Python 演算法 Day 6 - 理论基础 统计 & 机率
Chap.I 理论基础
Part 4:统计 & 机率
Analyze the data through data visualization using Seaborn
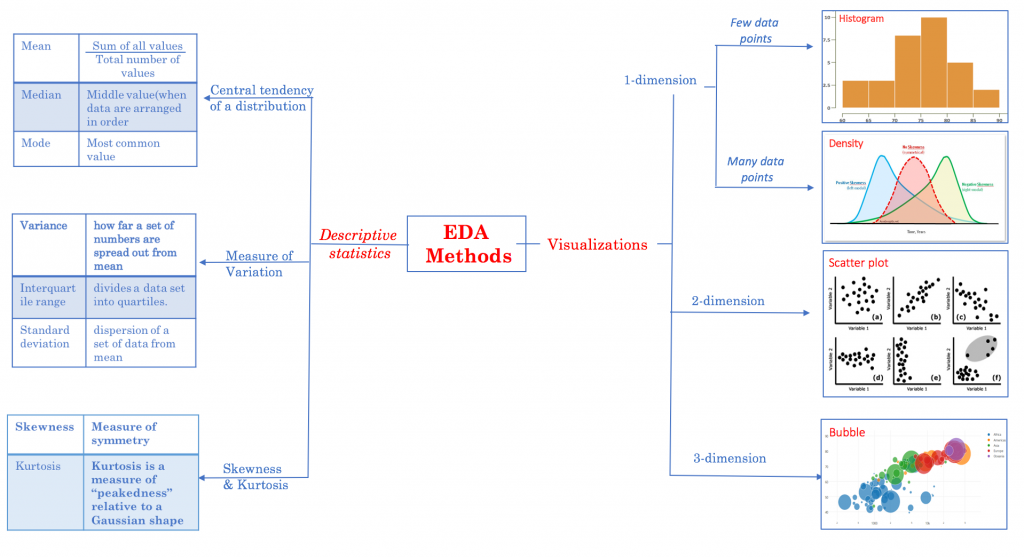
1. Data and Data Visualization
1-1. Introduction to Data
统计是基於资料所推演出来的资讯,包括一些描述、数量及衡量。
资料集(dataset):又称样本。包括 Observations 观察值或 Cases 案例,即资料集的列。
attributes 属性或 features 特徵:资料集或观察值的栏位。
import statsmodels.api as sm
# 取出内建资料集 (父母对小孩身高)
# https://www.statsmodels.org/devel/datasets/index.html
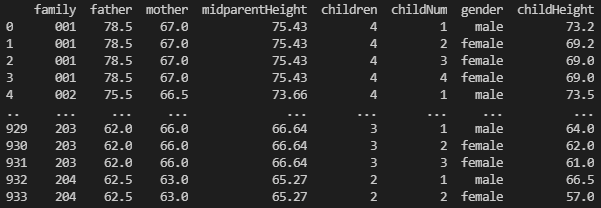
df = sm.datasets.get_rdataset('GaltonFamilies', package='HistData', cache=True).data
print(df)
1-2. Qualitative Data:定性资料,类别栏位
a. Nominal Data: 栏位值并没有大小的隐含意义。
one-hot encoding: 栏位颜色(红/蓝/绿),会将其拆成: 栏位红(是/否)、栏位蓝(是/否)、栏位绿(是/否)
b. Ordinal Data: 栏位值有大小的隐含意义。
Discrete Data: 离散资料,通常会用分类演算法。
Continuous Data: 连续资料,通常会用回归演算法。
少部分如: 目标年龄层客群 (15~20岁),会将资料做成离散资料演算法。q
补充:Interval vs. Ratio
Interval:数值可比较,但无零的概念。例如温度 0度,又 20 度并不是 10 度的两倍。
Ratio:数值可比较,也有零的概念。例如身高、体重及时间长度。
补充:Sample vs Population
样本(Sample) 与 母体(Population)
台北市长选举:全体市民>=20岁 ==> 母体(Population)
抽样调查1000份 ==> 样本(Sample)
1-3. Visaulization
我们先取用一个 Datasets
import statsmodels.api as sm
df = sm.datasets.get_rdataset('GaltonFamilies', package='HistData', cache=True).data
