爬虫怎麽爬 从零开始的爬虫自学 DAY29 python网路爬虫开爬10-从网页爬取图片
前言
各位早安,书接上回我们介绍了如何抓取图片 URL 并储存图片,今天我们要结合之前的爬虫功能从网站上抓到图片连结再把图片存下来
开爬-图片爬虫
我今天程序的逻辑是
先把网页原始码 GET 下来分析後 再把图片连结所在的 < img > src 内的资料提出来
这个资料就是图片的 URL
之後再对图片的 URL 做 GET 的动作并转成二进位制
最後开档把这笔二进位制的图片资讯存进去 再关档
最後是把这些过程加上正确位置的回圈就能把网页上所有图片都存下来
程序码
import requests #用来对网站发出请求的套件
import os #用来处理资料夹的套件
import bs4 #用来解析HTML的套件
def saveImage(postUrl): #建立函式方便使用
request = requests.get(postUrl) #对网页发出请求
data = bs4.BeautifulSoup(request.text, "html.parser") #以HTML格式解析网页原始码
imageData = data.find_all('img') #抓取所有有<img>标签内的资料
path = r"C:\Users\weiwe\crawler\pet_get" #存放照片的路径
if (os.path.exists(path) == False): #判断主资料夹是否存在
os.makedirs(path) #不存在就建立一个
imgList = [] #建立LIST用来放图片URL
lenth = len(imageData) #建立变数纪录imageData内有几笔资料
for x in range(lenth): #建立用来回圈放全部图片URL 有几个就放几次
imgList.insert(x,imageData[x].attrs["src"]) #抓到src内的图片连结并新增进imgList内
