并行程序的潜在问题 (二)

并行/多执行绪程序往往会碰上同步问题 (Synchronization),在前一篇文章中介绍了什麽是 Race condition 以及 Critical sections,并且利用互斥锁将 CS 锁住。不过,同步问题的解法可不止一个,本篇将探讨广泛应用在 Linux kernel 的 Spinlock。
Spinlock 介绍
Spinlock 中文称做自旋锁,透过名称我们就能大概猜到 Spinlock 的功用。与 Mutex 相同,Spinlock 可以用来保护 Critical section,如果执行绪没有获取锁,则会进入回圈直到获得上锁的资格,因此叫做自旋锁。
原子操作
原子操作可以确保一个操作在完成前不会被其他操作打断,以 RISC-V 为例,它提供了 RV32A Instruction set,该指令集都是原子操作 (Atomic)。
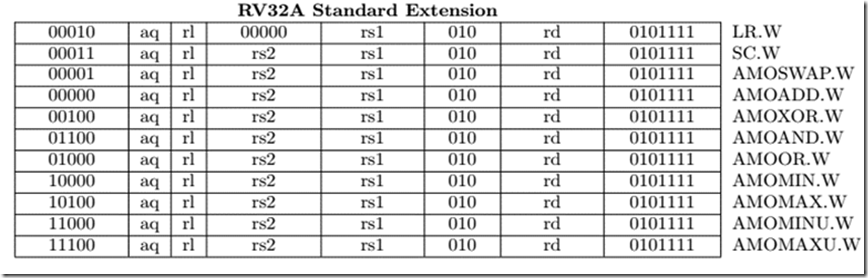
为了避免在同时间有多个 Spinlock 对相同的记忆体做存取,在 Spinlock 实现上会使用到原子操作以确保正确上锁。
其实不单单是 Spinlock,互斥锁在实现上同样需要 Atomic operation。
用 C 语言打造简单的 Spinlock
考虑以下程序码:
typedef struct spinlock{
volatile uint lock;
} spinlock_t;
void lock(spinlock_t *lock){
while(xchg(lock−>lock, 1) != 0);
}
void unlock(spinlock_t *lock){
lock->lock = 0;
}
透过范例程序码,可以注意到几点:
- lock 的
volatile关键字
使用volatile关键字会让编译器知道该变数可能会在不可预期的情况下被存取,所以不要将该变数的指令做优化以避免将结果存在 Register 中,而是直接写进记忆体。 - lock 函式
xchg(a,b)可以将 a, b 两个变数的内容对调,并且该函式为原子操作,当 lock 值不为 0 时,执行绪便会不停的自旋等待,直到 lock 为 0 (也就是可供上锁)为止。 - unlock 函式
由於同时间只会有一个执行绪获得锁,所以在解锁时不怕会有抢占存取的问题。也因为这样,范例就没有使用原子操作了。
Spinlock 的演进
从刚刚的介绍可以得知,执行绪是否能获取 Spinlock 与投入顺序并没有太大的关系,而是取决於哪一个处理器核心最快查觉到 spinlock 状态的变化,更精确的说法是,哪个处理器核心的 Cache 更快与主记忆体内容同步。
可参考处理器的快取策略。
Wild spinlock
Wild spinlock 类似於我们刚刚实作的简易自旋锁:
typedef struct spinlock{
volatile uint lock;
} spinlock_t;
void lock(spinlock_t *lock){
while(xchg(lock−>lock, 1) != 0);
}
void unlock(spinlock_t *lock){
lock->lock = 0;
}
不过,这种作法是有明显的缺陷的,在前面笔者有提到:
执行绪是否能获取 Spinlock 与投入顺序并没有太大的关系,而是取决於哪一个处理器核心最快查觉到 spinlock 状态的变化,更精确的说法是,哪个处理器核心的 Cache 更快与主记忆体内容同步。
假设在 8 核心处理器中,如果 8 个核心都希望抢占同一个 lock,便会有些核心始终抢不到 lock,造成 CPU 空转的现象(瞎忙)。
Ticket spinlock
为了解决这个问题,科学家为 spinlock 添增了抢票的机制,就好比我们去邮局需要领号码牌。这样一来,我们就可以确保每个 CPU 都可以获取到锁。
struct spinlock {
unsigned short owner;
unsigned short next;
};
void spin_lock(struct spinlock *lock)
{
unsigned short next = xadd(&lock->next, 1);
while (lock->owner != next);
}
void spin_unlock(struct spinlock *lock)
{
lock->owner++;
}
范例程序码取自 Ref[3]。
其中,xadd(a, b) 也是属於 x86 的原子操作,它会返回 a 值并将 a + b 的结果写回记忆体。
当 Owner 等於 spin_lock() 中 next 的值时,也就代表号码牌叫到该执行绪了,这时候,该执行绪就可以跳出回圈并进入到 CS,等到结束执行 CS 後,在将 lock 的拥有者交给下一个执行绪。
Ticket spinlock 的效能问题
假设现在有 4 核心的处理器,并且每个核心的执行绪都想要存取 Spinlock,这时候,概念有点像是:
- CPU0 从主记忆体存取 spinlock 到 Cache,并且获得 lock 的所有权。
- CPU0 会将 next 值更新到主记忆体中。
- CPU1 从主记忆体存取 spinlock 到 Cache。
- CPU1 Invalid CPU0 快取的 Spinlock 并更新 Next 的值,随即发现
next!=owner,所以进行等待。 - CPU2 从主记忆体存取 spinlock 到 Cache。
- CPU2 Invalid CPU1 快取的 Spinlock 并更新 Next 的值,随即发现
next!=owner,所以进行等待。 - CPU3 从主记忆体存取 spinlock 到 Cache。
- CPU3 Invalid CPU2 快取的 Spinlock 并更新 Next 的值,随即发现
next!=owner,所以进行等待。 - 就在此时,CPU0 释放了 Lock,重新 Cache 锁并且更新 owner 的值并且 Invalid 所有其他 CPU 快取的 Spinlock。
- CPU1 发现 Cache 的
lock->owner失效了,重新进行了 Cache 并获得锁 (next == lock->owner)。 - 以此类推...
贴心提醒: 每个执行绪所持有的 next 值之所以不用考虑 Cache 是否 Valid,是因为在第一次尝试 lock 时,我们就已经复制一份 next 的值到属於 Thread 自己的 Stack 罗!
透过上面的解说可以发现: 当抢占锁的执行绪一多,就会造成 Cache 被反覆的更新。这样不止会浪费通道频宽,更会增加存取速度的延迟。
也因为这样,电脑科学家又设计了其他 Spinlock 试图解决这些问题。
MCS spinlock
MCS spinlock 的示意图取自 https://static.lwn.net,笔者会再花时间把图片重做。
为了避免 Cache 被反覆的更新,电脑科学家提出了 MCS spinlock,其设计理念是让每一个 CPU 各自持有一个 spinlock,每个独立核心只需要观察和维护各自的 lock 即可。
参考 lwn.net,MCS Lock 的结构如下方所示:
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; /* 1 if lock acquired */
};
上面提到每个 CPU 都会持有一份 spinlock,不只如此,MCS Spinlock 还会有一个 Main lock 做为这个资料结构的 head。
Main lock 的初始状态
当 Main lock 被初始化时,其状态如下图:

