[Day 28] 从零开始学Python - 深度学习Keras:如果你能预知这条路的陷阱,我想你依然错得很过瘾
注:本文同步刊载在Medium,若习惯Medium的话亦可去那边看呦!
接下来让我们来聊聊Python在深度学习的部分。
事实上很多iT邦帮忙的神人们在AI & Data组应该都有介绍到深度学习,
可能是使用Tensorflow, PyTorch或Keras。
本篇的重点不是要一篇打各路大神们的三十篇,
而是要简单介绍一下AI及深度学习的概念,
给大家做一个入门,後续要再深入的话,就可以再去参考更多其它的学习资源。
那麽,我们先聊聊什麽是AI。
人工智慧(Artificial Intelligence),
过往是源自於一些根本的假设以及传说所揉合而成。
人类对於机器人有一些想像,想像我们可以做出人造人,
这样的机器人具备自我思考的能力,因而可以透过不断的思考和选择达到进化;
同时加上了中古时期对於链金术的想像:将意识赋予至无生命的物质当中。
综合以上,因而我们对於一个AI的想法,
大体上不外乎是以「它会思考」这个角度来出发。
那麽,怎麽样才算是会思考呢?
有一位电脑科学家图灵(Alan Mathison Turing),
提出了一个着名的测试方式:图灵测试。
图灵测试简单来说,就是让一个人(A),
分别去跟两个不同的对象(B、C)交谈,
过程中只透过文字,
A不会看到B、C的模样或听到声音;
最终交谈完毕以後,
由A来判断B、C是否有实质的不同,或者说谁更像是人。
如果有一个机器比另一个人让A更觉得它像人的话,
即通过图灵测试。
这样子的测试後来衍生出很多很有趣的例子,
例如有个名为Eliza的聊天机器人,
会将对方讲出来的句子分析其主词及关连性,
针对当中的关键字词来回答;
或者它也会做一些重组,再拿你讲过的话来回答你XD!
而这种模式和人互动下,反而很多人会以为Eliza懂他/她,
殊不知完全掉入了程序设计师的陷阱XD
扯远了,让我们拉回来谈AI。
我们近几十年在拿AI这个词来描述事物时,
其概念和范围其实也是不断在变动的。
以比较之前的看法来说,AI通常会被当做是:
使用确定的规则判断,使得机器得以按照这个规则去运作,
从而在某些方面表现出像是人类在做思考判断一样。
比如电脑游戏中玩家操纵的角色跟NPC对话时,
NPC会依照它的「人设」(也就是游戏开发者原先对其的设定),
以及当前的一些条件状况,对玩家做出回应。
当然,我们可以很轻易地看出这是写好的规则判断,
原因就是这个NPC可能讲没几句话就重复循环,
或者是一直要你去打10只母鸡回来交任务XD
再比方说过往的围棋或象棋软件,
甚至打败过西洋棋棋王的电脑「深蓝」,
也都脱离不开使用写好的规则来计算下一步的范畴,
这样子的AI,我们将其称为rule-based AI。
按规则走的优点是,
当事情是确定的,且符合过往能归纳的范畴,
那麽机器处理的能力就会非常好。
缺点当然就是一旦遇上没有被界定的情况,
那机器就会不知道该怎麽办了XD!
