DAY12 特徵工程-资料化约(特徵选取)
特徵工程可以分为两大部分,一是根据现有的资料特徵进行筛选,选出较有影响力的特徵进行训练,另一个是根据现有的资料特徵,去衍生出资料集中没有的特徵来让模型学习。今天我们会将重点放在前者。
有时候一个数据集可能可以蒐集到海量的特徵资料,例如一个实验往往有上百个感测器(Sensor)在记录资料,但那麽多的特徵不见得对模型的训练有帮助,甚至还会造成过度拟合(Over-fitting)问题,因此我们今天介绍特徵选取,来对资料进行化约,保留重要的特徵。
一、特徵选取(Feature Selection)
特徵选取是依据所订定的特徵衡量条件,删除不相关的特徵或属性,以选取用於分析资料最佳特徵的过程,使用特徵选取的目的与时机有以下几点:
1. 用少量的变数/特徵来保有原有的重要资讯
2. 当变数/特徵个数(# of p)远大於样本数(# of n)
3. Avoiding Curse of Dimensionality (避免维度灾难)
其操作步骤依序为:

下面我们介绍几种特徵选取的方法,并运用套件sklearn.feature_selection 里的函数来实现。
二、过滤法(Filter)
过滤法是列入一些筛选特徵的标准,检测与目标变数相关的特徵,挑选出具变化性以及中高度相关的特徵,方法包含:
▲移除低变异数的特徵
什麽是低变异数的特徵呢?就是一些资料几乎没有变化的特徵,像是:
常数特徵(Constant Feature):一个特徵下的值完全一样,没有变化。
from sklearn.feature_selection import VarianceThreshold
constant = VarianceThreshold(threshold=0)
constant.fit(x_train) #fit我们的资料集
# 得到常数特徵的栏位
constant_columns = [column for column in x_train.columns
if column not in
x_train.columns[constant.get_support()]]
print(constant_columns)
半常数特徵(Quasi-Constant Feature):特徵里大部分都是同一个数值。
# 设定门槛,要删除几%的资料
threshold = 0.95
quasi_constant_feature = [] #用来记录的list
for i in x_train.columns: #每个特徵依序看
# 计算比率
predominant = (x_train[i].value_counts() /
np.float(len(x_train))).sort_values(ascending=False).values[0]
# 假如大於门槛 加入 list
if predominant >= threshold:
quasi_constant_feature.append(i)
print(quasi_constant_feature)
重复特徵(Duplicated Feature):资料集有两个以上完全一样的特徵。
# 转置特徵矩阵
train_features_T = x_train.T
#找出重复的栏位
duplicated_columns = train_features_T[train_features_T.duplicated()].index.values
print(duplicated_columns )
▲单变量特徵选取
利用一些判断指标来衡量变数与目标变数之间的关系
挑选方法
● SelectKBest:选取 K 个最好的特徵,k 为参数,代表选择的特徵数。
● SelectPercentile:选取多少百分比的特徵,percentile 为参数,代表百分比,用 10 代表 10%。
卡方检定(Chi2)-用於离散型目标变数
以铁达尼号资料集为例:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#离散型资料要先转成数值
x=_train_df[['Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'IsAlone','Cabin']]
y=data['Survived']
x_new = SelectKBest(chi2, k=2).fit_transform(x, y) #挑选2个最好的特徵
display(x_new)
f_regression-用於连续型目标变数
假设预测股价
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
x=data[['前一天价格','前一季价格', '前一年价格','同性质股票价格']]
y=data['Price']
x_new = SelectPercentile(chi2, percentile=50).fit_transform(x, y) #取前50%的特徵
display(x_new)
三、包装法(Wrapper)
是一种特徵选择和演算法训练同时进行的方法,根据某一种评量标准,每次选择某些特徵或排除某些特徵,常用的方法为递归特徵消除(RFE)。
RFE是根据问题为离散或连续,利用机器学习的模型进行挑选,为一贪婪优化演算法,目的在找寻最佳的特徵子集。
RFE
#RFE
from sklearn.feature_selection import RFE
rf = RandomForestClassifier()
rfe = RFE(rf, 6) #筛选6个特徵
rfe.fit(X_train, Y_train)
print(f"Number of selected features: {rfe.n_features_}\n\
Selected Features:", [feature for feature, rank in zip(X_train.columns.values, rfe.ranking_) if rank==1]) #列出挑选的6个变数
以铁达尼号资料集为例,我们找到以下6个特徵
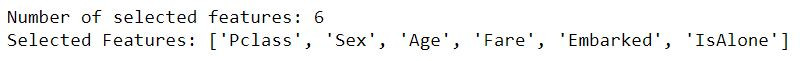
Stepwise Selection
运作方式为:一开始模型有全部k个变数,一个接一个从k个变数中选取对 y (label)变异最没显着影响的变数删除,直到剩余的变数对解释y (label)剩余变异皆有显着影响才停止。
程序码实现
import statsmodels.api as sm
import pandas as pd
#Stepwise
def stepwise_selection(data, target,SL_in=0.05,SL_out = 0.05):
initial_features = data.columns.tolist()
best_features = []
while (len(initial_features)>0):
remaining_features = list(set(initial_features)-set(best_features))
new_pval = pd.Series(index=remaining_features)
for new_column in remaining_features:
model = sm.OLS(target, sm.add_constant(data[best_features+[new_column]])).fit()
new_pval[new_column] = model.pvalues[new_column]
min_p_value = new_pval.min()
if(min_p_value<SL_in):
best_features.append(new_pval.idxmin())
while(len(best_features)>0):
best_features_with_constant = sm.add_constant(data[best_features])
p_values = sm.OLS(target, best_features_with_constant).fit().pvalues[1:]
max_p_value = p_values.max()
if(max_p_value >= SL_out):
excluded_feature = p_values.idxmax()
best_features.remove(excluded_feature)
else:
break
else:
break
return best_features
四、结论
今天介绍了几种方法用於特徵选取,有时候我们拿到的资料集的特徵很多,模型训练起来状况不佳的话,就可以考虑使用特徵选取来筛选好的特徵,但也要注意阀值、参数的控制,不要弄巧成拙的把好特徵删除。
筛选出坏的特徵并不难,但当我们手边的资料特徵没有这麽多时,就要想办法生出新的特徵,举例来说:我们可以透过身高及体重资料生成出BMI的资料,这个"衍生"资料的步骤比特徵选取还难的多,却也更重要,需要结合对於分析行业的知识量以及对数据的敏感度,当然,接触过越多资料分析专案就能越上手!
DAY9 资料室--Vuex初创Store
前言 前面两篇我们已经大约了解了 Vuex 的运作模式,所以现在让我们来用个简单的例子实际运用看看吧...
EP 11: Passing Data for Navigation in TopStore App - II
Hello, 各位 iT邦帮忙 的粉丝们大家好~~~ 本篇是 Re: 从零开始用 Xamarin 技...
Day1.认识GUI和Tkinter
图形使用者介面(Graphical User Interface,GUI) 指透过点击图示执行隐含的...
【Side Project】 菜单内容3-画面资料绑定
上一篇我们已经能够从我们资料库上抓出我们建立的菜单了, 这篇会跟大家一起把我们抓出来的画面显示在网页...
图的储存结构 - 十字链结串列 - DAY 22
前言 来到了困住我好几天的储存结构,希望可以让大家很快地看明白,假如看不懂可以再参考大话资料结构的7...