AI ninja project [day 14] 文字处理--分类
由於公司中的长官想要看BERT的模型介绍以及使用方式,
因此,文章介绍的航行方向由时间序列预测,先改变为文字上的处理。
参考页面:https://www.tensorflow.org/tutorials/load_data/text?hl=zh_tw
官网的攻略有分成两个范例,我只会参考第一个范例。
第二个范例为用不同荷马诗词的翻译作品,
来预测是哪一位作家翻译的作品。load资料时使用tf.data.TextLineDataset()来载入巨型的资料,
并且使用词频的概念来进行预测,有兴趣可以自行参观一下。
在字词量不是很大时,可以使用One Hot Encode 的方式来将文字转换特徵:
原始资料
['cold' 'cold' 'warm' 'cold' 'hot' 'hot' 'warm' 'cold' 'warm' 'hot']
变成
[[ 1. 0. 0.]
[ 1. 0. 0.]
[ 0. 0. 1.]
[ 1. 0. 0.]
[ 0. 1. 0.]
[ 0. 1. 0.]
[ 0. 0. 1.]
[ 1. 0. 0.]
[ 0. 0. 1.]
[ 0. 1. 0.]]
但字词量如果变多了,要运算的特徵会变成巨大的稀疏矩阵,
耗费效能,造成效率不够快。
这个时候我们可以将文字转为向量,进而进行运算。
由於运行的环境采用tf-nightly 2.7.0的版本,因此使用官网攻略提供的colab,
来执行程序:
https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/load_data/text.ipynb?hl=zh_tw#scrollTo=sa6IKWvADqH7
载入模组:
下载资料集
可以发现资料集已经区分了训练集以及测试集
这里要解决的问题是依照stack_overflow问题的文章内容,
来预测想要解决的程序语言为哪一个类别。
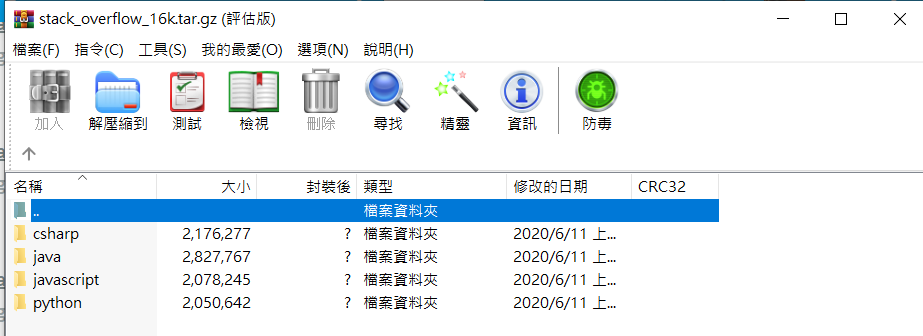
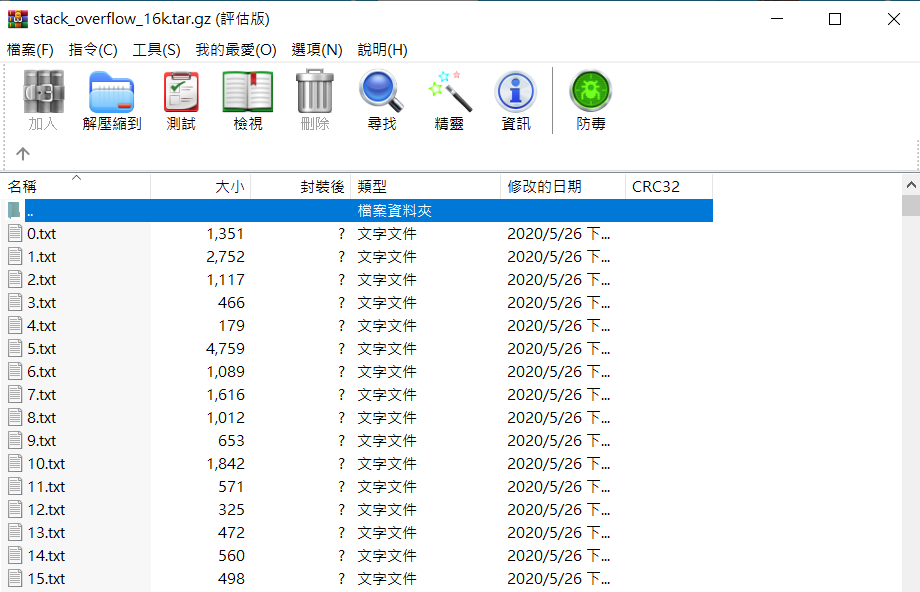
训练集及测试集依照标签(程序语言)来放置文章:
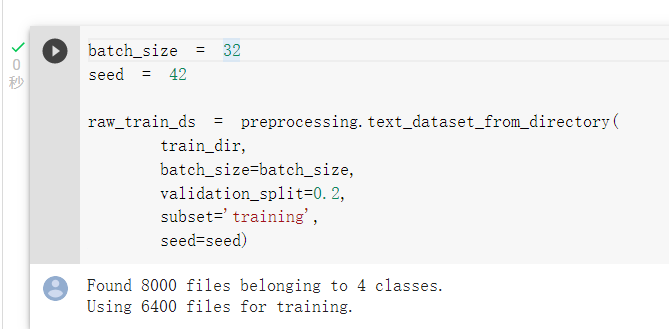
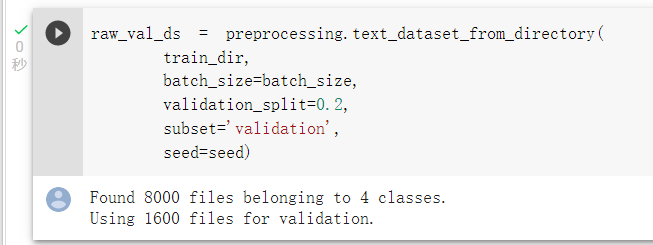
使用preprocessing.text_dataset_from_directory(),
来载入并且区分训练集及验证集:
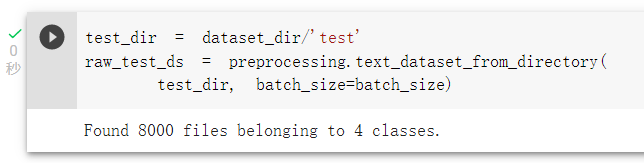