for i in range(lenth): #用来印出全部图片
getImage = requests.get(imgList[i]) #抓取图片URL
image = getImage.content #将图片资讯转成二进位制
imageSave = open(path+"\img"+str(i)+".png","wb") #建立档案
imageSave.write(image) #将图片资讯写入档案内
imageSave.close() #关档
print("img"+str(i)+".png"+"下载成功") #告知该图片储存成功
postUrl = "https://www.ptt.cc/bbs/Pet_Get/M.1631051441.A.6C7.html" #欲抓取图片之网页的URL
saveImage(postUrl) #执行函式
print("下载完成") #告知程序结束
执行结果
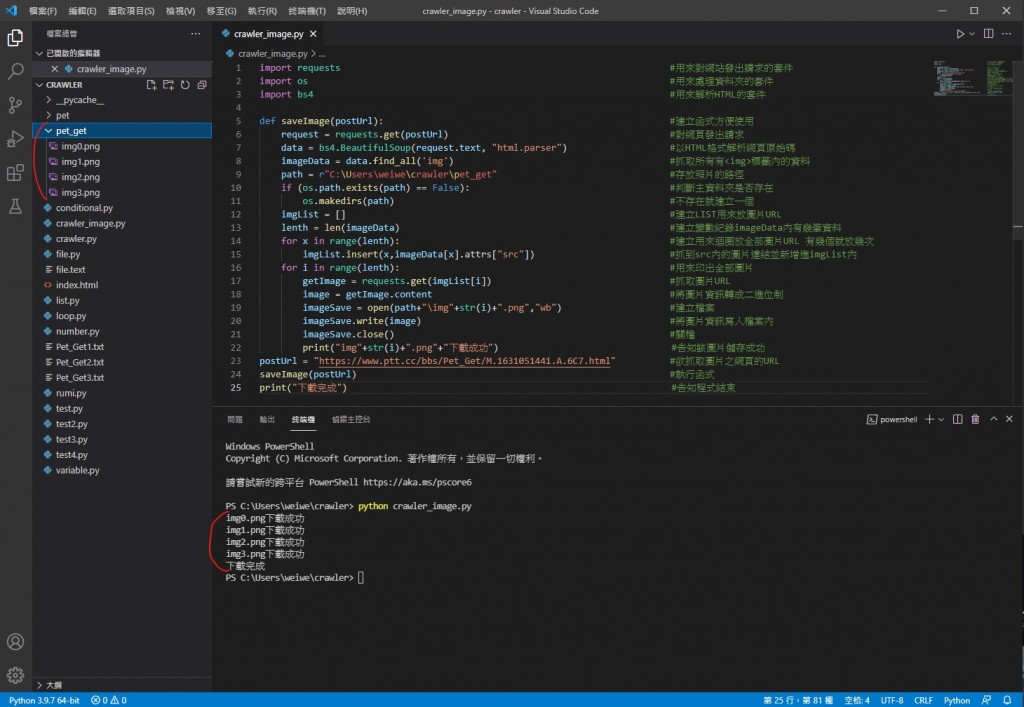
可以看到图片都储存成功了
接着我们看里面的档案
img0

img1
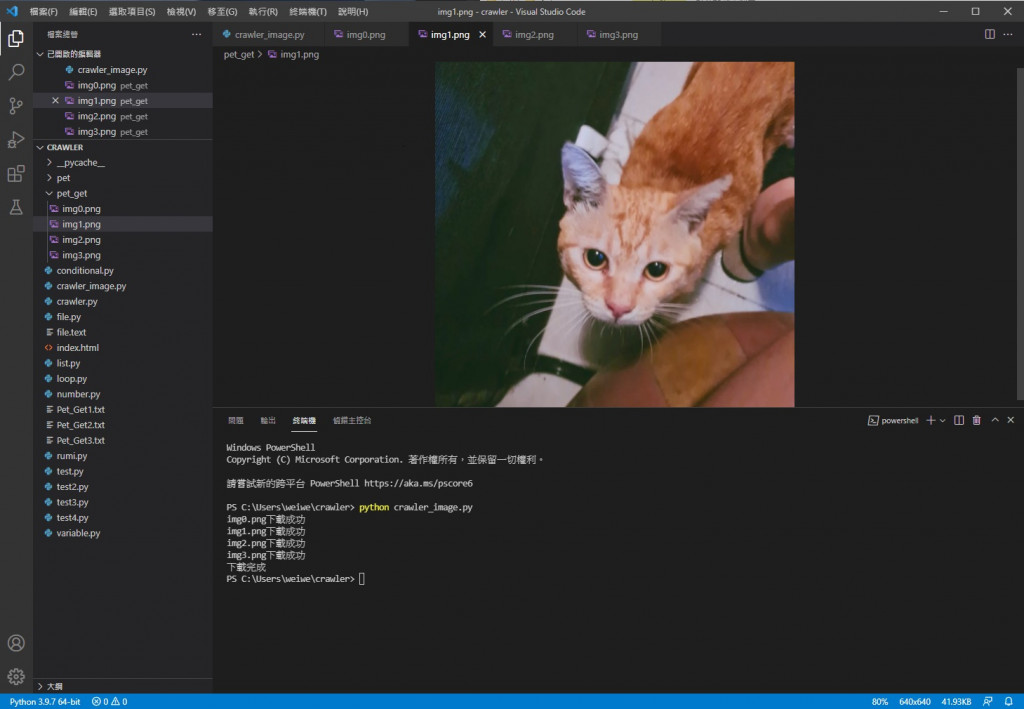
img2
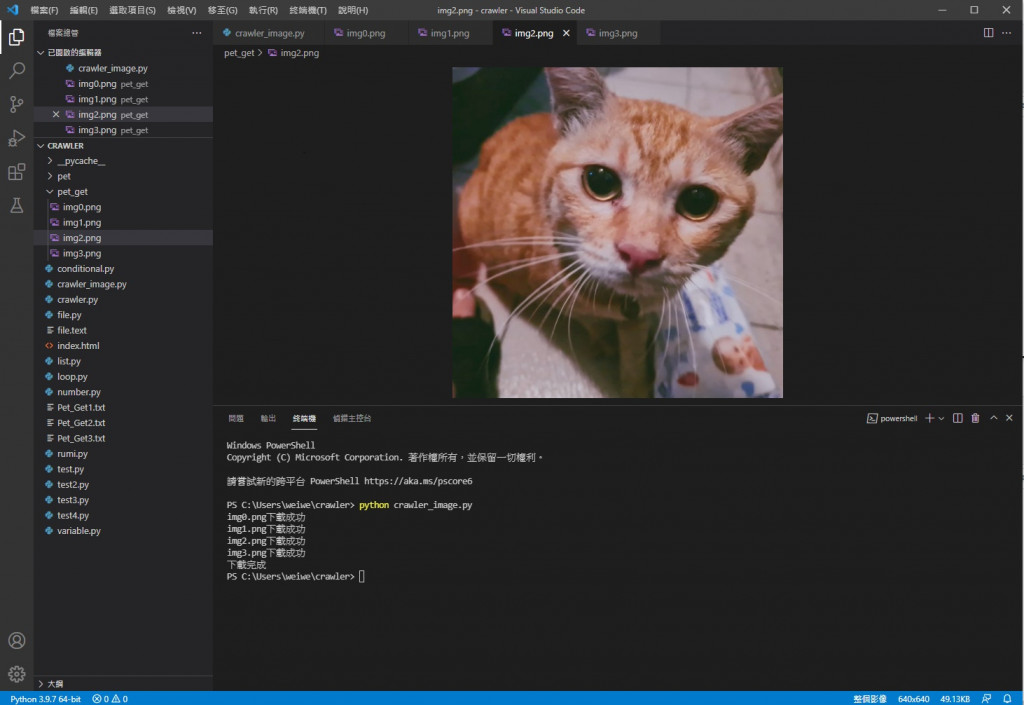
img3
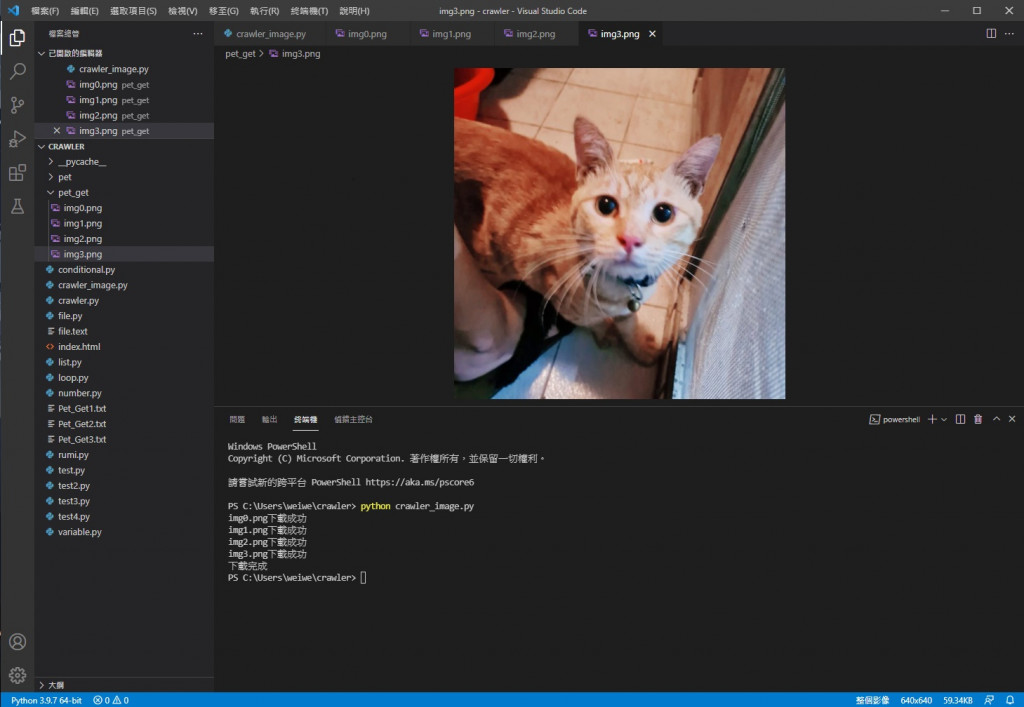
可以看到都储存成功也能正常显示
img0 会那样是因为那张图片已经被移除 存图片的网站就发一个图片已被移除的图来告知
我们可以去网页上看看
文章网址 https://www.ptt.cc/bbs/Pet_Get/M.1631051441.A.6C7.html
的确图片就是这些 第一张图也没东西
爬图成功
今天我们成功利用网页连结抓取网页上的图片了
明天是铁人赛最後一天 要来分享一下这次铁人赛的心得
参考资料:
http://jasonyychiu.blogspot.com/2019/10/python-syntaxerror-unicode-error.html