AI在经历过几次兴起以及几次寒冬以後,
得益於GPU性能的提升,能加速大量的平行化运算的矩阵运算的原因,
深度学习(Deep Learning)在近年来兴起了。
深度学习所建立的AI,和以往以规则为出发的AI不同,
它主要是透过所谓的人工神经网路(Artificial Neural Network, ANN),
在建立起一个结构以後,透过不断地输入资料,
输出结果,检查结果与正确答案的差距,再对神经网路各自的权重(weight)做修正,
最终让每次的输入所得到的输出结果,能接近正确答案。
举例来说:
假设读者的面前有一棵树,
rule-based的做法会是:
「这边有树枝,这边有树叶,中间有枝干连接,
它们的颜色在XX~OO之间,所以这是一棵树」
深度学习的做法则是:
「反正这就是一棵树就对了!不知道?没关系,
我多带你看几个:A这个是树,B这个不是树,
......好,那你这样应该可以分辨树了对吧?」
深度学习在神经网路的类型的这块,
相对比较像人类的小孩子在学习一样,
透过不断的归纳,最终小孩子在心里面产生一套分辨方式,
这个分辨方式可能说得出来,可能说不出来,
但最终他/她就是会讲得出「这是一棵树,这是车车」这样子的分类。
上面提到的深度学习的方式,
在具体到人工神经网路上状态又是怎麽样的呢?
比较粗略的来说,
人工神经网路是由神经元(neurons)彼此以突触连接而成的,
不同的突触,传递相同的讯号时会产生不同的强弱变化,
通常我们称之为权重(weights)。
如同刚刚所说的,
我们会透过检查正确答案和目前机器输出的答案的差距,
来修正权重,最常见的方式,
就是使用反向传播(backpropagation, BP),
加上梯度下降法(gradient descent)或其他算法,
来尽力收敛和正确答案的差距。
这个改善神经网路的过程我们通常称之为模型训练(model training)
那麽,接下来谈谈Keras。
Keras原本是一个用於快速开发深度神经网路的框架,
立基於各项比较常见的框架之上,
例如TensorFlow(Google Brain团队所开发), Theano, PlaidML等。
但近年来最主要的支援是放到了TensorFlow上面,
同时TensorFlow也主动将Keras的函式库纳入到其中,
我们接下来的范例会基於TensorFlow上的Keras来操作。
如果在自己的电脑上想安装TensorFlow/Keras的话,
可以参考官网:
https://www.tensorflow.org/install/pip?hl=zh_tw
请留意,如果是要用到gpu的话,
你必须要安装的是tensorflow-gpu。
由於不是每个人的家里的GPU都很精良,
所以下面我们主要会介绍如何跟着TensorFlow上的官网提供的colab范例来做。
下面我们会一步步带各位走过最基本的范例:Fashion MNIST的分类,
请从Basic classification: Classify images of clothing
找到Run in Google Colab并将其打开。
在Colab的网页中,
当看到"[ ]"的格子时,
代表一组可以执行的程序码,
滑鼠移动到上面,会显现播放键,
只要按下去就会执行一次。
执行完後显示的数字代表它已经被执行过了,
且是第几个被执行的格子。
首先我们看到前导的部分:
我们要使用到的一般会有tensorflow本身以及keras,
所以要进行import,同时,前面我们提过的numpy以及matplolib也都会用到,
让我们一起导进来。
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__) # 印出当前tensorflow的版本,目前是2.3.0
再来,我们要汇入一组资料集(dataset)。
资料集一般是指针对特定目标或种类收集整理而成的资料,
一些比较代表性的资料集如Cifar-10, MNIST, ImageNet等,
依照使用的状况不同,有些会被拿来当成基本教学范例,
有些则是会被拿来当成评估训练方法好不好的标准。
以Fashion MNIST来说,
就是一个在MNIST(手写0~9的图形资料集)被用到太无聊的状况下,
可能打算换换口味才换过来的资料集XD。
Fashion MNIST当中有7万张灰阶图,
内容是10种不同的服饰,如鞋子、包包、衣服、裤子等。
以这个范例来说,我们的目的,
就是训练出一个能够良好地辨认出一张图片是哪个种类的服饰的模型。
我们要将Fashion MNIST下载後,分为用来训练的资料,以及用来测试用的资料:
为什麽要分呢?因为如果全部都拿来训练的话,
那麽在测试这个训练结果时,我们怎麽知道说,
这个模型(model)回答的好,是因为它真的懂了,
还是是因为背熟考古题呢XD?
