DAY07 资料视觉化
一、视觉化为何如此重要
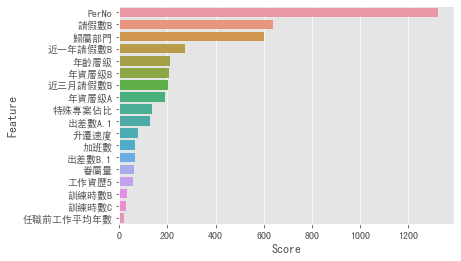
终於进入到视觉化的部分了!虽然现在有很多的绘图软件,但我认为初期用python自己画出图,可以增强自己的编码能力。其实视觉化一直都是资料分析很重要的一环,我用下图举例,你就可以了解为什麽要做视觉化了。以下是我用卡方分配去挑选重要的特徵,得出来的结果。
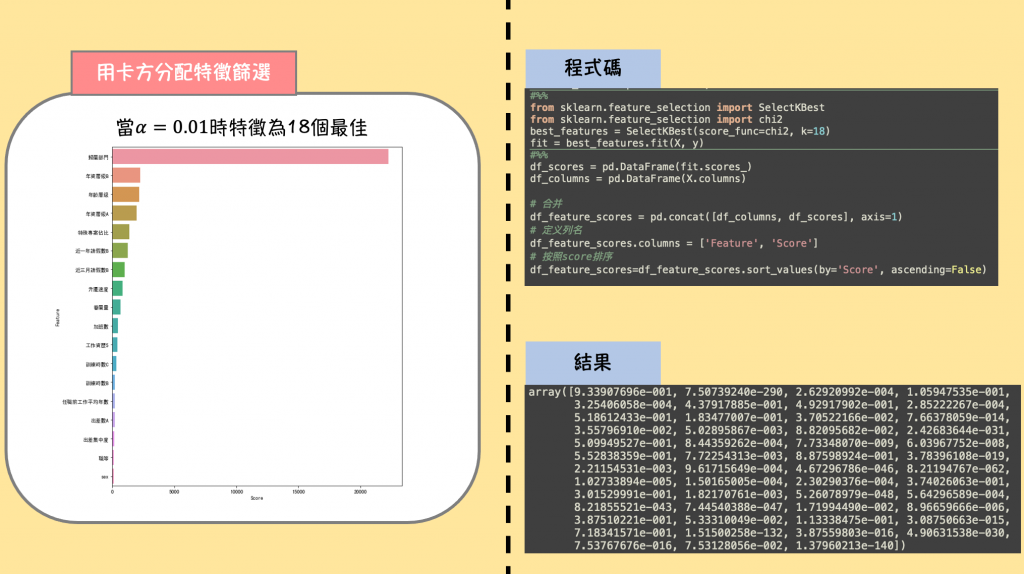
假如你是个大学教授,学生在跟你报告的时候,你希望学生用一张图解释在资料中做了什麽发现了什麽(左图),还是贴出一张程序码逐行解释每一行的功用,最後又贴出一张程序码跑出来的分数(右图)呢?
我想绝大多数会选择左图吧,教授要看到的只是做出来的结果,而不是程序码怎麽执行的,就算程序coding有多厉害,没有搭配图表去解释你的结果,就不能算是一个好的报告。