https://www.itread01.com/content/1549998217.html
https://www.itread01.com/content/1525927207.html
https://ithelp.ithome.com.tw/articles/10185694
https://www.cnblogs.com/zhaijiahui/p/8391701.html
https://blog.csdn.net/icydust/article/details/53113906
https://www.itread01.com/content/1548776360.html
早安闲聊区
你知道吗?
非洲有个国王竟然为了建设自己的国家在别国打工赚钱喔
每日二选一
如果有人对你态度不好你会保持风度还是以同样态度应对呢
>>: D29 / Jake 认为 Compose 不是 Compose? - Compose 是什麽
不花一分钱加强WiFi安全:爲Router免费升级WPA3加密、用得更安心
不花一分钱加强WiFi安全:爲Router免费升级WPA3加密、用得更安心 WPA3是什麽?WPA3...
[VSCodeVim] Vim的基本操作、模式与状态列
Vim的基本操作、模式与状态列 [系列文目录] 在使用Vim之前,让我们来认识一下Vim的模式(Mo...
[day-14] 认识Python的资料结构!(Part .1)
甚麽是资料结构? 资料结构(Data structure) 简单来说,就是一个含有结构的资料型别...
Day 08:分治法与递回(1)
再继续写其他更快的排序演算法之前,先来写分治法(divide-and-conquer paradig...
Day 20 中场休息,来做点酷东西(型别修正跟除点小虫)
今天做了几件小事 定义 Project 的型别 class 增加 Project 的状态 定义 Li...