毕竟我们是希望它找出一个自己能够辨别的标准,
而不是背答案。
这边的label(标签),指的是该张图片,是属於这个资料集的第几类,
这样到时候训练时才能够知道模型有没有找错。
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
在这个资料集中,我们标记为0的是T-shirt/top,
1的是Trouser, 以此类推,将每个类别的名称记录下来。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
接着检查一下刚刚拿到的资料:
train_images.shape # (60000, 28, 28) -> 60000张,每张像素是28x28
len(train_labels) # 60000 -> 对应的标签当然就也是60000张
train_labels # array([9, 0, 0, ..., 3, 0, 5], dtype=uint8) -> 0~9的种类,共10种
test_images.shape # (10000, 28, 28) -> 10000张用来做为测试的图像
len(test_labels) # 10000 -> 对应的标签当然是10000
接着我们来预先处理一下资料,
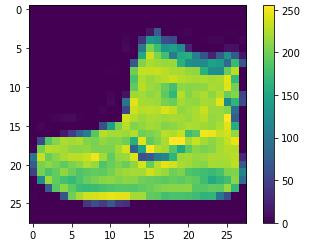
使用plt.imshow()可以将进行图像绘制,
我们就拿train_images[0]这张来看看:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar() # 用来显示灰阶影像(0-255)
plt.grid(False)
plt.show()
通常我们要处理资料时,
我们要将其标准化到0~1的范围,
这样子才不会因为不同的资料的尺度(scale)不同,
影响到模型的训练或它们对於结果影响的比例。
由於灰阶影像的值是0~255,所以我们可以选择全数除以255.0来等比例缩小,
接着再取前25张图来检查处理过的资料是否正常仍可显示:
train_images = train_images / 255.0
test_images = test_images / 255.0
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1) # 5*5的排列方式
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary) # 范围0~1时要选binary
plt.xlabel(class_names[train_labels[i]]) # 在x轴的位置显现分类名
plt.show()
接下来是模型的部分。
要训练模型之前,首先我们要先将模型的神经网路建构起来,
通常状态下神经网路是以层(layer)为单位,
层与层彼此之间进行连接,多个层最终构成一个神经网路。
Sequential: 代表前面的往後面的承接
Flatten: 代表将输入的东西摊平成一维(28*28=784)
Dense: Dense layer又称全连接层,也就是像握手一样,
上一层的每个神经元和这层的神经元的每一个组合都有连接到
activation: 激励函式(activation function),简单来说,
就是一个让整个神经连接呈现不是线性的状态。
因为若是一个模型可以用很简单的公式或者线性可表达的函数算出来,
这样子的状态不是深度学习所要的,因为如果一般的方式可以算的话,
深度学习并没有比较具备优势。
(其它目的还有避免过拟合或节省部分计算的考量,我们暂且不深入探讨)
# 最後一层是10个神经元,目的就是刚好分成10类
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
完成一个模型後,我们要进行compile的动作,
将其它附带的条件给加上。
Loss function(损失函数):用来评估说模型现在给出的答案和正确答案的差距的函式,
这个可以有很多种类,这里用的是用来衡量分类的SparseCategoricalentropy。
Optimizer(优化器):我们在修正时,不会直接将Loss给出来的差直接处理掉,
而是会有一个评估要往哪个方向修正多少的方法做为基准。
(因为这个点完全相等并不能代表另一个会表现好)
除了adam以外,sgd, adagrad等都是常见的优化器。
Metrics(指标):在训练的过程中我们会想看的中途状况,
accuracy是计算每次有正确被分类的图片的比例。
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
接下来就要开始训练啦!