二、资料视觉化所涵盖的统计概念
有一些基本的统计工具及工具图必须要先了解,才能在画图的时候用对工具。
1.资料分配分为间断型以及连续型
间断型的机率质量函数图形
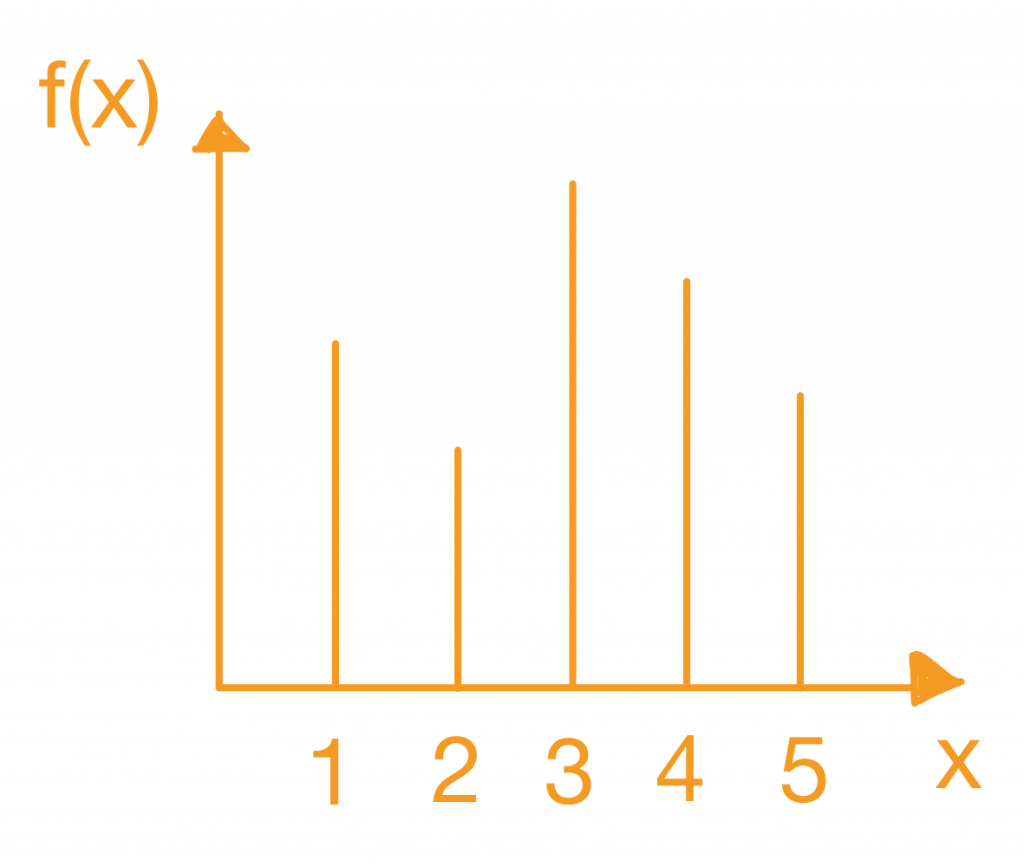
- 间断型画出来的图形会像这样,彼此之间不会相连,常见的间断型资料是性别:男生在资料中占几个,女生占几个。
- 而为何称机率”质量“函数呢?因为他的机率函数值代表他的机率质量大小。意思就是函数值是多少机率值就是多少。因此称为机率质量函数。
连续型的机率密度函数图形
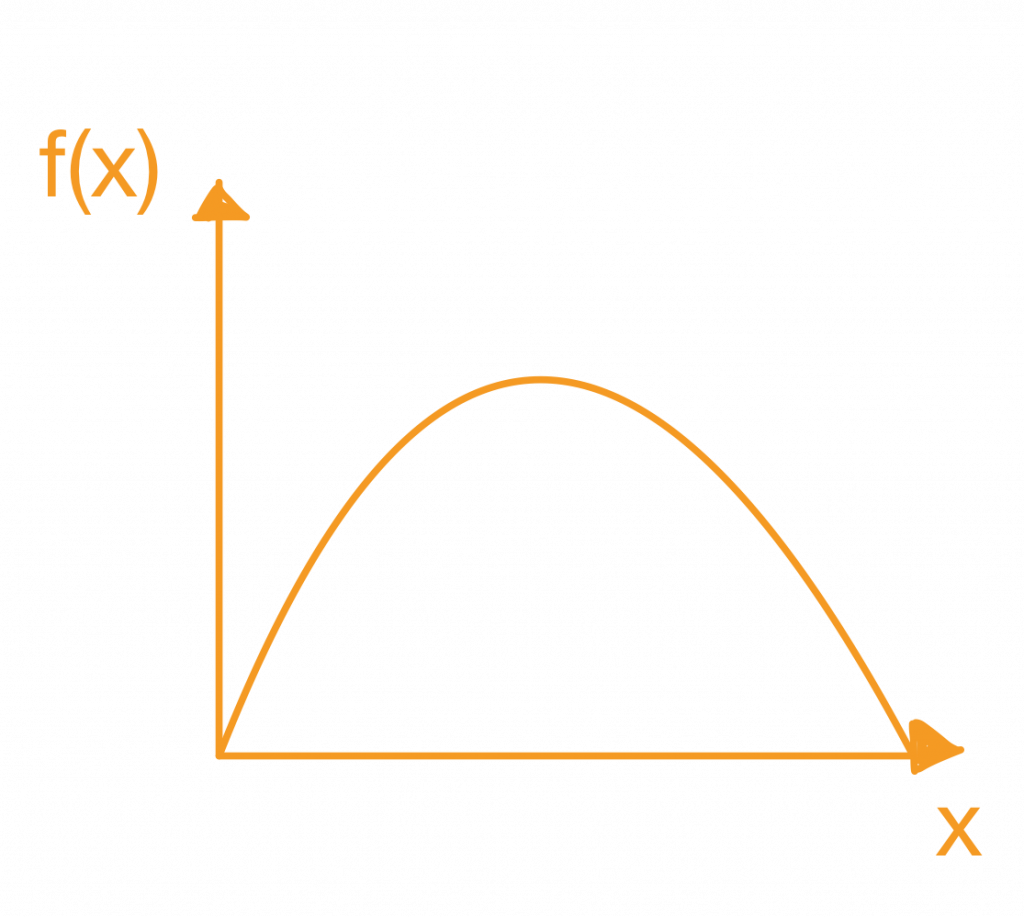
- 连续型画出来的图形会是连续不间断的。在资料中会遇到的,例如像台北市资产分布,每天每小时的pm2.5浓度等......
