[Day 12] 资料产品生命周期管理-加工资料(一)
加工资料泛指各种处理资料的行为,这部分要一篇文章写完真滴难,所以就也只能蜻蜓点水的各介绍一点,让大家有个整体的概观。
Initiate
在启动阶段,目标当然是弄清楚需求,但也不只弄清楚需求而已,还需要确认「如何」达成需求,以及「是否有可能」达成需求。这时候建议找齐三类人才有办法讨论:
- 资料需求方 - 泛指需要更上层资料产品的人,像是资料分析建模、需要资料作辅助决策、或是需要自动决策的人。
- 资料提供方 - 资料提供方通常是原始资料的提供者,这些人通常不太知道资料後续可以如何被应用,但也需要他们了说明原始资料的细节,熟悉原始资料的人也可以判断有没有相关的资料可以提供。
- 资料加工方 - 指实际上处理资料的人,可能包含资料科学家或资料工程师,这些人长期处理资料需求与原始资料之间的转换,会更熟悉哪些问题可以用哪些资料来处理、以及考量转换之间的技术问题。
Design
在设计阶段,就需要资料工程师来将原始资料「转换」成可以被後续利用的样子。我们通常会透过「ETL」或「ELT」的方式来处理资料。
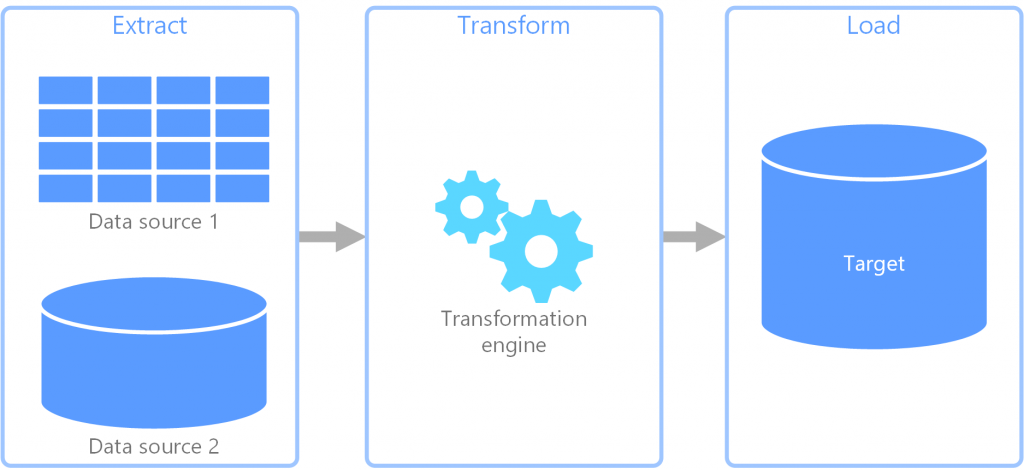
(https://docs.microsoft.com/zh-tw/azure/architecture/data-guide/)
- Extract: 把资料从某个地方拿出来。
- Transform: 将资料作转换。
- Load: 凑数的一步,把转换完的资料丢到某个地方。
以下提供几个比较常见的设计模式:
标准的清理资料流程
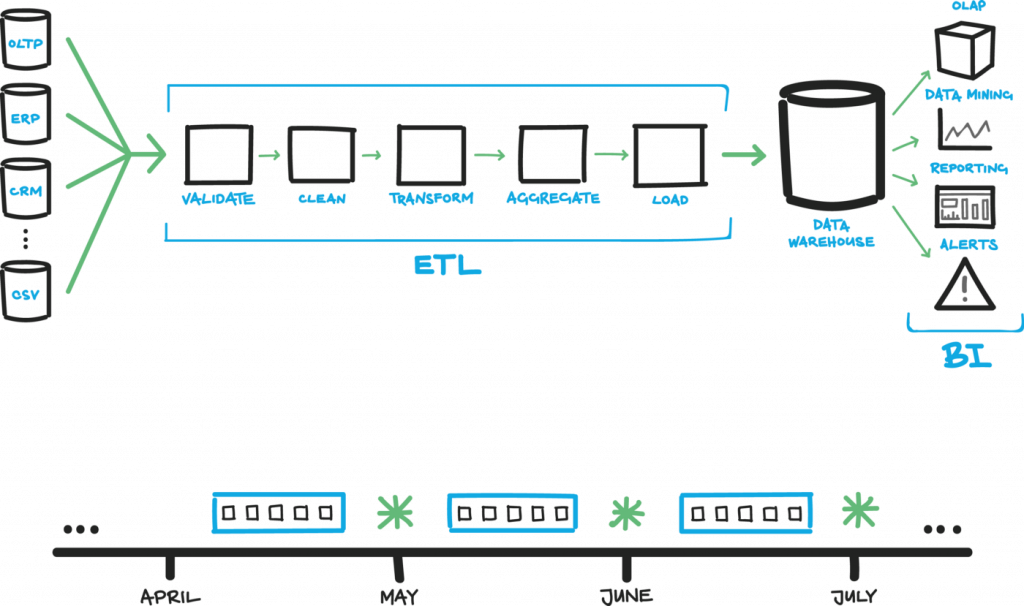
一般来说,资料在进入 Data Warehouse 前,都必须经过这几个阶段,才能供後续业务报表或是视觉化使用。算是基本起手式吧。
在不同层(Layer)的资料之间作转换
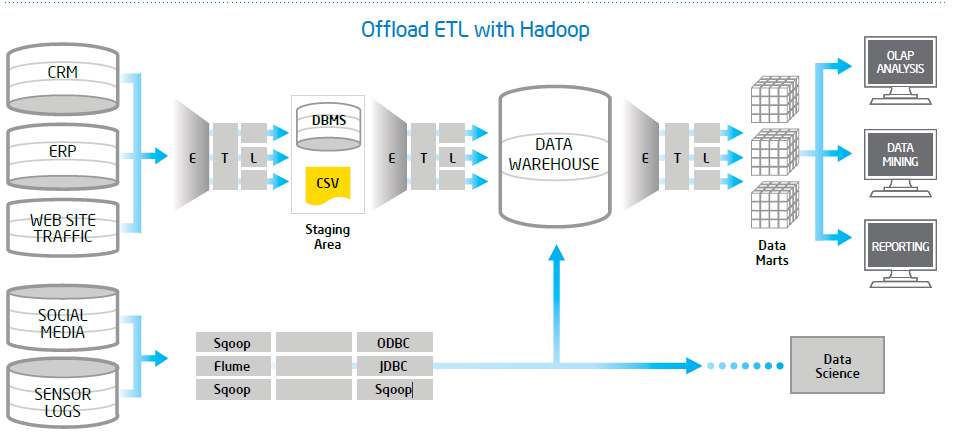
(http://letstalkhadoop.blogspot.com/)
资料传送到後端後,会经过 ETL 放到 Staging 环境、再透过 ETL 放到 DW、再透过 ETL 整理到了 Data Mart 给 End User 使用。当原始资料越复杂、资料量越多,中间就更需要多层次的处理来确保资料品质以及使用上的效能。