CPU 获取锁
当有 CPU 尝试获取锁时,CPU 会建立一个属於自己的 MCS spinlock,然後与 Main lock 做原子操作,若 Main lock 的 next 为 Null (Main lock 指向 Null) 的话,代表目前没有人在排队,我们就可以让 Main lock 指向 CPU 持有的 MCS spinlock 然後持有锁,这边的原子操作的概念为:
swap(main_lock, cpu_lock){
ret = main_lock;
&main_lock->next = cpu_lock;
&main_lock->locked = &cpu_lock->locked;
return ret;
}
经过原子交换,MCS spinlock 的状态会变成这样:

当锁已经被他人持有时
延续刚才的范例,CPU1 已经持有了 spinlock,现在多了一个 CPU2 尝试存取锁。经过原子操作,Main lock 会指向 CPU2 持有的 lock :

不过,从 Main lock 的状态可以看出目前 spinlock 已经被他人占有 (main_lock->next != null)所以 CPU2 只能等待,这时会将 CPU1 的 MCS lock 指向 CPU2 所持有的 MCS lock :

当锁被释放
当 CPU1 完成任务,会对 Main lock 做比较和交换,若 Main lock 指向自己,代表没有其他人在排队,便只要更新 Main lock 的 locked 值并让 Main lock 指向 Null,最後将 CPU1 持有的 MCS spinlock 释放即可:
除了上述的状况,如果 Main lock 指向的不是自己,那我们只要将 CPU2 的 locked 值改变,再释放自身持有的 MCS spinlock :

