以Postgresql为主,再聊聊资料库 width_bucket() 的介绍
前天的趣味SQL, 经过大家热烈的响应,有提到 width_bucket()
https://ithelp.ithome.com.tw/questions/10201169
今天我们就来介绍一下 width_bucket()
--------------------
-- Qucik Start Sample
with t1(n) as (
select generate_series(1, 10)
)
select n
, width_bucket(n,1,10,2)
, width_bucket(n,1,10,9)
from t1;
n | width_bucket | width_bucket
----+--------------+--------------
1 | 1 | 1
2 | 1 | 2
3 | 1 | 3
4 | 1 | 4
5 | 1 | 5
6 | 2 | 6
7 | 2 | 7
8 | 2 | 8
9 | 2 | 9
10 | 3 | 10
(10 rows)
with t1(n) as (
select generate_series(1, 100)
), t2 as (
select n
, width_bucket(n,1,101,4) "bucket_n"
from t1
)
select bucket_n
, min(n)::text || ' ~ ' || max(n)::text as "bucket_range"
from t2
group by bucket_n
order by bucket_n
;
bucket_n | bucket_range
----------+--------------
1 | 1 ~ 25
2 | 26 ~ 50
3 | 51 ~ 75
4 | 76 ~ 100
(4 rows)
--------
-- 边界, 含低限 不含高限
with t1(n) as (
select generate_series(1, 3)
)
select n
, width_bucket(n,1,3,3)
, width_bucket(n,1,4,3)
from t1;
n | width_bucket | width_bucket
---+--------------+--------------
1 | 1 | 1
2 | 2 | 2
3 | 4 | 3
(3 rows)
-- 所以 1 ~ 3, 高限必须大於 3
-- 看 1 ~ 12 分三组
with t1(n) as (
select generate_series(1, 12)
)
select n
, width_bucket(n,1,12,3)
, width_bucket(n,1,13,3)
from t1;
n | width_bucket | width_bucket
----+--------------+--------------
1 | 1 | 1
2 | 1 | 1
3 | 1 | 1
4 | 1 | 1
5 | 2 | 2
6 | 2 | 2
7 | 2 | 2
8 | 2 | 2
9 | 3 | 3
10 | 3 | 3
11 | 3 | 3
12 | 4 | 3
-- Out of Range
with t1(n) as (
select generate_series(-2, 14)
)
select n
, width_bucket(n,1,13,3)
from t1;
n | width_bucket
----+--------------
-2 | 0
-1 | 0
0 | 0
1 | 1
2 | 1
3 | 1
4 | 1
5 | 2
6 | 2
7 | 2
8 | 2
9 | 3
10 | 3
11 | 3
12 | 3
13 | 4
14 | 4
(17 rows)
-------------
-- 1 ~ 10 分到 10个桶子, 可以用以下两种方式.
with t1(n) as (
select generate_series(1, 10)
)
select n
, width_bucket(n,1,11,10)
, width_bucket(n,1,10,9)
from t1;
n | width_bucket | width_bucket
----+--------------+--------------
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
4 | 4 | 4
5 | 5 | 5
6 | 6 | 6
7 | 7 | 7
8 | 8 | 8
9 | 9 | 9
10 | 10 | 10
(10 rows)
-- 两种结果看起来一样.但是...
-- 我们来看 1 ~ 100, 分到 10 个 桶子.
with t1(n) as (
select generate_series(1, 100)
), t2 as (
select min(n) minn
, max(n) maxn
from t1
)
select width_bucket(n, minn, maxn+1, 10) bucket
, int4range(min(n), max(n), '[]') as range
, count(*)
from t2
, t1
group by bucket
order by bucket;
bucket | range | count
--------+----------+-------
1 | [1,11) | 10
2 | [11,21) | 10
3 | [21,31) | 10
4 | [31,41) | 10
5 | [41,51) | 10
6 | [51,61) | 10
7 | [61,71) | 10
8 | [71,81) | 10
9 | [81,91) | 10
10 | [91,101) | 10
(10 rows)
-- 因为 default 表示法是 [), 低含高不含
-- 所以 [1,10] 会表示成 [1,11)
with t1(n) as (
select generate_series(1, 100)
), t2 as (
select min(n) minn
, max(n) maxn
from t1
)
select width_bucket(n, minn, maxn, 9) bucket
, int4range(min(n), max(n), '[]') as range
, count(*)
from t2
, t1
group by bucket
order by bucket;
bucket | range | count
--------+-----------+-------
1 | [1,12) | 11
2 | [12,23) | 11
3 | [23,34) | 11
4 | [34,45) | 11
5 | [45,56) | 11
6 | [56,67) | 11
7 | [67,78) | 11
8 | [78,89) | 11
9 | [89,100) | 11
10 | [100,101) | 1
(10 rows)
-- 分 9 桶, 就是 每桶 11 个, 100 分到第 10 桶.
-- 所以比较好的方式是,桶数是我们想要的,高限略大的方式.
------------
-- 不等宽度分组, 例如一些 等第
-- 传统方式可以使用 case when 语法 或是 建立对照表, 用 join 方式.
-- 在此就不举例.
with t1(n) as (values
(40),(59),(60),(70),(75),(89),(99),(100),(101)
)
select n
, width_bucket(n, array[60, 70, 90, 101])
from t1;
n | width_bucket
-----+--------------
40 | 0
59 | 0
60 | 1
70 | 2
75 | 2
89 | 2
99 | 3
100 | 3
101 | 4
(9 rows)
-- 注意到 101 是 4, 60 是 1, 60以下是 0
---------------
-- 也可以用来做 时段分析.
-- 假设 0点到7点 可能因为这段的事件较少, 分成第一段.