Streaming ETL
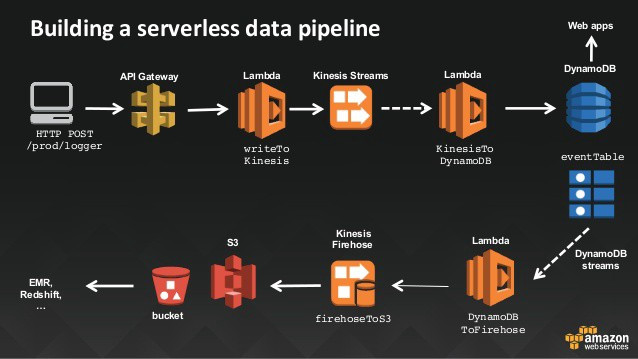
(https://www.slideshare.net/JulienSIMON5/serverless-architecture-with-aws-lambda-june-2016)
当然除了 Batch ETL 外,Streaming ETL 也是有的。可以根据事件、或是 mini batch 的方式来处理原始资料,配合 Batch Process 来处理累积的资料。
总之 ETL 是个很广泛的领域,不仅仅是「资料处理」四个字而已。还需要考量到软硬体架构、商务逻辑、後续的使用才能设计最适合的 ETL 流程。
系统设计
跟任何一项开发一样,在实作 Data Pipeline 之前,一定要先确认需求。而且因为资料有重力(Data Gravity),千万不能只满足当下需求,更要再多想一点点。
以下就提几点在设计 Data Pipeline 架构时,通常需要考量的点:
资料延迟性
这边的延迟性是只说从收到资料到处理资料需要多久时间、可以容忍多久的延迟?这会影响到资料需要做即时处理还是批次处理?例如硬体系统的监控资料、或是线上使用者人数可能需要即时,或至少五分钟内的资料。如果像是每天看的 BI 报表,需要等前一天的资料都收完才能计算的,处理频次就是每天一次,相对来说也可以容忍比较大的延迟。
资料精准性
在计算资料时,需要到多精准?例如银行的金额就没有容许误差的可能;但是像是线上即时使用者数、或是推文数就多少有误差的空间。那另外像处理即时资料时,要求是「最少一次」还是「仅此一次」?对於资料先後顺序有没有特别要求?如果使用者每天需要 Aggregate 一次资料,那原始资料中每条资料的先後顺序或许就没有太大影响。
系统的高可用性
一般来说越接近资料源的「资料收集」系统,越注重高可用性。因为最源头的资料一但掉了就GG了。必须让原始资料尽早落地,才能安心做後续资料清洗或计算等开发。
其他维运面考量
-
系统能不能支援版本回滚?
资料处理逻辑有时候难免会更新,如果错的话能不能快速回滚的之前的版本重跑资料? -