- 而为何称机率”密度“函数呢?因为他的机率值必须求算他的面积才能得到。因此称为机率密度函数。
2.各图形所代表的意义及功用
- 直方图:将 一组数据分成数组後,依照各组距的范围与次数,绘制成连续型资料之次数分布图,通常可呈现等距及比率变数的资料
- 长条图:与 直方图类似,但主要用以显示类别资料的分布情形,因此条柱不相连。
藉由将各组的标志放在图形的横轴上,纵轴则为次数尺度或累积次数尺度等 - 盒须图:亦称箱型图(box-plot),利用图形呈现资料的中央趋势与离散程度,不需绘制出实际的观察值即可显示所分配的总计统计量
- 折线图:由一条线连接数点以显示序列,以图表呈现资料分布的变化趋势
- 散布图:在多维空间中给出 p 个变数关系的点。由点的疏密程度和延展方向等分布特徵,初步了解变数的关系。
三、各类型基本图表实作
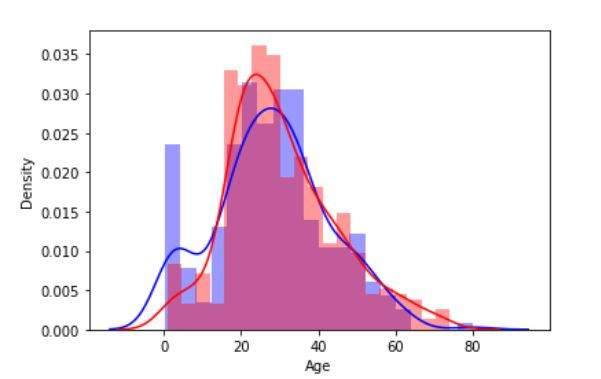
1.直方图
以铁达尼号资料集为例
资料集来源:https://www.kaggle.com/c/titanic/data
index_survived = (train_df["Age"].isnull()==False)&(train_df["Survived"]==1)
index_died = (train_df["Age"].isnull()==False)&(train_df["Survived"]==0)
sns.distplot( train_df.loc[index_survived ,'Age'], bins=20, color='blue', label='Survived' )
sns.distplot( train_df.loc[index_died ,'Age'], bins=20, color='red', label='Survived' )
2.长条图
以员工离职预测率重要程度为例
资料集来源:https://aidea-web.tw/topic/2f3ee780-855b-4ea7-8fc8-61f26447af1d
import seaborn as sns
fig = plt.figure(figsize=(10,12)) #画布大小
sns.barplot(a['Score'],a['Feature']) #前面是X轴你要放的特徵 ,後面是Y轴你要放的东西
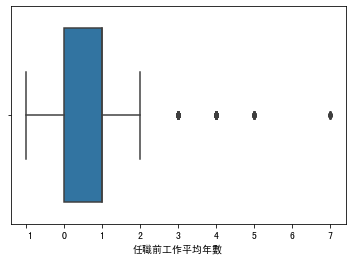
3.盒须图
以员工离职预测“任职前工作平均年数”画出盒须图
可以看到右边的点即为资料中的离群值
资料集来源:https://www.kaggle.com/djhavera/beijing-pm25-data-data-set
import seaborn as sns
sns.boxplot(train['任职前工作平均年数'])
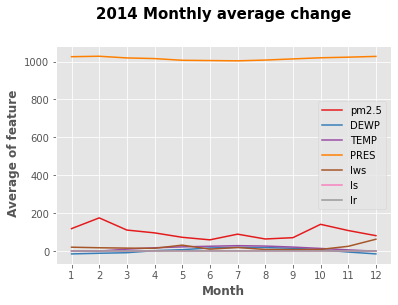
4.折线图
画出每个天气特徵月的变化
资料集来源:https://www.kaggle.com/djhavera/beijing-pm25-data-data-set
plt.style.use("ggplot") # 使用ggplot主题样式
plt.xticks(day)
#画第多条线,plt.plot(x, y, c)参数分别为x轴资料、y轴资料、线颜色
plt.plot(e["month"],e["pm2.5"],c = colors[0])
plt.plot(e["month"],e["DEWP"],c = colors[1])
plt.plot(e["month"],e["TEMP"],c = colors[2])
plt.plot(e["month"],e["PRES"],c = colors[3])
plt.plot(e["month"],e["Iws"],c = colors[4])
plt.plot(e["month"],e["Is"],c = colors[5])
