(特别篇)Documents-Delivered-Data,Data-DrivenDocuments—爬虫D3做成D3(上)
没有资料就没有燃料,没有燃料就变成废料—浅谈特别篇
标题取名的缘由一方面来自於d3JS的全名Data-Drive-Documents令一方面Documents-Delivered-Data可以算是本日的重点,要从Documents(也就是网页)Delivered(传递)Data(资料),做为资料视觉化的主题当中,资料是最根源的一项要素,从第一天到现在的的范例,绝大多数都是使用真实的资料,不敢说是无瑕的程序码,但希望能藉由处理的过程当中让读者们了解到资料的预处理重要性及方法,做为D3Js的主题剩下几天想谈一些关於撷取资料和资料知识来契合整个主题的完整型,我们今天预计将使用Puppeteer来获取铁人赛文章名称为d3.js的tag,之後一样会绘制出图表并且稍微讲解一些基本统计数值的意义,这些统计数值也是D3Js的API所提供。
另外需要注意的地方是使用爬虫软件如果反覆对网页服务器发送请求,可能服务器端的程序有侦测短时间大量相同IP发出网页请求或是其他侦测项目而遭到封锁,请深思後果後使用。
Puppeteer介绍
Puppeteer 是Node.js的套件,可以控制浏览器,研发团队来自於Google,可以使用在浏览器的自动化测试、爬虫。
自动化测试
如果想要检查自己写的网页每个连结是否有效,每个按钮是否正确,如果当前端网站每次写完的时候都要用人工的方式手动按下这些键是十分花时间的事情,因此可以藉由自动化工具来进行,Puppeteer可以开启浏览器操控许多事情,模拟表单输入、点击按钮、跳转页面
爬虫
爬虫的意思是指说可以读取网页的内容,另外可以藉由程序存在一个变数或者档案当中,例如我们想要得知网页上所有连结,可以找到含有<a></a>标签的字将里面的href属性存成一笔阵列,藉由这种机制我们可以解决重复的事情,也算是某种程序设计师的思维—解决重复的事情。
安装Node Js
首先要下载 node JS
到node Js官网的下载页面如下图
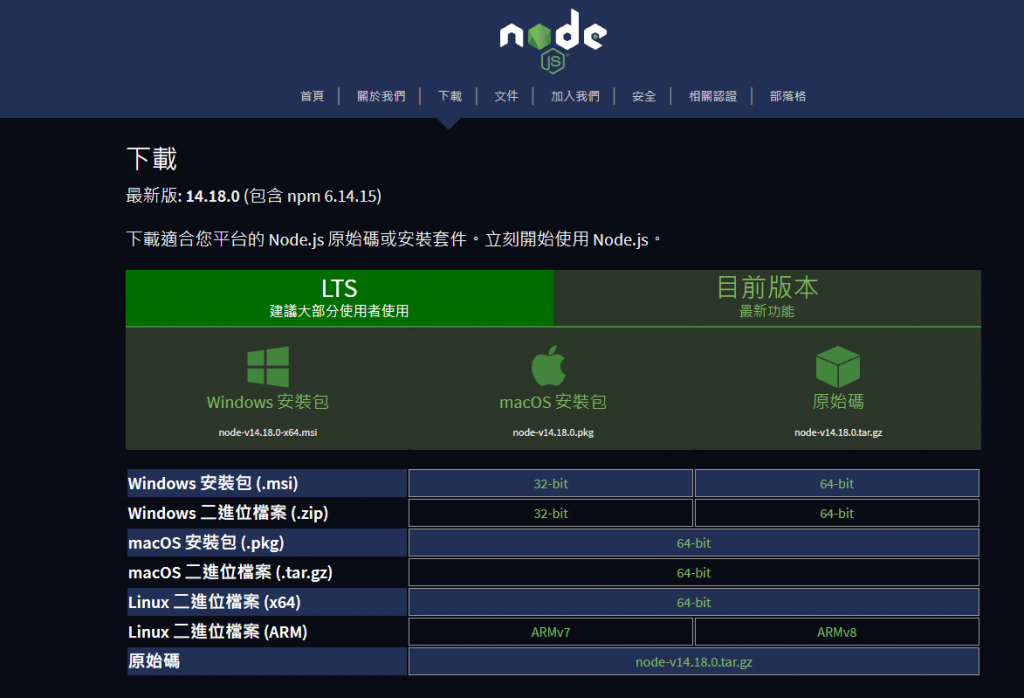
一般来说建议下载LTS(Long Term Support),算是比较稳定的版本。
依据你的作业系统下载,基本上使用预设next→next就可以了。

下载完毕後
以windows为例 输入cmd来打开命令提示字元视窗

