[Day 7] 资料产品第三层 - 预测模型
大部分的人对於资料开始产生兴趣,不外乎就是因为想要预测未来。
(https://www.livebitcoinnews.com/bitcoin-price-analysis-btc-eyes-more-upsides-above-16k/)
即便不用特别的数据分析,我们也习惯透过搜集资料来对未来做猜测。
不管看到阴天就知道等等就会下雨、或是约会时早就知道你朋友会迟到,我们都会透过曾经发生的事情来预测可能发生的状况以提早做准备。我们从过去的资料中看见了某种模式(Pattern),即便没有精确的数字,但也会隐约有个「感觉」(即便「感觉」常常不准)。这个「模式」就是所谓预测模型,每种模式都会解释一部分的事实,同时也提供了对於未来的猜测。
例如你心中有个「约会迟到模式」,只要是 OOO 就会迟到,但是 XXX 就不会迟到。
对应到比较资料科学的用语来说的话
- 约会迟到模式 = 模型(Model)
- 你朋友的名字 = 输入(Input)、特徵值(Feature)
- 迟到/不迟到 = 结果(Output)、标签(Label)
这边介绍几个常用的预测模型以及用途
预测数值的模型
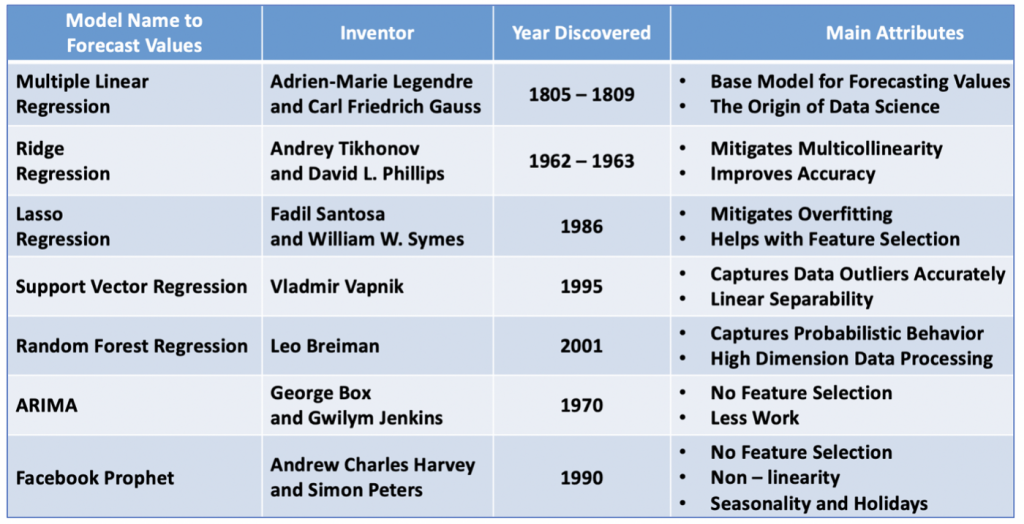
(https://foxworthy-8036.medium.com/18-types-of-predictive-models-in-data-science-b53275810032)
回归模型有非常多种(见上图),但主要目的都是为了预测**「数值型」**的结果。
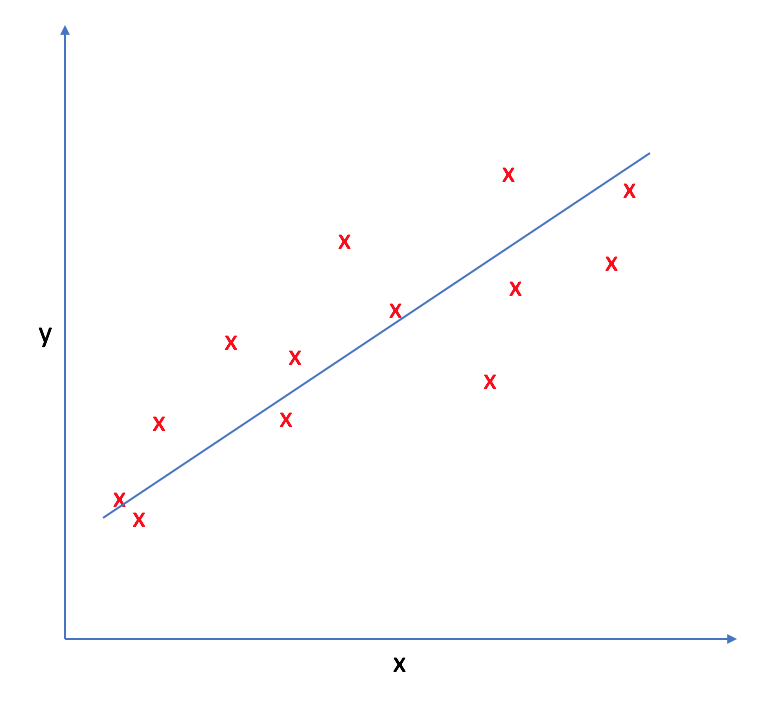
(https://www.jeremyjordan.me/linear-regression/)