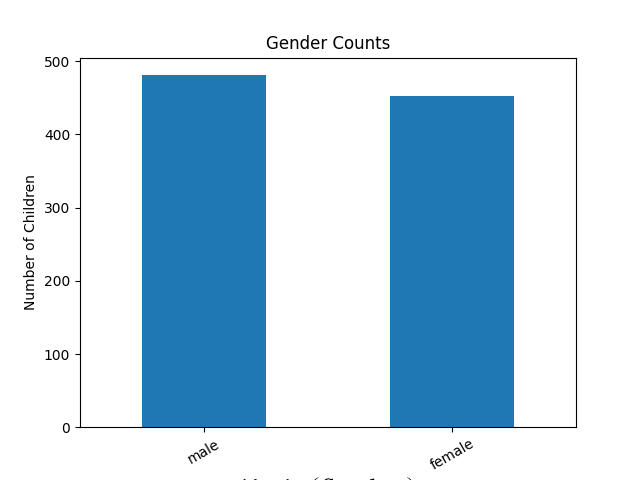
A. 长条图 Bar chart
多用於比较资料不同样本差异。
A1. matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
genderCounts.plot(kind='bar', title='Gender Counts')
# 中文化: 指定中文字体
zhfont1 = fm.FontProperties(fname='C:\Windows\Fonts\kaiu.ttf', size=20)
plt.xlabel('性别 (Gender)',fontproperties=zhfont1)
plt.xticks(rotation=30)
plt.ylabel('Number of Children')
plt.show()
A2. seaborn (基础架构在 mayplotlib 上)
import matplotlib.pyplot as plt
import seaborn as sns
# 性别 vs. 小孩身高
sns.barplot(x='gender', y='childHeight', data=df)
plt.show()
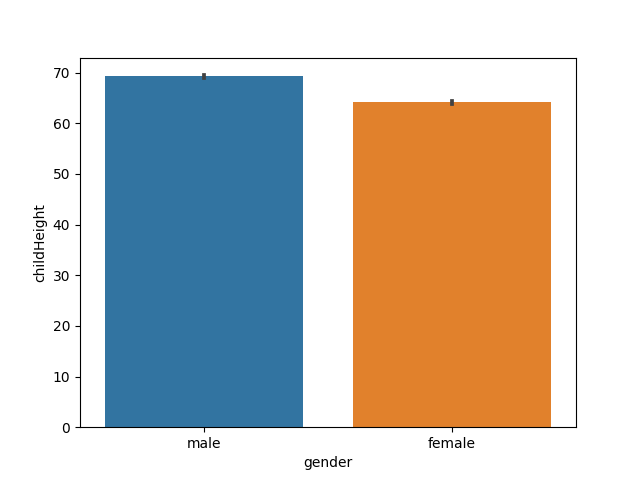
# 家中小孩数 vs. 小孩身高
sns.barplot(x='children', y='childHeight', data=df)
plt.show()
# 用 hue= ,家中小孩数&小孩排名 vs. 小孩身高
sns.barplot(x='children', y='childHeight', hue='childNum', data=df)
plt.legend('')
plt.show()
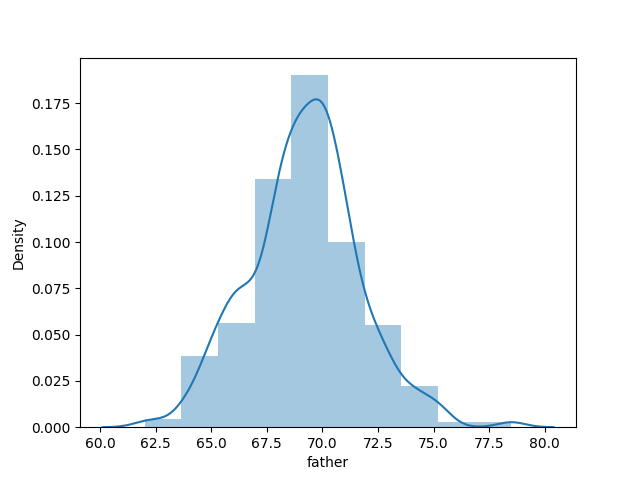
B. 直方图 Histogram
多用於观察资料分布、是否有极端值...等。
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(df['father'], bins=10, kde=True)
plt.show()
C. 圆饼图 Pie plot
用於观察资料样本简单分布。
PS. secborn 并没有 pie plot 画法
import seaborn as sns
import matplotlib.pyplot as plt
genderCounts.plot(kind='pie', title='Gender Counts', figsize=(6,6)) #,explode=[0.2, 0.])