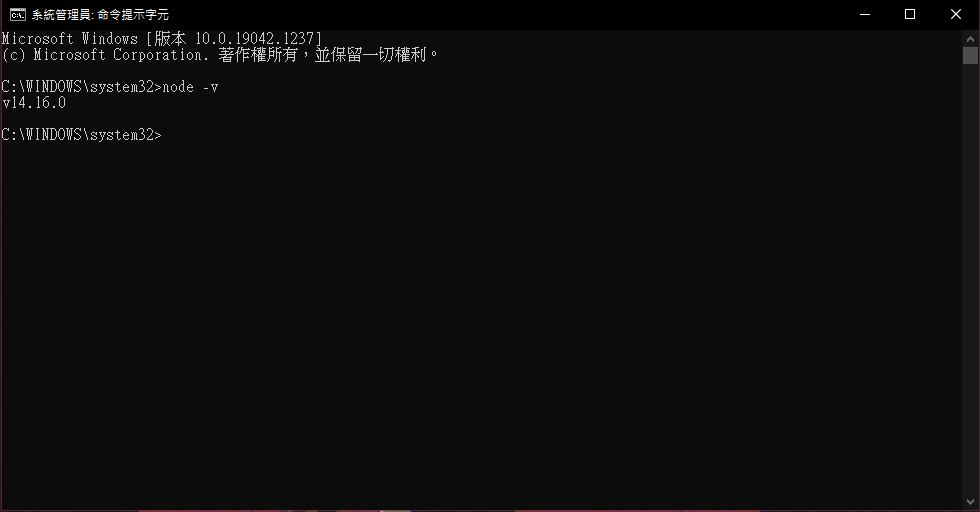
输入node -v
可以看到node 的版本显示的话就代表安装成功了
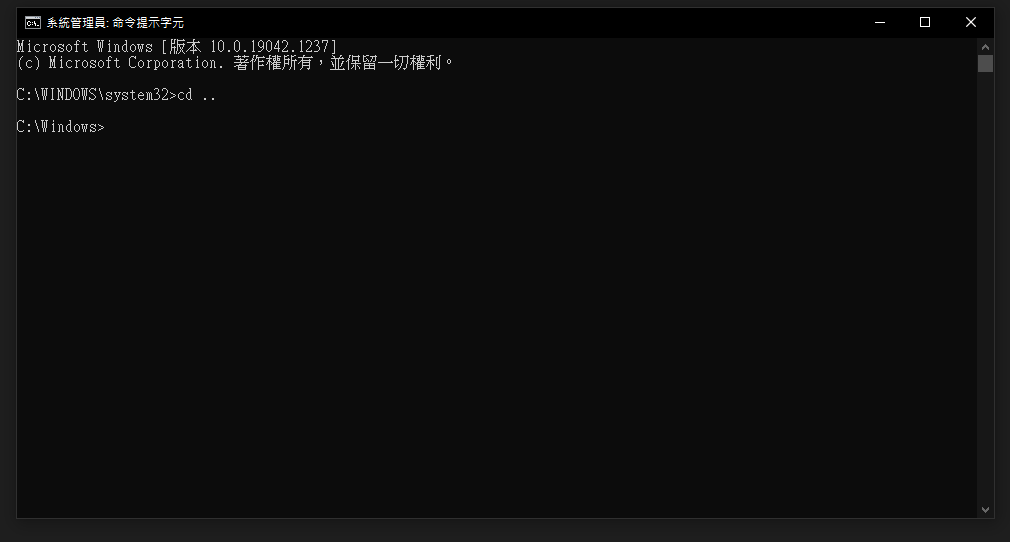
移动至安装资料夹
使用cd .. 回上层目录 如下图
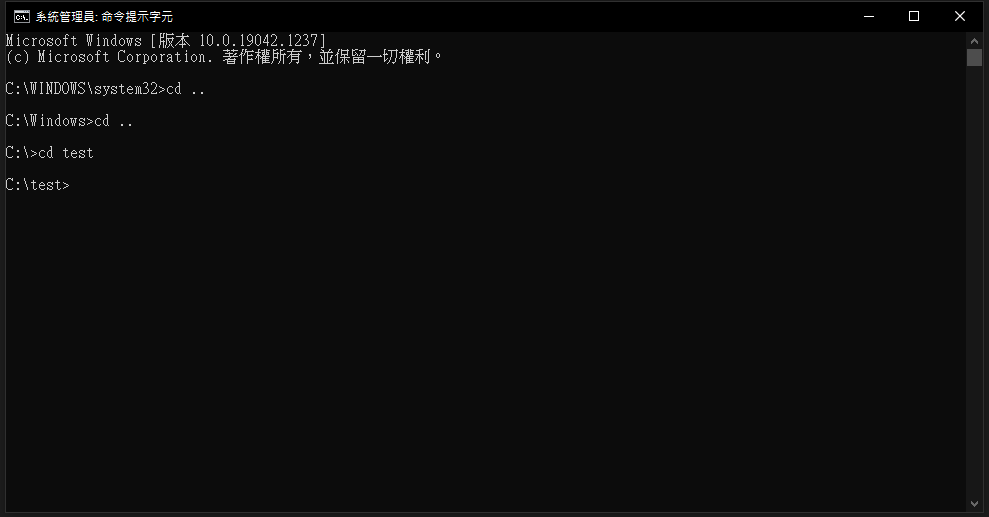
使用cd [目标资料夹名称] 代表移动到该资料夹 如下图
安装puppeteer module
cd移动到你要安装套件的资料夹之後输入
npm install puppeteer
这边指令意思是npm套件管理 安装 puppeteer
安装过程如下图
有关更多npm的知识可以查看以下维基或到NPM官方网站查看
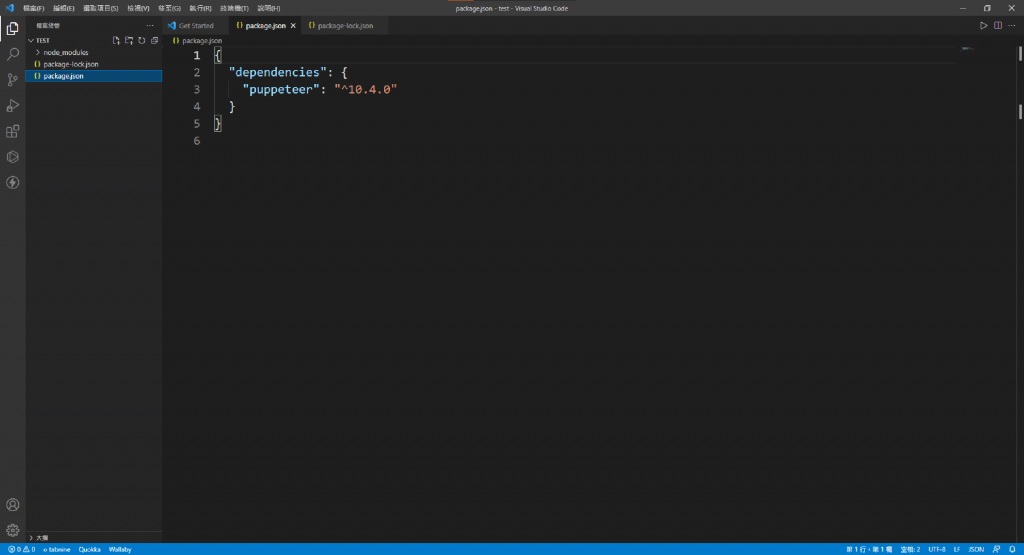
使用Visual Studio Code打开package.json查看dependencies内容含有puppeteer也代表记录了你安装了puppeteer
撰写第一支浏览器自动化程序
安装完毕後,接下来就可着手开始写js,我们创建一个叫做index.js的档案
这边我们要引入module
使用require函式在nodeJs环境当中要引入module
官方puppeteer建议使用async的方式来撰写
因此我们先选告一个scrape的async函式
说明可以观看注解
如下
const puppeteer = require("puppeteer"); //使用require引入puppeteer module
const scrape = async () => {
const browser = await puppeteer.launch({ //启动浏览器
headless: false, //是否设定无头模式,设定false将会真的开起浏览器反之亦然
});
const page = await browser.newPage(); //开启一个新分页
await page.goto("https://ithelp.ithome.com.tw/"); //前往该网址
await page.waitForSelector("body"); //等待body载入
setTimeout(function(){ browser.close(); }, 2000); //两秒後关掉浏览器
}
scrape();
执行puppeteer
