day8 : logging集中(中)
昨天成功地取得了vector agent搜集的metric和logger,在使用上因为metric算是一个附赠的功能,所以就不多着墨,可以依据这个概念自己去玩看看,有些人可能会有疑问在k8s上取得log的套件有很多,知名的如fluent-bit为什麽要选择使用vector呢?
原因是他的支援相当的多,可以参考官方的说明https://vector.dev/#performance ,并且vector的角色可以自由地转换,再来就是他的效能是较为优异的,附上数据图

今天要讲的是如何透过vector做基本的parser、transform以及收发。
如同昨天的架构中所示,整个logging的规划中vector扮演的都是传递讯息的角色,让无状态的vector专注於传输,储存放在kafka和接手的储存服务,官方称之为stream base topology vector
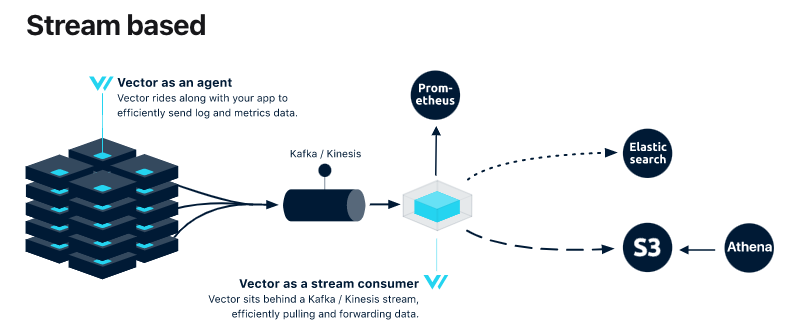
基於这个架构,最左边的vector agent已经透过helm的方式完成了,接着就需要接收端的kafka与相对应的配置。
配置将log送到kafka官网有完整的default设置做法,就来试试看吧
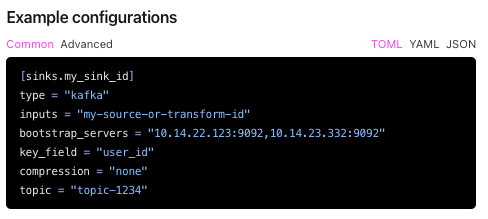
这是官网的简介,其实官网还漏了一行encoding.codec = "json" ,运用这个写法在inputs内写入要丢过去的source并用”,”分隔,就可以丢到kafka罗,要如何区隔想要的log呢?
我使用了几种方式解决不同需求
- source端我加入了extra_field_selector = "metadata.namespace=test" 意指只选test的namespace
- 以及extra_label_selector = "my_custom_labe=my_value”意指只选有这个label及value的
- 以及extra_field_selector = "metadata.name=test”意指只选名字叫做test的
- 过滤的条件则是extra_field_selector = "metadata.namespace!=test”
- 以及extra_label_selector = "my_custom_label=my_value"
相关kubernetes log的参数可以参考这边https://vector.dev/docs/reference/configuration/sources/kubernetes_logs/#annotation_fields.pod_namespace
有了不同的区隔source就可以根据source把log写入不同的topic进行管理。
在kafka确认log有依据分类进来後,就可以开始准备统一管理所有cluster的vector了,因为是统一管理的为了跨cluster使用,我选择用一台vm安装vector,vector can run on anywhere的特性在此展现出来,首先取得rpm
wget https://packages.timber.io/vector/0.15.1/vector-0.15.1-1.x86_64.rpm
yum install vector-0.15.1-1.x86_64.rpm
安装好之後可以在系统上看到
/etc/vector/vector.toml
/usr/lib/systemd/system/vector.service
/usr/bin/vector
vector.toml个是设定source和sink的档案,vector.service是启动服务用的service,vector是提供指令操作使用的;根据目前规划的架构就在vector.toml调整source能够取得kafka的topic并将sink调整为接下来要收log的loki即可,参考配置档案如下

设定完成後,执行vector来运用[sinks.print]的机制看看是否有拉到kafka的topic,成功後就让daemon启动,之後log就都由这台主机管理也容易做後续的分类处理。
>>: 【Day8】 用 MelGan 把 Mel 转成 Waveform
Day 16:CI / CD
前言 DevOps 是一种理念,目的是让开发到发布的速度、稳定性都能提升。 而 CI/CD 是实践 ...
Day17-Kubernetes 那些事 - Auto Scaling
前言 之前的文章介绍了如何利用 ReplicaSet 或 Replication Controlle...
Day7 跟着官方文件学习Laravel-开始学习Command用法
注册的方式我想使用laravel的command来实作,原本想用form表单来实现,不过这样感觉主题...
[Day 18] -『 GO语言学习笔记』- 核心型别(IV)
以下笔记摘录自『 The Go Workshop 』。 接续上一篇的学习笔记。 其实可以直接使用fo...
Day 21-state manipulation 之三:我想 rename 怎麽办?state mv 乾坤大挪移
我想 rename 怎麽办?state mv 乾坤大挪移 课程内容与代码会放在 Github 上: ...