plt.show()
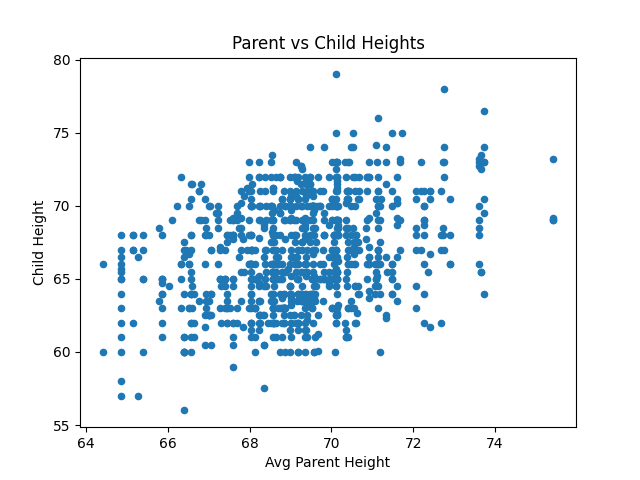
D. 散布图 Scatter plots
观察定量特徵间的关系,也可以观察是否有离群值 (outliers)
import seaborn as sns
import matplotlib.pyplot as plt
Heights = df[['midparentHeight', 'childHeight']]
Heights.plot(kind='scatter', title='Parent vs Child Heights', x='midparentHeight', y='childHeight')
plt.xlabel('Avg Parent Height')
plt.ylabel('Child Height')
plt.show()
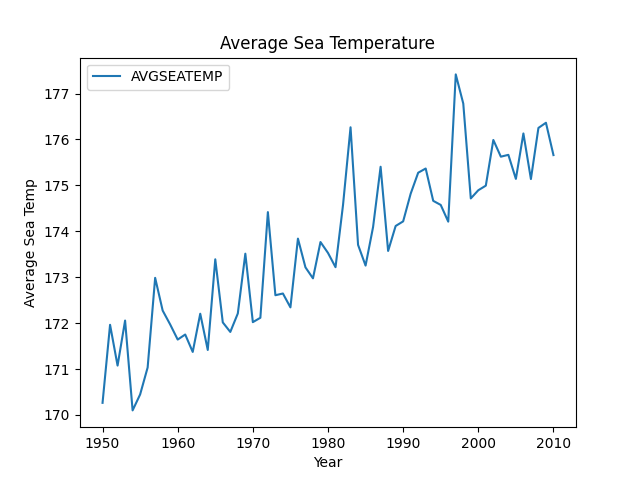
E. 线性图 Line chart
import seaborn as sns
import matplotlib.pyplot as plt
df = sm.datasets.elnino.load_pandas().data
print(df)
df['AVGSEATEMP'] = df.mean(1)
print(df['AVGSEATEMP'])
df.plot(title='Average Sea Temperature', x='YEAR', y='AVGSEATEMP')
plt.xlabel('Year')
plt.ylabel('Average Sea Temp')
plt.show()
.
.
.
.
.