开启命令提示字元记得cd到刚刚安装的资料夹底下後,输入node index.js
node [你的JS档案名称] 代表执行该JS档案
这时候你应当可以看见如下的画面
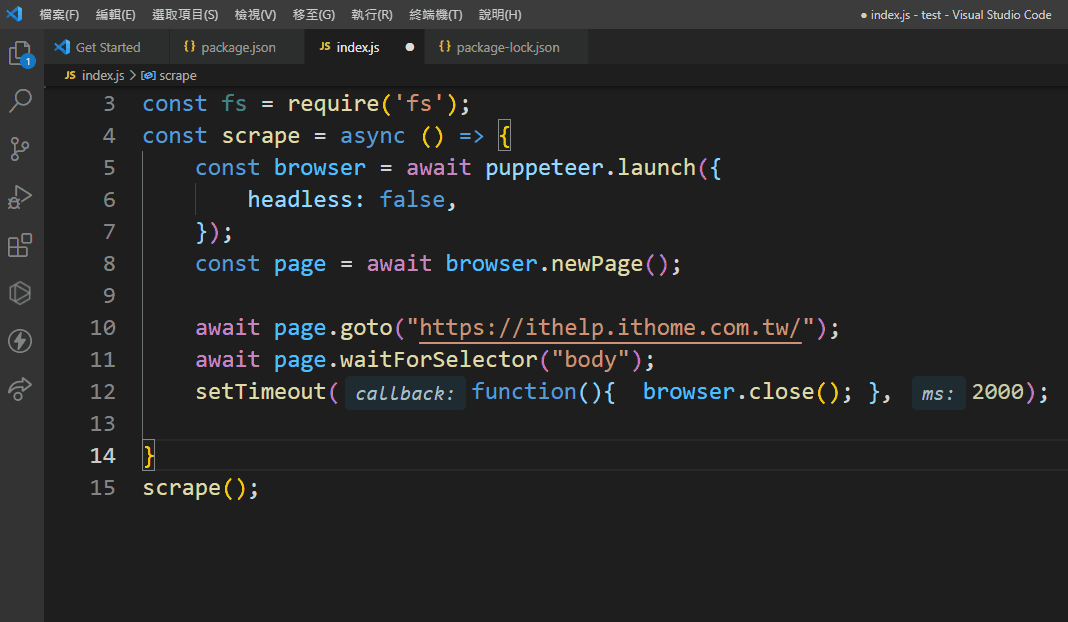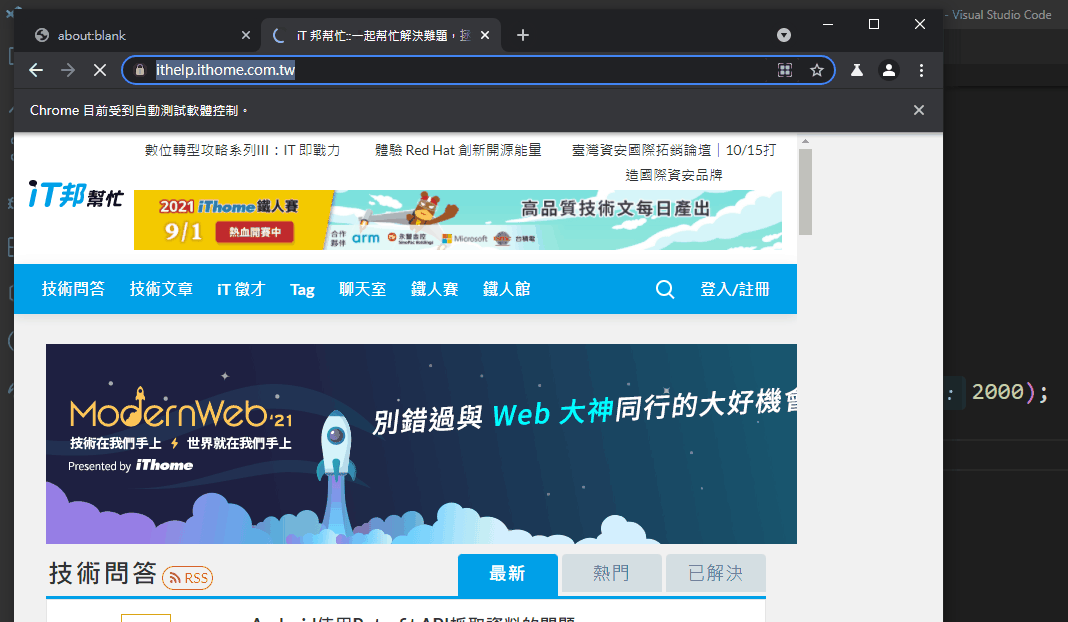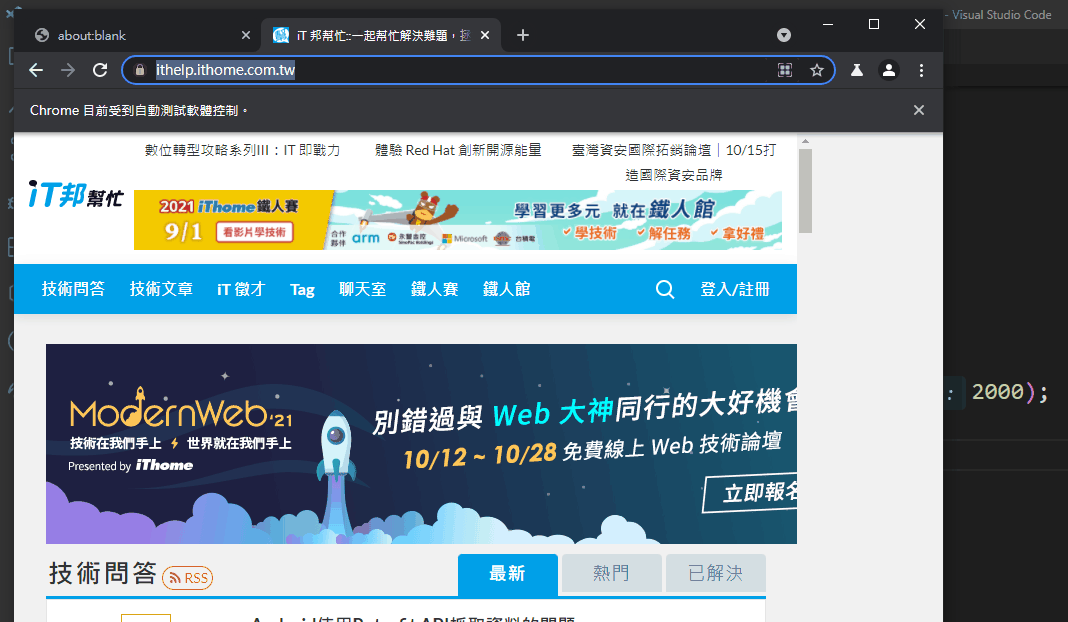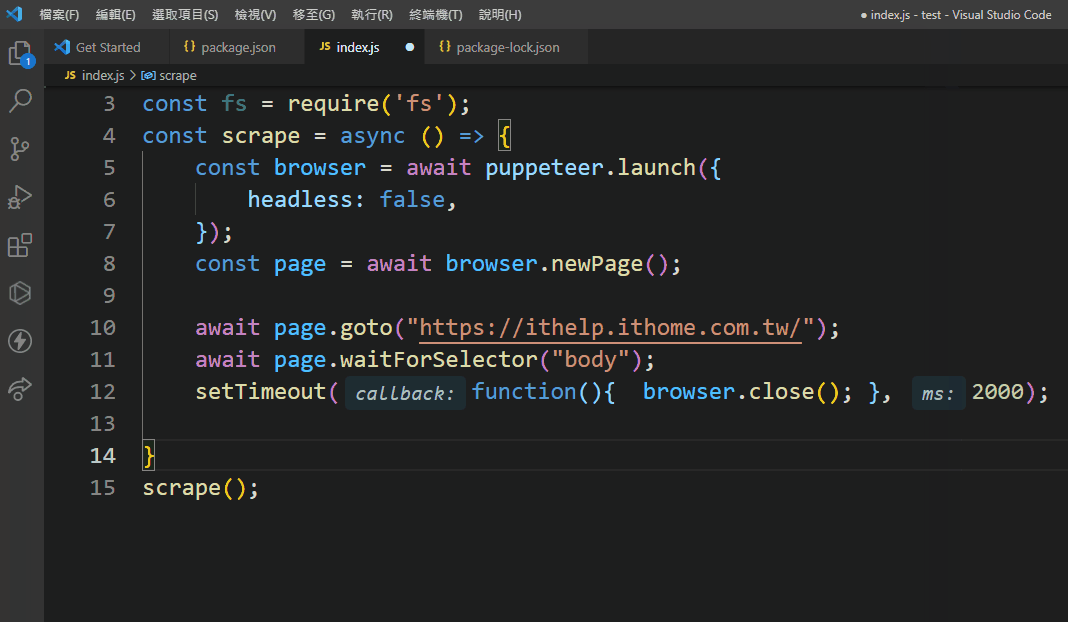
顺带一提如果使用命令提示字元执行
node [你的档案名称]想要中断执行程序,在命令提示字元按下ctrl+c就能退出了
由於设定headless: false,所以他会实际开启浏览器执行,如上图也可以发现浏览器会写Chrome目前受到自动测试软件控制
获取网页元素内容
page.evaluate()在该页执行Javascript
这边要介绍一个函式,我们预计使用page.evaluate函式来撷取DOM的内容在function里面就可以使用浏览器的API像是document.querySelector来选取元素,
await page.evaluate(function(){
})
按下ctrl+shift+i开启开发人员工具找到方形带有游标的图样按下去
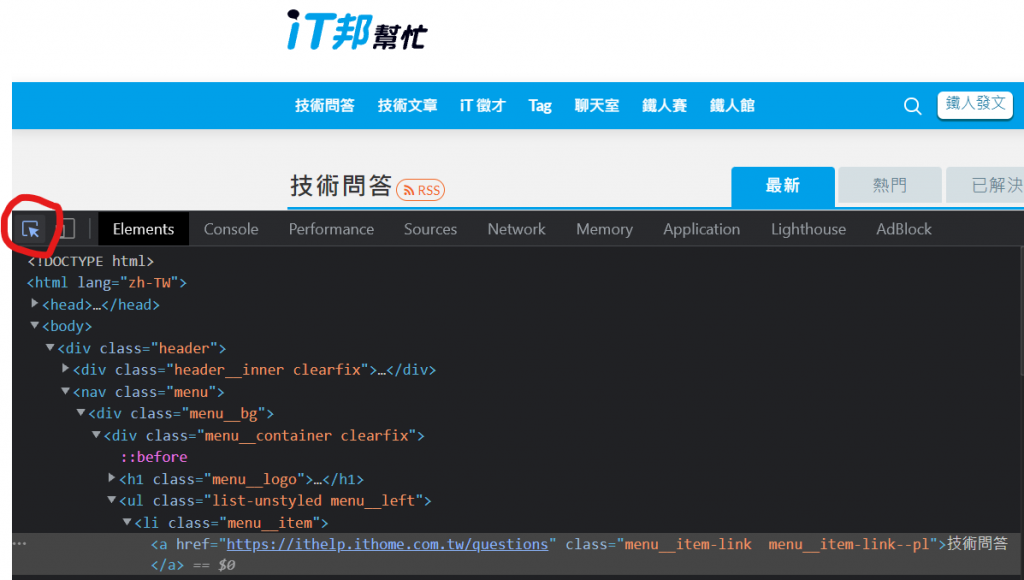
接下来你滑鼠游标移到网页要选的区域後,它就会自动帮你选到该element了如下图
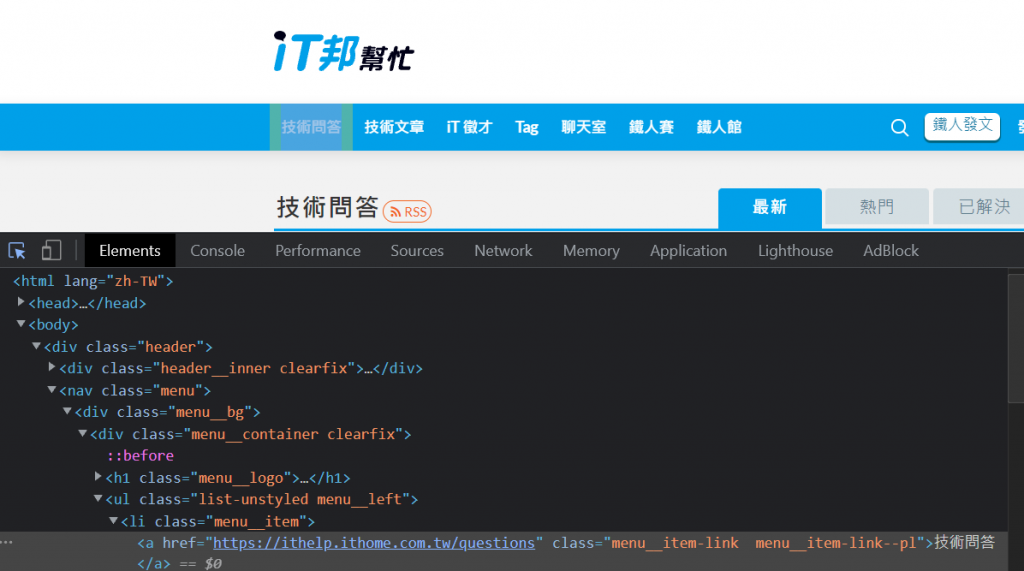
滑鼠移到该Element(这边以如下图的<ui>为例)按滑鼠右键选择Copy→Copy selector
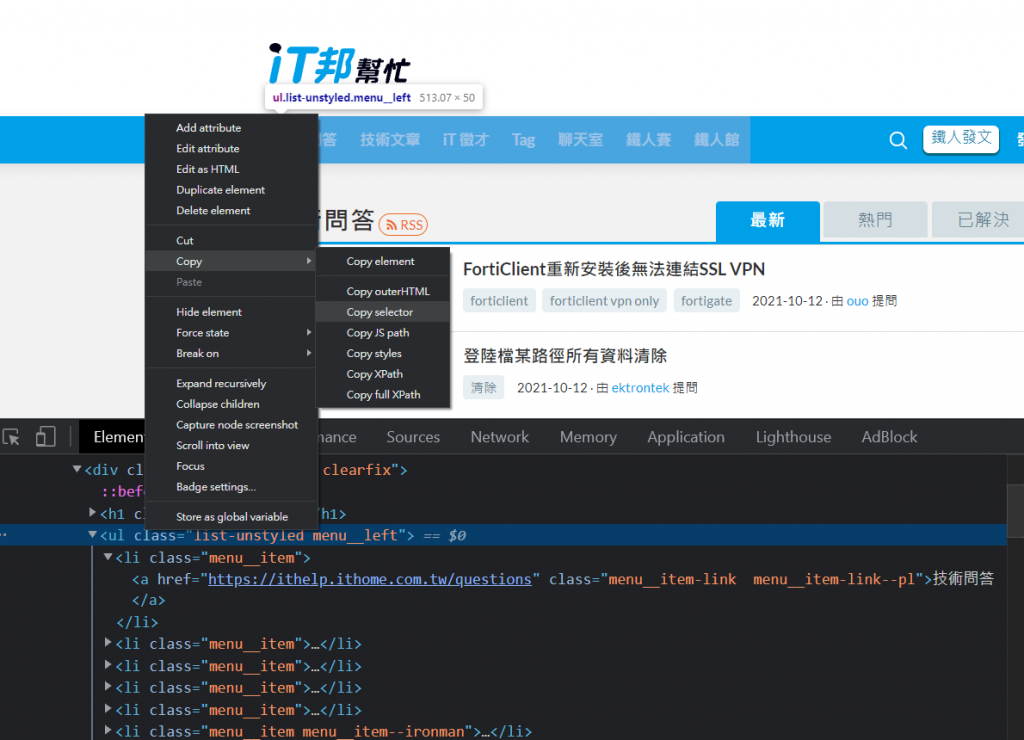
复制完後回到程序码 我们尝试着将刚刚复制的东西贴到evaluate里面的callbackFunction,然後使用innerText取里面的文字,最後return给str,然後我们试着将str印出来试试看
const puppeteer = require("puppeteer");
const fs = require('fs');
const scrape = async () => {
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
await page.goto("https://ithelp.ithome.com.tw/");