纪录任务进行时间
能不能量测每次的时间,如果有天处理时间异常增加能不能发送告警? -
防止错误资料进入正式环境
资料处理有件有趣的事情是,即便程序逻辑正确,也不代表商业逻辑正确。通常一个新上线或是新修改後的资料处理程序,不会马上将结果导入正式环境中以免污染当前的资料。如何透过环境设定切割来做到这件事,後面会有专文讨论。 -
资源监控
能否简单监控甚至预测所需资源? -
易於开发/部署
开发 Data Pipeline 系统的人,和之後使用 Data Pipeline 建立任务的人可能是不同的两群人(例如系统架构师开发系统、之後交由资料工程师建立任务)。那这套系统使用的语言能不能符合之後使用者主要的开发语言?或能不能允许其他语言来使用(例如 Python 或 Shell Script)。 -
自动化的维运工具
Data Pipeline 系统和其他任何软件系统一样都需要维运,越自动的维运机制以及越完整的自我修复功能,都能大大降低未来的负担。
<<: JavaScript入门 Day07_如何使用字串2
>>: Day 0xB UVa948 Fibonaccimal Base
[13th][Day4] defer fallthrough
defer 延迟执行 Golang 有个很方便的东东:defer,他执行的时间点会是在离开目前的 f...
【DAY 4】 Power Automate 简介 + 订便当系统
哈罗大家好~ 今天要简单说明 “ Power Automate “ 这个强大的流程引擎以及示范一个用...
Day13 流程控制之条件判断
了解流程控制 PHP程序设计中,很重要的环节就是条件判断! 条件判断能根据不同的情况执行不同的程序码...
Day 24 Password Attacks - 密码生成器 (Wordlists, CeWL, Crunch)
前言 为了破解密码,我们必须尝试很多可能才能找到正确的密码。当攻击者使用数千或数百万个单字或组合来破...
用 Python 畅玩 Line bot - 16:Flex Message(三)
接续上篇,继续介绍可以添加的区段,重复的部分将会略过。 2. Text text 任意文字符号皆可以...