plt.plot(e["month"],e["Ir"],c = colors[6])
# 设定图例,参数为标签、位置
plt.legend(labels=['pm2.5', 'DEWP', 'TEMP', 'PRES', 'Iws', 'Is','Ir'], loc = 'best')
plt.xlabel("months", fontweight = "bold") # 设定x轴标题及粗体
plt.ylabel(" Average of feature", fontweight = "bold") # 设定y轴标题及粗体
plt.title("2014 months average change", fontsize = 15, fontweight = "bold", y = 1.1)
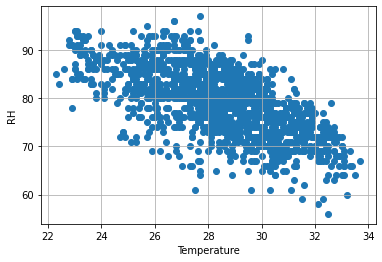
5.散布图
以天气资料为例,可以看到资料呈现负相关。
资料集来源:https://www.kaggle.com/djhavera/beijing-pm25-data-data-set
plt.scatter(df_weather1["Temperature"],df_weather1["RH"])
plt.xlabel("Temperature") #X轴标签
plt.ylabel("RH") #Y轴标签
plt.grid(True)
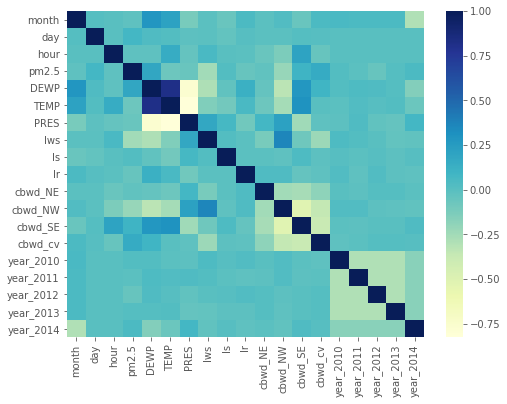
6.相关系数热力图
透过相关系数的计算,我们可以将它已图显示出来最。可以更快找到资料彼此之间的关联。
颜色越深代表关联性越高。
资料集来源:https://www.kaggle.com/djhavera/beijing-pm25-data-data-set
corr_pd = train.corr() #先算出资料间彼此的相关系数
#使用seaborn做视觉化
import seaborn as sns
import matplotlib.pyplot as plt
# 指定画幅
plt.figure(figsize=(8,6))
# 绘制热力图
sns.heatmap(corr_pd, cmap='YlGnBu')
四、结论
其实网路上有很多大神画的图都很漂亮,可以去上面看他们提供的程序码,去研究他怎麽画出来的,以下是这些网站的介绍。
- Plotly:这是一个套件,这个网站都有一些很酷的图,且都有附上程序码。
网址: https://plotly.com/ - matplotlib:也是一个画图套件,一样有各式各样的图,并附上程序码
网址: https://matplotlib.org/3.2.2/index.html
<<: 前端工程师也能开发全端网页:挑战 30 天用 React 加上 Firebase 打造社群网站|Day7 处理注册登入的细节
>>: Day 07 「Tell. Don't Ask.」 测试与依赖:测行为
JS 16 - jQuery 太重了,何不选择需要的功能就好?
大家好! 相信各位都有看到标题了,今天开始就要实作函式库了。 我们进入今天的主题吧! jQuery ...
年薪破百的海岛生活,是你想要的吗?
辛苦赚钱之余也记得要好好享受生活,让这辈子过得更有趣 在菲律宾和柬埔寨的那段时光,是我最惬意的人生...
Day24. Blue Prism加班日 –BP自动选定功能
今日加班加的凶, 不过希望加班加的有意义有价值, 很遗憾的是有时候却是补别人懒惰来的缺口, 排除负面...
Day21. 伸缩自如的,向量图像炮 - SVG
昨天聊到小五郎叔叔脖子上的伤痕,今天要来聊日本的国民漫画航海王,大家有看过航海王的话想必对我们的主角...
[Python]如何使用selenium
python网路爬虫教学-Selenium基本操作 download chrome drive ht...