await page.waitForSelector("body");
let str = await page.evaluate(() => {
return document.querySelector("body > div.header > nav > div.menu__bg > div > ul.list-unstyled.menu__left").innerText;
})
console.log(str);
browser.close();
}
scrape();
最後应当会看到如下图,依照刚刚的程序码,得到了每个连结的文字内容
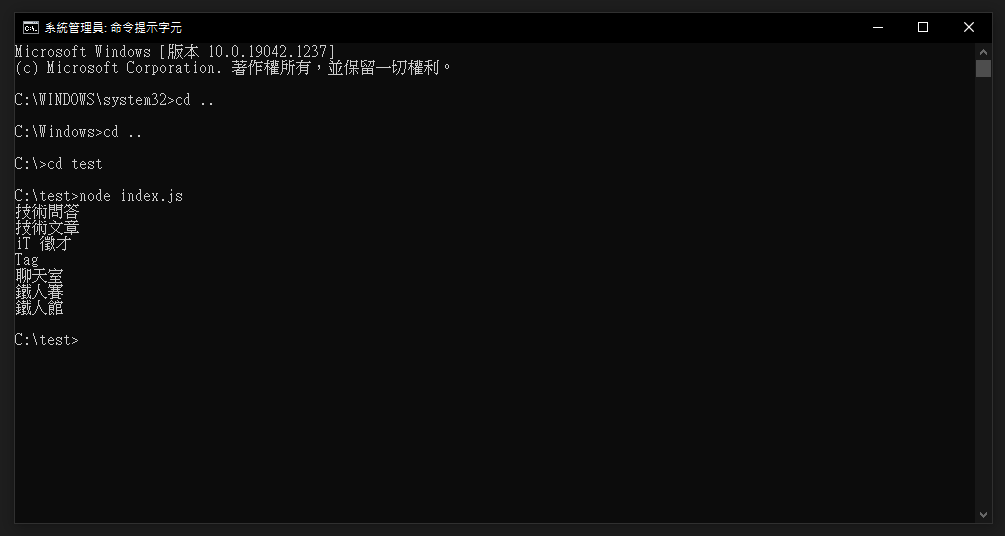
因此我们就可以使用此方法来获取网页的元素
产生json档案并写入资料
接下来我们要使用另一个moduler叫做fs来产生json档案
我们可以先撰写一段code并且使用node [你的档案名称.js],看看
可以先写在index.js这支档案里面并且使用node index.js执行
const fs = require('fs');
fs.writeFile('test.txt', '哈罗世界', function (err) {
if (err)
console.log(err);
else
console.log('json档案撰写完毕');
});
这时候你看到档案总管会发现应当多了一个文字档按叫做test.txt,它来自於你刚刚的程序码所产生的档案
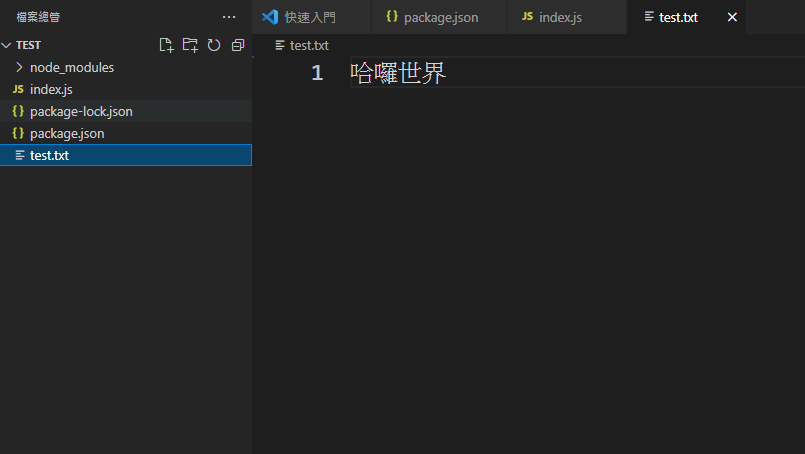
因此我们可以使用这个方式来产生json档案
结合刚刚所抓取网页的资料元素的程序码应当会如下
const puppeteer = require("puppeteer");
const fs = require('fs');
const scrape = async () => {
const browser = await puppeteer.launch({
headless: true,
});
//如先前的程序码故省略
//如先前的程序码故省略
//如先前的程序码故省略
browser.close();
return str;
}
scrape().then(function (data) {
let obj = {};
obj.data = data;
let objStr = JSON.stringify(obj);