-- 8点到18点 一小时分一段, 当然也可以分到更细,举例就单纯一点.
-- 18点到24点 每两小时分一段.
create table it201122 (
id int generated always as identity
, ts timestamp not null
);
insert into it201122 (ts)
select 'yesterday'::timestamp + random() * interval '8 hours'
from generate_series(1, 500);
insert into it201122 (ts)
select '2020-11-21 08:00:00'::timestamp + random() * interval '10 hours'
from generate_series(1, 1e5);
insert into it201122 (ts)
select '2020-11-21 18:00:00'::timestamp + random() * interval '6 hours'
from generate_series(1, 2000);
commit;
-- 分小时统计,相信大家都很熟练了.
-- 用 width_bucket() 不同时段的方式.
with t1 as (
select extract(HOUR FROM ts)::integer as hour
from it201122
)
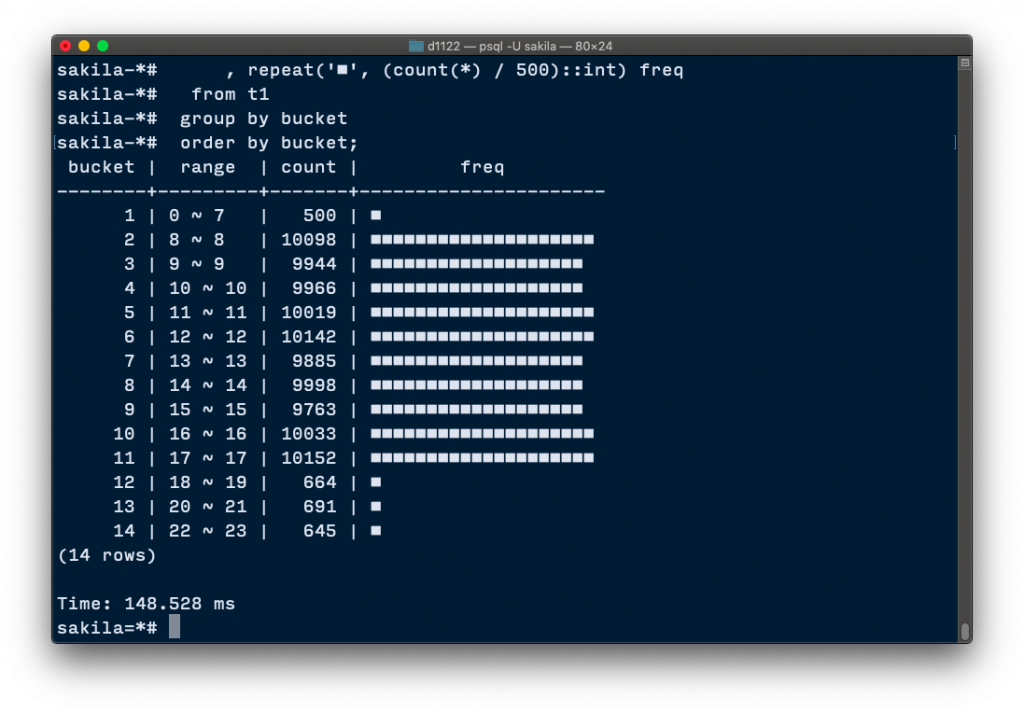
select width_bucket(hour, array[0, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 22, 24]) bucket
, min(hour)::text || ' ~ ' || max(hour)::text as range
, count(*)
, repeat('■', (count(*) / 500)::int) freq
from t1
group by bucket
order by bucket;
bucket | range | count | freq
--------+---------+-------+----------------------
1 | 0 ~ 7 | 500 | ■
2 | 8 ~ 8 | 10098 | ■■■■■■■■■■■■■■■■■■■■
3 | 9 ~ 9 | 9944 | ■■■■■■■■■■■■■■■■■■■
4 | 10 ~ 10 | 9966 | ■■■■■■■■■■■■■■■■■■■
5 | 11 ~ 11 | 10019 | ■■■■■■■■■■■■■■■■■■■■
6 | 12 ~ 12 | 10142 | ■■■■■■■■■■■■■■■■■■■■
7 | 13 ~ 13 | 9885 | ■■■■■■■■■■■■■■■■■■■
8 | 14 ~ 14 | 9998 | ■■■■■■■■■■■■■■■■■■■
9 | 15 ~ 15 | 9763 | ■■■■■■■■■■■■■■■■■■■
10 | 16 ~ 16 | 10033 | ■■■■■■■■■■■■■■■■■■■■
11 | 17 ~ 17 | 10152 | ■■■■■■■■■■■■■■■■■■■■
12 | 18 ~ 19 | 664 | ■
13 | 20 ~ 21 | 691 | ■
14 | 22 ~ 23 | 645 | ■
(14 rows)
-- 若使用分小时的方式,有些时段的量太小,使用width_bucket()
-- 更灵活的让我们来分析资料.
-- width_bukcet() 与 ntile() 的差异,我们将在之後再介绍.
>>: WP Rocket 一整年难得的7折优惠+7款外挂测速比较
Day11 : Docker基本操作 Docker Net篇
前几天我们讲了如何建立Container,每个Container会包含一项服务,如前端、後端、资料库...
DAY 4:Guarded Suspension Pattern,你不会死的,因为我会保护你
什麽是 Guarded Suspension Pattern? 如果 thread 执行时条件不符,...
股市/程序交易
股市/程序交易 https://wolkesau.medium.com/股市-程序交易-ba9898...
图的连通 (5)
9.2 找出分离点对 (Separating Pair) 如果一个点的子集合移除以後,会让图 G 变...
【Day 06】领域驱动设计的战略设计(Strategic Design)
前言 我们常会使用业务性质来界定领域范围(Bounded Context),例如,采购、销售、库存、...