MCS spinlock 是由 qspinlock 演变而来,有兴趣的话可以参考 spinlock 前世今生一文。
Spinlock v.s. Mutex
既然两者都是用来将 CS 锁住,为何还需要这两个锁呢?我们可以从其设计思维与运作方法了解这两个锁分别适用在哪些场景。
Busy-waiting
在软件工程中,忙碌等待是一种以行程反覆检查一个条件是否为真为根本的技术,条件可能为键盘输入或某个锁是否可用。忙碌等待也可以用来产生一个任意的时间延迟,若系统没有提供生成特定时间长度的方法,则需要用到忙碌等待。不同的电脑处理器速度差异很大,特别是一些处理器设计为可能根据外部因素动态调整速率。
-- 维基百科
Spinlock 便是实践 Busy-waiting 的锁。
Sleep-waiting
维基百科上并没有对 Sleep-waiting 做介绍,所以笔者用更简单的例子说明:
假设我们今天在汤X熊游乐场,当 A 机台已经有两个小朋友占用,如果以 Busy-waiting 的方法来看,我们会傻傻的站着等到小朋友玩够了,才换我们上去玩。而 Sleep-waiting 则是让我们先去做其他事情,等到小朋友玩够了再通知我们过去玩。
Mutex lock 便是实践 Sleep-waiting 的锁。
Lock implementation in mini-riscv-os
basic lock
首先,由於 mini-riscv-os 是属於 Single hart 的作业系统,除了使用原子操作以外,其实还有一个非常简单的作法可以做到 Lock 的效果:
void basic_lock()
{
w_mstatus(r_mstatus() & ~MSTATUS_MIE);
}
void basic_unlock()
{
w_mstatus(r_mstatus() | MSTATUS_MIE);
}
在 [lock.c] 中,我们实作了非常简单的锁,当我们在程序中呼叫 basic_lock() 时,系统的 machine mode 中断机制会被关闭,如此一来,我们就可以确保不会有其他程序存取到 Shared memory,避免了 Race condition 的发生。
spinlock
上面的 lock 有一个明显的缺陷: 当获取锁的程序一直没有释放锁,整个系统都会被 Block,为了确保作业系统还是能维持多工的机制,我们势必要实作更复杂的锁:
- [os.h]
- [lock.c]
- [sys.s]
typedef struct lock
{
volatile int locked;
} lock_t;
void lock_init(lock_t *lock)
{
lock->locked = 0;
}
void lock_acquire(lock_t *lock)
{
for (;;)
{
if (!atomic_swap(lock))
{
break;
}
}
}
void lock_free(lock_t *lock)
{
lock->locked = 0;
}
其实上面的程序码与前面介绍 Spinlock 的范例基本上一致,我们在系统中实作时只需要处理一个比较麻烦的问题,也就是实现原子性的交换动作 atomic_swap():
.globl atomic_swap
.align 4
atomic_swap:
li a5, 1
amoswap.w.aq a5, a5, 0(a0)
mv a0, a5
ret
在上面的程序中,我们将 lock 结构中的 locked 读入,与数值 1 做交换,最後再回传暂存器 a5 的内容。
进一步归纳程序的执行结果,我们可以得出两个 Case:
- 成功获取锁
当lock->locked为0时,经过amoswap.w.aq进行交换以後,lock->locked值为1,回传值 (Value of a5) 为0:
void lock_acquire(lock_t *lock)
{
for (;;)
{
if (!atomic_swap(lock))
{
break;
}
}
}
当回传值为 0,lock_acquire() 就会顺利跳出无穷回圈,进入到 Critical sections 执行。 2. 没有获取锁
反之,则继续在无穷回圈中尝试获得锁。
总结
在介绍完 Spinlock 、 Mutex 与 Spinlock 的差别後,笔者再补充一下这两个锁适合应用在哪些场景:
- spinlock
spinlock 适合用来保护一段简单的操作,设想现在我们在排队的机台,每个人只能使用 5 秒,那根本不值得让我们离开去做别的事情,待在原地排队是更好的选择。 - Mutex lock
相反的,Mutex lock 适合拿来保护一段区域,以排吃到饱餐厅为例,当轮到我们入场时,店家会使用电话告知。因此在这段等待的时间,我们就可以到商场周边晃晃避免空等。
BTW: 学习 spinlock 时不难发现在 Linux 中真的使用了大量的 Linked-list,学习并行程序的同步问题之余还能看到多个 Linked-list 的延伸,可以说是一石二鸟(吗)。
Reference
- semaphore, mutex, spin lock
- 获取自旋锁和禁止中断的时候为什么不能睡眠?
- spinlock 前世今生
- Linux 核心设计: 多核处理器和 spinlock
- Spinlock & MCS Lock
<<: [Day 30] Reactive Programming - 感想
Day05 - 今天只调了 VS Code 让 tab 为 2格 space
因为开启 Vue CLI 时有套用 ESLint,而他似乎希望我缩排为 2 space 所以将 VS...
前後端分离
在我工作前,团队 CICD 中将後端与前端一起打包,每次建构都需要花 9 分钟。这九分钟触发点是改了...
System Design: 读书心得4
Elasticsearch/Solr/ELK Stash Caveat of using Elast...
Day-29 特集:解构 destructing
在现行的ES6版JavaScript中,增加了以解构(destructuring)替物件或阵列赋值的...
[CSS] Flex/Grid Layout Modules, part 13
单元对齐跟留白的部分今天会继续,定位的问题基本上不出乱子的话就如同昨天说明的。当然,如果再加上对齐跟...