console.log(dataStr);
fs.writeFile('test.json', objStr, function (err) {
if (err)
console.log(err);
else
console.log('撰写完毕');
});
}).catch(error => console.log(error.message));
我们创建一个Object来放所得到的资料,需要注意的地方是由於JSON格式必须为字串,因此使用JSON.stringify先将物件转成字串,最後使用刚刚引入的fs module来写入
fs.writeFile()函式
- 第一个带入的是档案名称
- 第二个是要写入的资料
- 第三个是callback可以用来处理错误或者执行成功的时要显示的字串
最後应当可以看到产生了一个json档案如下图

获取铁人赛d3.js的tag标签的所有文章
首先我们先找到你要的标签这里以d3JS为例如下图
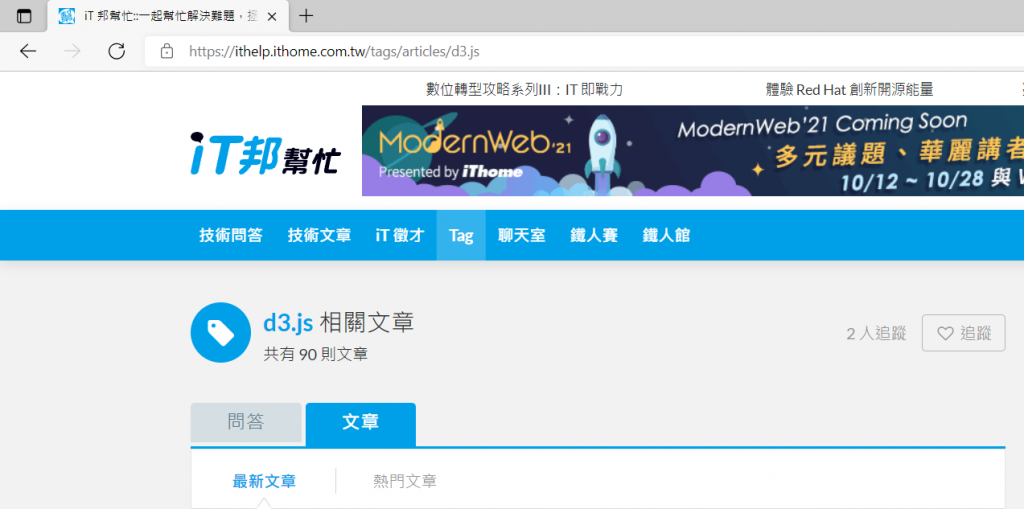
我们可以点到第二页查看可以发现网址多了?page=2
潜谈程序码构想
策略是先得知总共有几页,然後再依序进入该页面把所有的文章连结存成一个阵列後遍历它进入每篇文章,对每篇文章的浏览数、留言数等等存起来,以此类推就能得到所有文章的浏览数、留言数等等的资讯了。
前往该tag页面
在上方会宣告一个allPeoplePagesAry来存放所有文章的资料
另外多撰写await page.setDefaultNavigationTimeout(0);的原因主要是由於puppeteer的页面跳转如果大於30秒的话就会显示错误如下
error { TimeoutError: Navigation Timeout Exceeded: 30000ms exceeded,因此这边设定0(表示持续等待的意思)来让程序等待到画面跳转为止
程序码内容如下
const puppeteer = require("puppeteer");
const fs = require('fs');
const scrape = async () => {
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(0);
const allPeoplePagesAry = [];