就以最常见到的简单线性回归来说好了,如果你每天在记录体重和体脂肪的关系(如上图),在你没有特别运动的情况下,会发现好像可以在这些资料点之间画一条直线贯穿所有资料,尽管不是所有点都在线上,可以看到当体重越高时、体脂肪也跟着上身,也可以想像如果未来体重再上升的话,体脂肪也可能跟着上升。
分类模型
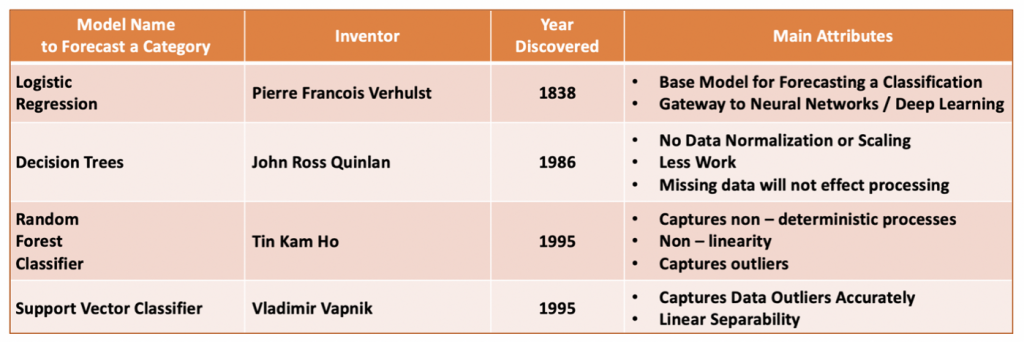
(https://foxworthy-8036.medium.com/18-types-of-predictive-models-in-data-science-b53275810032)
除了预测数值外,我们也很常问要或不要的二元分类问题或多元分类。这种模型的结果不是数值,而是上一篇提到的类别变项,像是下雨/不下雨、点击/不点击,或是猫/狗/鱼这样的问题。
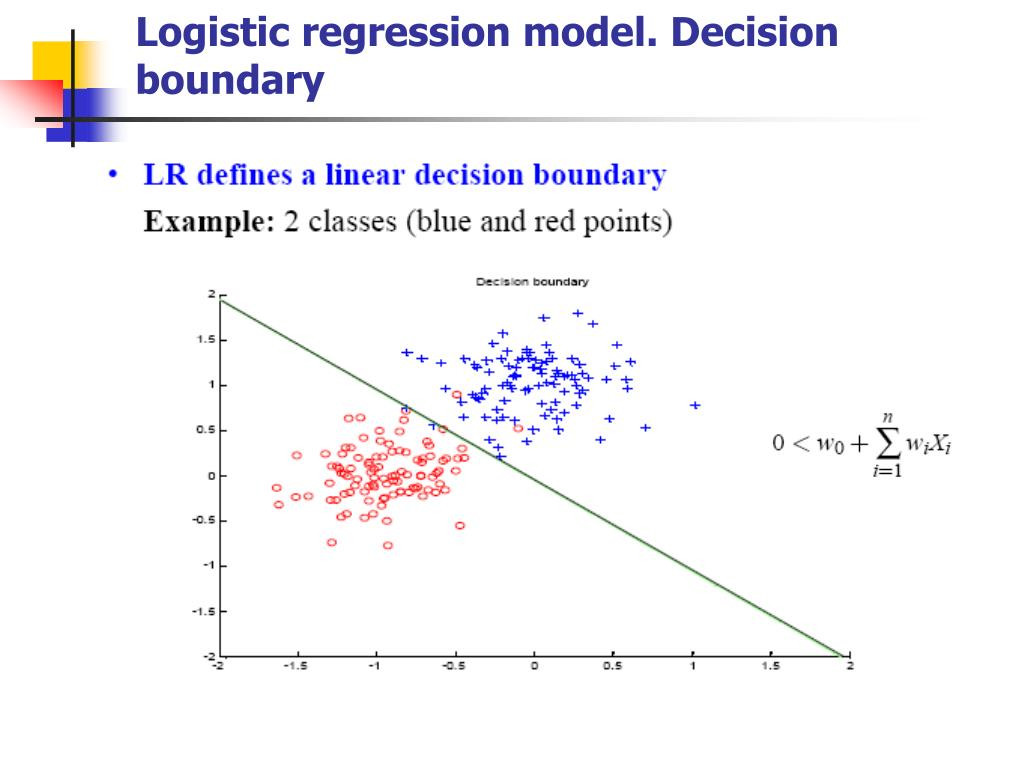
(https://www.slideserve.com/griffin-munoz/logistic-regression)
像上图就是一个在做分类模型时很常使用的罗吉斯回归(Logistic Regression),罗吉斯回归会在空间中寻找一条能将结果分成两边的线,未来只要根据特徵值(Features)就能知道对应的分类是什麽。
训练预测模型
由於预测模型是根据过去的资料来学习资料的模式,方便我们之後能够透过输入的特徵值来预测结果,所以在训练预测模型时很重要的就是需要准备一堆已经知道「答案」的资料。
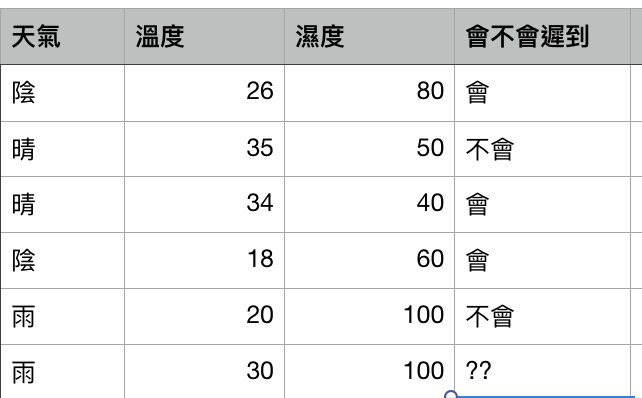
例如上图,我们想要知道约朋友出门会不会迟到,需要先搜集过去可能影响迟到的特徵值(Feature),像是天气、温度、湿度,接着还需要在这些情况下朋友的迟到状况(Label),才有办法学到迟到预测模型。
