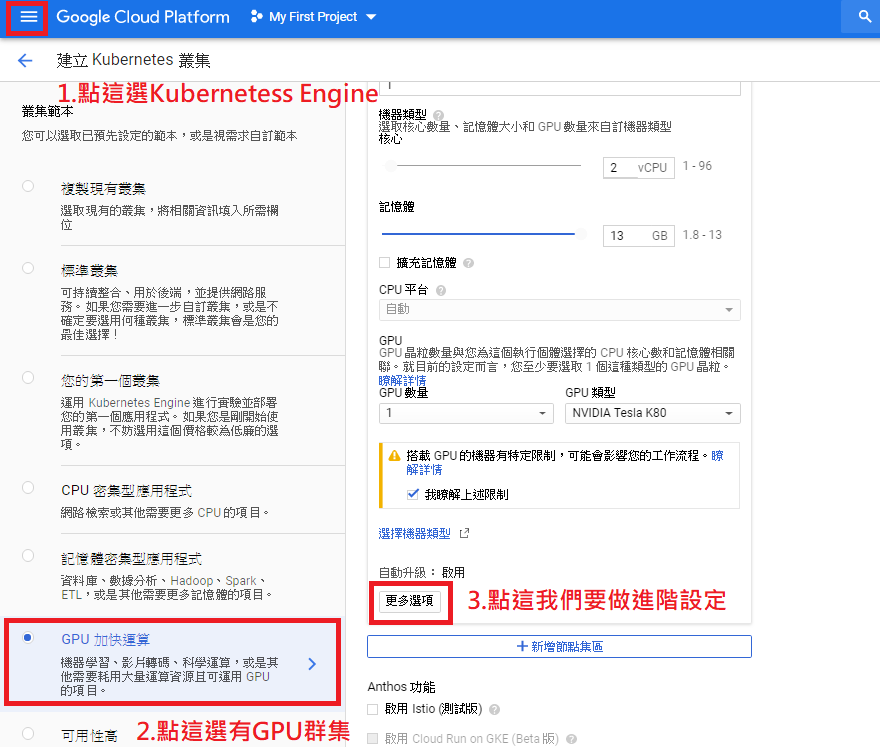
步骤C:
帮节点贴上GPU=K80标签Label
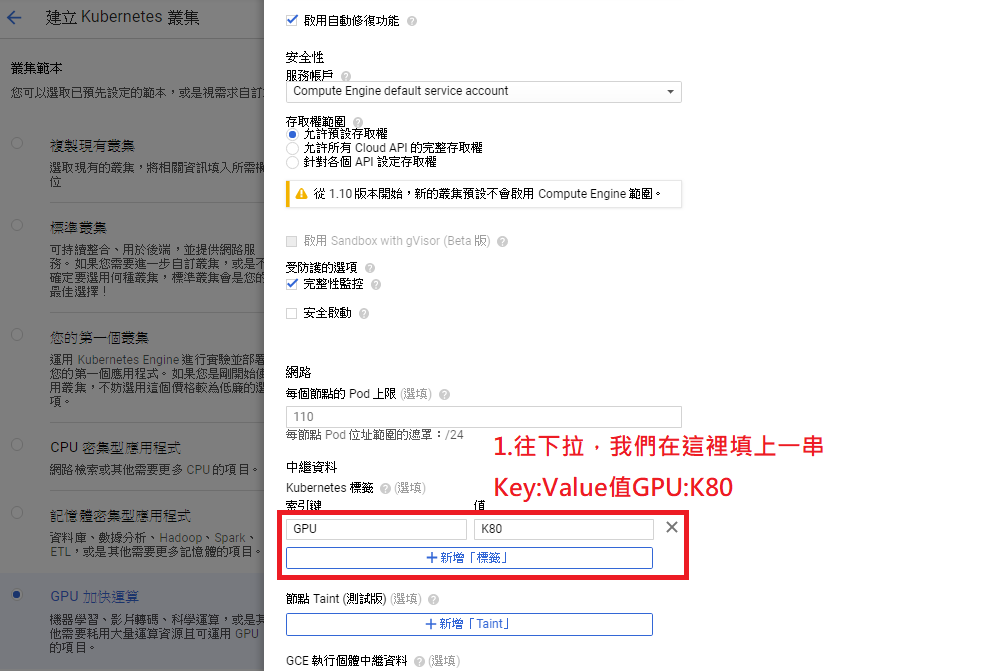
步骤D:
进入Terminal下kubectl get node会看到两个node,其一叫gpu-pool是包含gpu的K8s节点

步骤E:
使用kubectl describe node <node-name>就可以看到node贴的标签
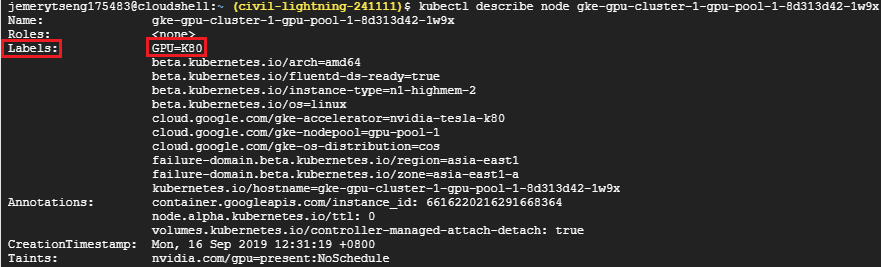
步骤F:
在spark-submit加入--conf spark.kubernetes.node.selector.GPU=K80,这样K8s就会把spark-executor布署到GPU节点比用Apache Yarn做简单很多吧!
bin/spark-submit \
--master <Your K8sMaster IP> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.executor.request.cores=10m \
--conf spark.kubernetes.executor.limit.cores=50m \
--conf spark.kubernetes.namespace=spark-intern \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-intern \
--conf spark.kubernetes.node.selector.GPU=K80 \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
步骤E:
执行後你会发现Task卡在Pending,这是因为GCP预设有帮GPU节点打上污点,为什麽GCP要这样做呢?与污点的原理/用途?之後会说明,因为Spark官方参数还没支援污点容忍Tolerations技术所以我们先用去除污点的方法

kubectl taint nodes <gpu_node_name> nvidia.com/gpu-
nvidia.com/gpu是key值,而後面-代表删除污点

kubectl get pods --all-namespaces

接着我们用echo $(kubectl describe pods <spark-pod-name> -n <namespace-name> | grep Node:)看Task是否真的跑在GPU节点上

运算时间就不写了,毕竟只有图类演算法在GPU上才会有比较好的效果,这篇只是在示范开头说的如何透过label将算力强大节点分配给特定计算型Task。
Day 30-完赛心得
实作成果: (今过长时间的debug终於成功了 ) 不知不觉就30天了 从一开始的不适应,到现在习惯...
Day 14 - 函式拌饭
简介 今天会像是笔记一样QQ,但是就是有关函式的知识! Scope of variable (变数生...
Day 24 深度学习与人工神经网路
介绍 随着时间过去,面对资料量的增加与电脑性能日新月异,深度学习的技术逐渐慢慢取代了机器学习。我们先...
赌场也有打烊的时候 - 盘後回测
写好 tick 交易策略之後,需要回测一下当天的买卖进出点是否正确 ticks = api.tick...
Day 21 - 物理模拟篇 - 原生Canvas建构粒子系统 - 成为Canvas Ninja ~ 理解2D渲染的精髓
在开始之前,我可能需要先给各位科普一些基础的CG动画(Computer Graphic)常识~也就是...