await page.goto("https://ithelp.ithome.com.tw/tags/articles/d3.js?page=1");
await page.waitForSelector("body");
}
获取页数
接下来我们获取总共的页数
主要是获取网页最下方的页数

这边程序码选取倒数第二个数字里面的字串,因此写li:nth-last-child(2)
let PageNum = await page.evaluate(() => {
return Number( document.querySelector(".tag-pagination > ul li:nth-last-child(2)").innerText);
})
console.log("总共有"+PageNum+"页");
得到总共有几页之後我们就撰写一个for回圈来遍历页数
// 开始跑所有页数
for (let index = 1; index <= PageNum; index++) {
await page.goto(`https://ithelp.ithome.com.tw/tags/articles/d3.js?page=${index}`)
// 获取这一页所有的连结
let currentPageHref = await page.evaluate(() => {
let href = document.querySelectorAll(".qa-list__title-link");
let ary= [];
href.forEach(function (el){
ary.push(el.getAttribute("href"));
})
return ary;
})
}
获取当前页面所有连结
依照该页面css的class我们获取该页面所有文章的连结存到currentPageHref阵列里面
之後我们找出该页面所需要的内容元素存成一个物件,程序码如下
// 开始把这一页的连结给爬一爬
for(let i=0; i<currentPageHref.length; i++){
await page.goto(currentPageHref[i]);
await page.waitForSelector("body");
let obj = await page.evaluate(()=>{
let obj = {};
let articleStrNum = document.querySelector(".markdown__style").innerText.replace(/\s*/g,"").length;