从这个例子你可以看到,即便做一个简单的迟到预测模型,我们都还是得循序渐进的先定义好要搜集的资料(天气资料、迟到纪录),再将这些资料整理到 Excel 中,看一下有没有错误的纪录资料、做一下资料处理,才有办法进到模型阶段。这也是资料产品很重要的特色 - 循序渐进,要做高层的分析,那些层次基础的工作一点都跑不掉。
References
https://foxworthy-8036.medium.com/18-types-of-predictive-models-in-data-science-b53275810032
https://www.jeremyjordan.me/linear-regression/
https://www.slideserve.com/griffin-munoz/logistic-regression
>>: Day 7. Hashicorp Nomad: Inspect a job
微聊 铁人赛 最终回
今天居然就是铁人赛的最後一天了,没想到!!没想到啊!!!! 今天就来聊最後一回,这 30 天微人都经...
Logger 与 Extension Generator for Kotlin
Logger 在 compile time 的时候,不像我们一般再开发的时候很容易的去 log 一些...
从零开始学3D游戏设计:基础粒子效果
这是 Roblox 从零开始系列,在效果章节的单元,今天你将学会如何透过粒子发射器来做出基本的粒子特...
[Day24] - 介绍 Svelte.js 如何使用
前几天我们有说明 Virtual Dom 如何实作 , 今天我们来介绍一个 反对 Virtual D...
连续 30 天 玩玩看 ProtoPie - Day 22
模拟 Skeleton Loader https://www.youtube.com/watch?v...