载入测试集:
这里官网提供两种将文字转换为项量的方法:
第一种:词袋法(特徵转换为0或1的数值)该前处理层

第二种:转换为整数数值向量 该前处理层

前处理层可以帮我们完成去除标点符号,断词,统整向量长度(以前还要自己padding,现在不用了),
将文字转向量,简单来说就是把工作全包了。
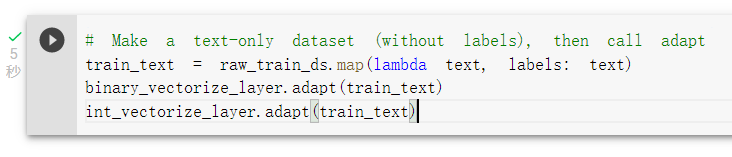
将前处理层适应训练特徵(这步很重要,否则训练完模型表现会很差)
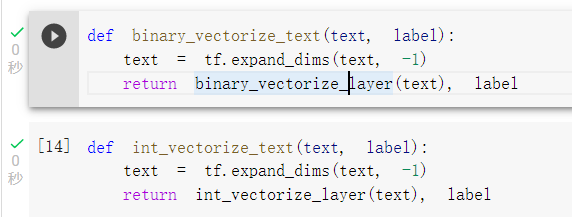
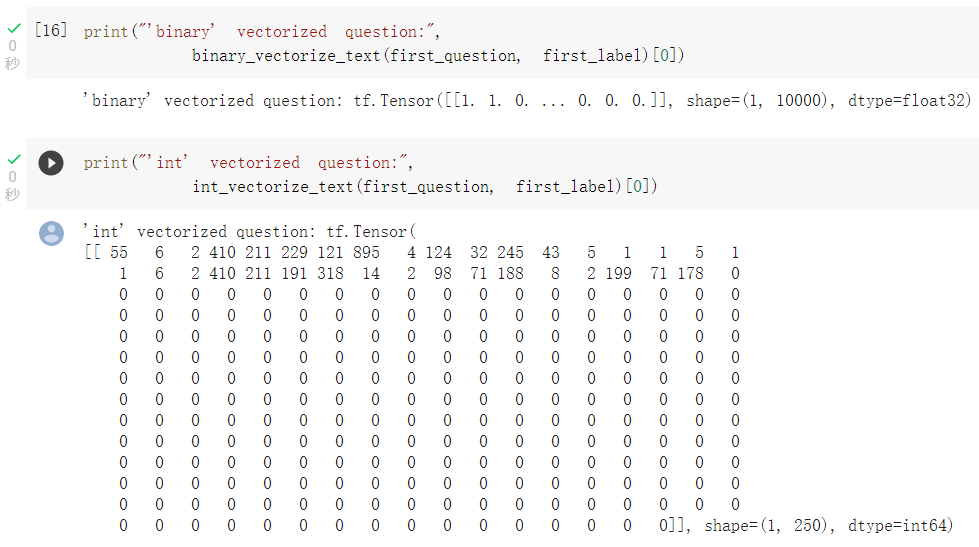
可以查看不同转换法,转换出来的向量格式:
将训练、验证、测试集都套用上方的function来转换为向量:

使用缓存资料来加速训练的速度:

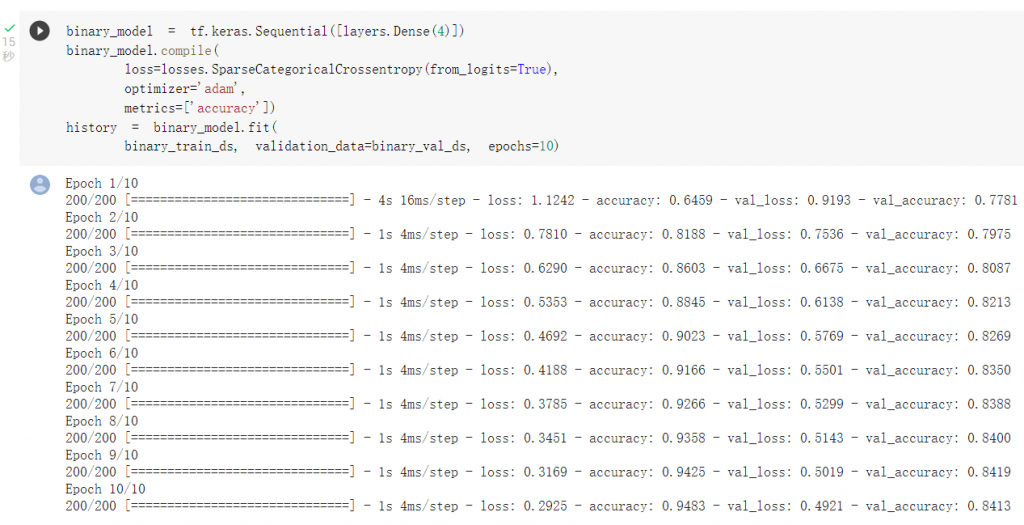
使用词袋法模型进行训练:
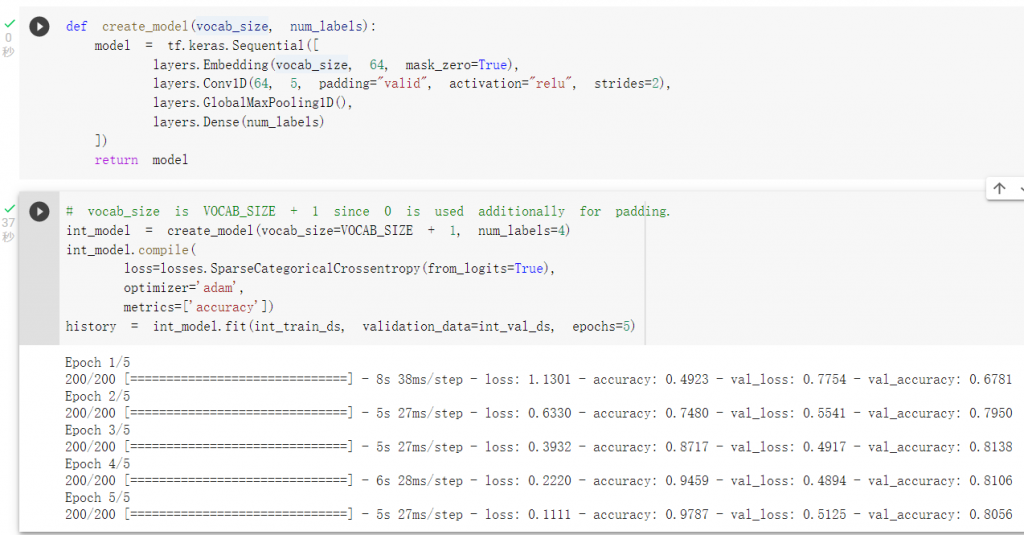
整数数值模型训练:
可以比较两种模型的准确度:
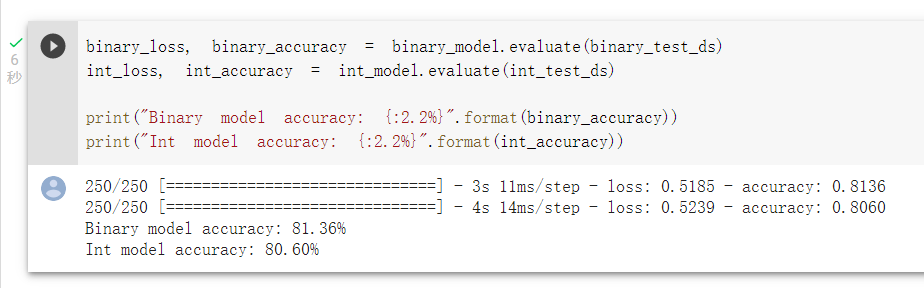