let articleTitle = document.querySelector(".qa-header__title").innerText.trim();
let view = document.querySelector(".ir-article-info__view")||document.querySelector(".qa-header__info-view");
let viewNum = Number(view.innerText.match(/\d+/g));
let likeNum = Number(document.querySelector(".likeGroup__num").innerText);
let commentNum = Number(document.querySelector(".qa-action__link--reply").innerText.match(/\d+/g));
let postTime = document.querySelector(".qa-header__info-time").innerText;
obj.articleTitle = articleTitle;
obj.articleStrNum=articleStrNum;
obj.viewNum = viewNum;
obj.likeNum = likeNum;
obj.commentNum = commentNum;
obj.postTime = postTime;
return obj;
})
obj.currentPageHref = currentPageHref[i];
allPeoplePagesAry.push(obj);
console.log("这是第"+index+"页的第"+(i+1)+"个标题");
}
-
document.querySelector(".markdown__style").innerText.replace(/\s*/g,"").length;
使用replace结合正则表示式来让文章撰写的字数去除空白字元 -
document.querySelector(".ir-article-info__view")||document.querySelector(".qa-header__info-view");来存取querySelector 如果是铁人赛的文章class叫做.ir-article-infoview,如果是一般的文章叫做.qa-headerinfo-view -
