[Day10] 文本/词表示方式(一)-前言
一. 前言
在如今社群网路蓬勃的时代,从网路充斥着许多文字资料,要如何有效的分析文字让电脑可以知道我们喂进去的文字是什麽,所以才会有许多将文字、文章等转成数字、向量的方法。
方法其实已经有很多,像是BOW(Bag of word)、one-hot represtation、tf-idf等,今天拿到了一篇文章,要将文章输入 ML 模型,必须将句子或文章转换成电脑看得懂的样子(向量或数字),但怎麽样表示才能真正代表这个句子或文章的意义呢?过去较长使用的方法为BOW(Bag of word)来表示一个句子或一个文本,但通常这样的表示会造成一些上下文或语意的流失,近期NLP的任务大致上都是先经过word embedding(词向量)层,再去做一些任务的预测,词向量在向量空间中,相同语意的词会靠很近,不同语意的词会离很远,如下图,此图来源如[1]所示,可以看到在不同词向量可以将食物的词聚再一起,旅游相关的词聚再一起:
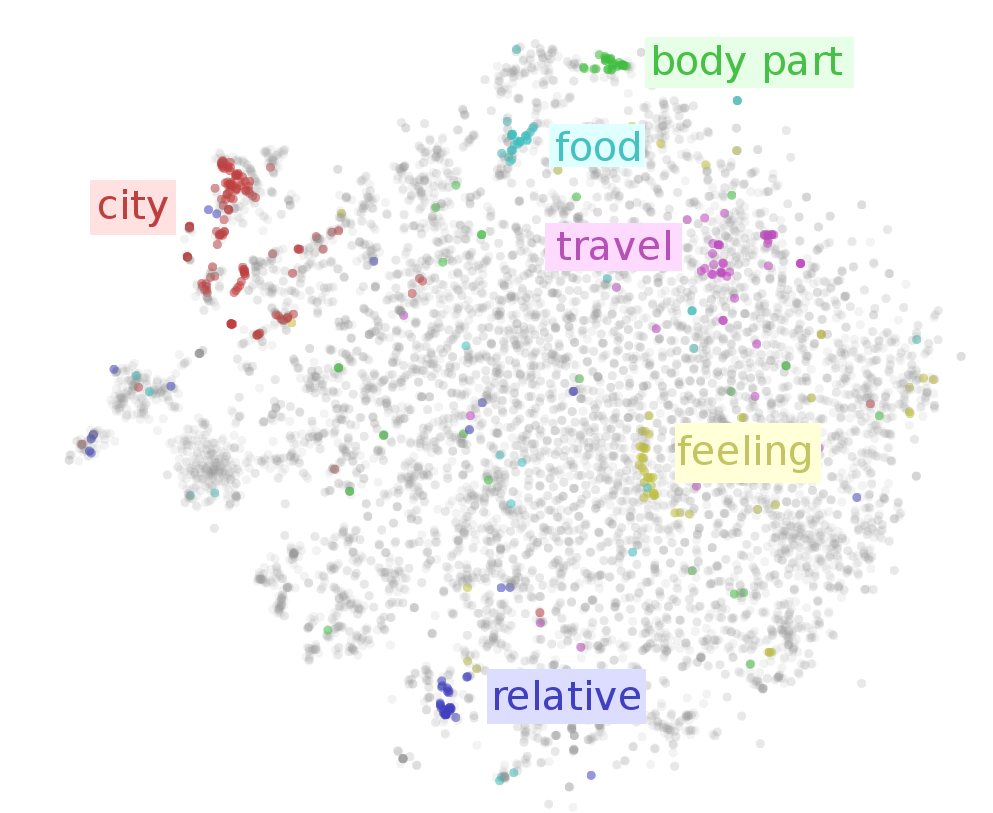
若可以训练出一个具有代表性词的向量表示方式,更能让电脑更了解文章或句子的语意,目前的NLP在进行主要任务之前都会先做word embedding这个动作,这更凸显了其重要性,BERT的Fine tune其实也是相同的意思,先透过原本的BERT对句子文字进行编码,再Fine tune下游任务,而且效果也是很好~~
相关的word2vec、doc2vec的原理大家可以参考我之前写的这篇[2]~不想看也没关系,应该明天或後天就会写了XD。目前会以下列的主题为主来介绍词的相关表示方式:
- BOW/TFIDF
- 共现矩阵
- word2vec
今天主要只是介绍为何要使用这个技术~明天会开始探讨相关的方法~~
参考资料
[1] On word embeddings - Part 1
[2] 读paper之心得:word2vec 与 doc2vec
<<: 电子书阅读器上的浏览器 [Day10] 支援画面点击翻页
Day18 - 汇入 excel-应用篇
前言 使用者除了有汇出报表的需求外,也会有需要大量汇入的情境,汇入会更需要验证输入的资料,有可能是空...
Day 8. 版控很重要!
在遥远的远古时期,专案的程序码都是丢到网路芳邻上时,大家都是用资料夹在做备份跟还原,如果多人开发同个...
[Day 22] Node Event loop 1
前言 昨天, 我们知道了 JS 层藉由 V8 引用 C++ 层, C++ 层又利用 AIO (非同步...
Day_17 : 让 Vite 来开启你的Vue 之 取得 模板元素 ref
Hi Dai Gei Ho~ 我是Winnie~ 突然想来说说: 其实这篇应该要与上篇的 资料定义 ...
[Golang]GOROOT与GOPATH的说明-心智图
1.GOROOT、GOPATH介绍与比较。 2.go build、go install、go get...