Homework Ans:
1. 依据网页内容,规划人力资源
max z = 4x + y
3x + 2y <= 6
6x + 2y <= 10
x, y >=0
import pulp as p
# 建立线性规划 求取目标函数的最大值
Lp_prob = p.LpProblem('Problem', p.LpMaximize)
# 宣告变数(Variables)
x = p.LpVariable("x", lowBound = 0) # x 最小不能小於0
y = p.LpVariable("y", lowBound = 0) # y 最小不能小於0
# 定义目标函数(Objective Function)
Lp_prob += 4 * x + y
# 定义限制条件(Constraints)
Lp_prob += 3 * x + 2 * y <= 6
Lp_prob += 6 * x + 3 * y <= 10
# 求解
status = Lp_prob.solve()
# 显示答案
print(p.value(x), p.value(y), p.value(Lp_prob.objective))
>> 1.6666667 0.0 6.6666668
HW2. 供水需求、供给、处理费如下。若供水留给下季使用,每单位储水成本增加$10,问全年最小成本为?
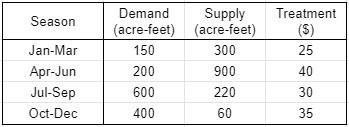
首先,令:
1. 成本(所求) = 当季存储(未知) * 10 + 当季处理(未知) * 当季价格
2. 当季存储(未知) <= 当季供给 + 上季存储(未知) - 当季需求
3. 当季处理(未知) >= 当季需求 + 当季存储(未知)
# 建立线性规划 求取目标函数的最小值
Lp_prob = p.LpProblem('Problem', p.LpMinimize)
# 宣告变数(Variables)
# 储水量
x1 = p.LpVariable("x1", lowBound = 0) # Create a variable x >= 0
x2 = p.LpVariable("x2", lowBound = 0) # Create a variable x >= 0
x3 = p.LpVariable("x3", lowBound = 0) # Create a variable x >= 0
x4 = p.LpVariable("x4", lowBound = 0) # Create a variable x >= 0
# 处理量
y1 = p.LpVariable("y1", lowBound = 0) # Create a variable y >= 0
y2 = p.LpVariable("y2", lowBound = 0) # Create a variable y >= 0
y3 = p.LpVariable("y3", lowBound = 0) # Create a variable y >= 0
y4 = p.LpVariable("y4", lowBound = 0) # Create a variable y >= 0
# 定义目标函数(Objective Function)
Lp_prob += (x1 + x2 + x3 + x4)*10 + y1*25 + y2*40 + y3*30 + y4*35
# 定义限制条件(Constraints)
Lp_prob += x1 <= 300 + 0 - 150
Lp_prob += x2 <= 900 + x1 -200
Lp_prob += x3 <= 220 + x2 - 600
Lp_prob += x4 <= 60 + x3 - 400
Lp_prob += y1 >= 150 + x1
Lp_prob += y2 >= 200 + x2
Lp_prob += y3 >= 600 + x3
Lp_prob += y4 >= 400 + x4
# 求解
status = Lp_prob.solve()
# 显示答案
x = [x1, x2, x3, x4]
y = [y1, y2, y3, y4]
for i in range(4):
print(p.value(x[i]), p.value(y[i]), p.value(Lp_prob.objective))
>> 20.0 170.0 94050.0
720.0 920.0 94050.0
340.0 940.0 94050.0
0.0 400.0 94050.0
Day 22 Flask-SocketIO
上一篇讲完了 Flask 的本体,这篇开始就要开始讲 Flask 的插件了。Flask 从初始版本(...
Day17 - GitLab CI 流水线建置
前言 从今天以及之後的几篇文章,将介绍如何打造 GitLab CI 流水线,以及如何透过 ArgoC...
JavaScript Hoisting (提升)
Hoisting 能在宣告变数、函式、物件与其他型别前先进行使用,但是初始化并不会被提升。 因为 J...
以 GraphQL 查询 Neo4j 资料库
前言 GraphQL 原是 Facebook 内部的开发计画,现已独立出来成为 GraphQL 基金...
Day7-JDK查看正在运行的Java进程工具:jps
前言 在介绍JDK有哪些工具时,第二大列应该是『故障排查、分析、监控和管理工具』,但我想先从监控工具...