Number(view.innerText.match(/\d+/g));解析观看次数
另外为了得知目前爬取的进度我在for回圈里面一并印出第几页第几个标题来显示当前页数和标题数。

生成JSON档案
最後我们撰写scrape()并在.then接收刚刚所取得的资料写入json档案,程序码如下
scrape().then(function(allPeoplePages){
console.log(allPeoplePages);
let allPeoplePagesStr = JSON.stringify(allPeoplePages);
fs.writeFile('allPerson.json', allPeoplePagesStr, function (err) {
if (err)
console.log(err);
else
console.log('写入完毕');
});
})
最後打开json可以看到如下图就代表恭喜你成功爬取到网页文章的元素了。
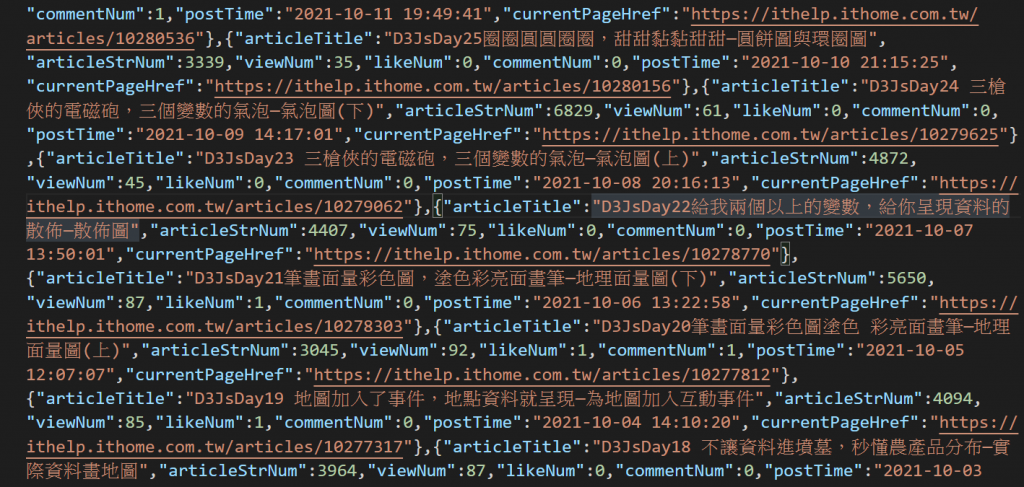
小小小总结
本日爬取到的Json资料预计将会作为d3Js的资料引入,期待明天如何处理这些资料和诉说什麽故事吧。
<<: Day28-JDK可视化监控工具:visualVM(四)
>>: D28 - 走!去浏览器玩转黑胶唱片 Web Audio API
【Day2】[资料结构]-阵列Array
阵列(Array)是一种常见的资料结构,常用来处理相同类型的有序资料,并存放在连续的记忆体空间中。但...
观察 Firefox Chrome 网页 DNS 查询哪些 Domain
观察 Firefox Chrome 网页 DNS 查询哪些 Domain Windows 有工具软件...
Day26 - AlertDialog
今天来练习第一个Dialog AlertDialog AlertDialog不仅仅提供使用者显示文字...
Day20:Flow 想在其他的执行绪执行,可以吗?
Flow 是属於 coroutine 范围项目,coroutine 中一个重要的特点可以轻易的切换执...
Day26:河内塔(Tower of Hanoi)
前言 终於结束了安全性演算法的部分,有兴趣的人可以进一步学习密码学,笔者想推荐一个课程: Udemy...