虽然词袋法准确度较高1%,不过我以前的经验比较少看到以词袋法来建模的应用。
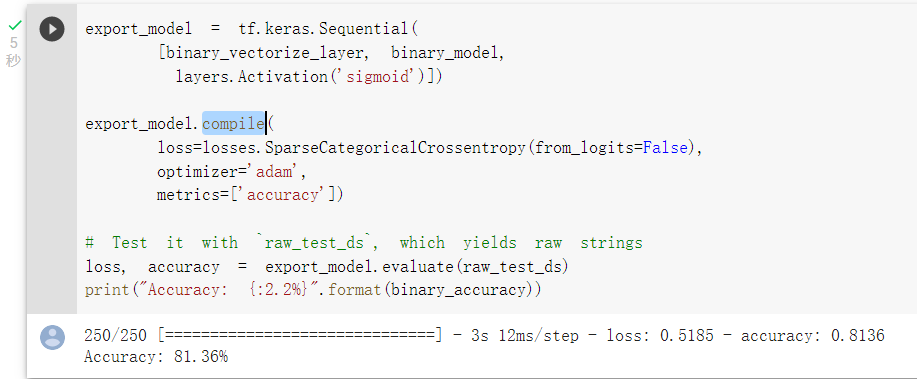
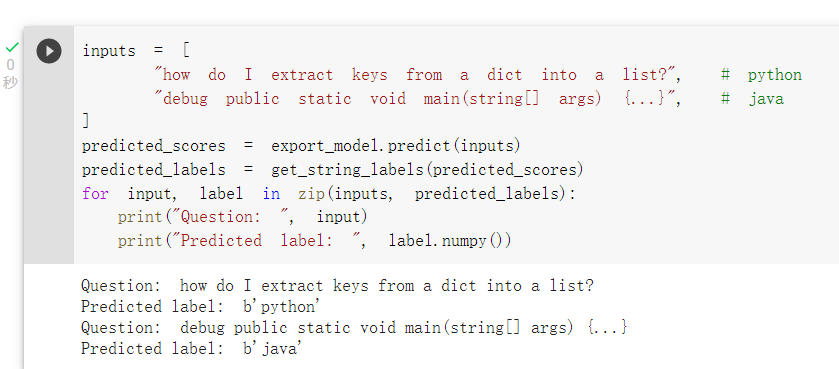
那我们可以将前处理层compile进模型,export_model可以供未来使用:
未来进行预测:
<<: MultiThreading and Custom extension function.
>>: 【Day14】利用Ezyme来跑个小小测试,还有..测试权衡是虾咪东东 (•ө•)!!?
KSP 的实作方向
这系列的文章不会讲完全部 KSP 的实作,毕竟我也还正在实作中,不过实作的方向应该是跟前几篇讲的差不...
Day 0x1E UVa11321 Sort! Sort!! and Sort!!!
Virtual Judge ZeroJudge 题意 真.排序题 输入数字,按照要求输出排序後的结...
【左京淳的JAVA WEB学习笔记】第六章 档案上传
档案上传与一般表单提交的格式不同。 一般表单提交默认enctype = "applicat...
第48天-学习 crontab 工作排程
今天进度 鸟哥私房菜 - 第十五章、例行性工作排程(crontab) 我在 Crontab.guru...