Keras中是使用model.fit指令,意思是这个模型要尽力去符合实际的正确标准。
epochs是代表以前面60000张图片做为一整组的话,
我们想要让同一个组让机器训练过几次。
指令下了以後就会在下方看到进度条跑动,
以这次训练来说,
目前训练的准确度在最後一次是0.9100,也就是91%。
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.5019 - accuracy: 0.8236
Epoch 2/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3788 - accuracy: 0.8633
Epoch 3/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3425 - accuracy: 0.8743
Epoch 4/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3169 - accuracy: 0.8840
Epoch 5/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2985 - accuracy: 0.8910
Epoch 6/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2821 - accuracy: 0.8957
Epoch 7/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2713 - accuracy: 0.8996
Epoch 8/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2594 - accuracy: 0.9035
Epoch 9/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2499 - accuracy: 0.9067
Epoch 10/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2429 - accuracy: 0.9100
<tensorflow.python.keras.callbacks.History at 0x7f88189846a0>
但只会做考古题不算真本事,我们还得看看,
这个模型测试没看过的图片时,准确度会是怎麽样:
我们将最终使用test的图片来检验的动作称之为evaluate(评定)。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
# 结果是88.3%左右
313/313 - 0s - loss: 0.3400 - accuracy: 0.8827
Test accuracy: 0.8827000260353088
训练好的模型,当然不应该只拿来检查准确度,
也要可以用来检视新的图片:
一般状况下,我们会使用一个softmax层来处理。
softmax层能将一群输入的值,按照一个分配方式压缩,
最终所有值都在0~1之间,且加总起来会刚好等於1,
我们就拿这个输出来做为判断某个输入的图是什麽种类的机率有多少。
# 连接softmax层
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
# 用predict方法来进行推论(inference)
predictions = probability_model.predict(test_images)
# 每一个predictions的元素当中包含了预测这个图分别是种类0~9的机率值
predictions[0]
array([2.3251364e-07, 1.5796850e-08, 5.2541566e-07, 9.3214476e-09,
7.9444156e-08, 1.8098523e-03, 5.7661474e-08, 8.4252998e-02,
1.4421660e-07, 9.1393608e-01], dtype=float32)
# 我们要取机率最高的当做是我们判断它是哪一种类型
# 使用np.argmax,其结果看起来跟实际上的答案一致,代表有答对XD
np.argmax(predictions[0])
9
test_labels[0]
9
下面colab的范例也提供了两个函式来提供视觉化的判断,
在此就不一一解释:

我们可以看到模型也是有答错的时候XD:
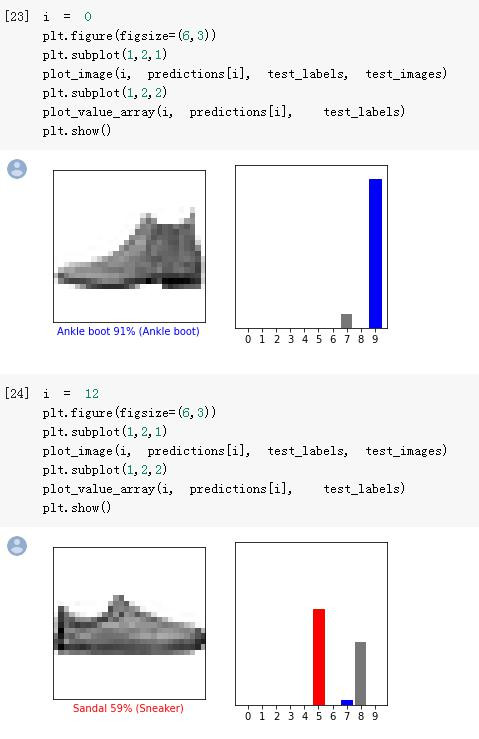
後面还有画一整群图片检验的对照图,就请读者自行参阅。
最後,范例有提到说,因为前面的示范是一次放入10000张下去做predict,
如果今天有一张单张的28x28灰阶图片,
其实同样可以拿来做predict呦!
唯一的不同,就只是你要将这"一张"图片,扩展成"一组"图片,
而这一组里面就只有一张图片的格式。
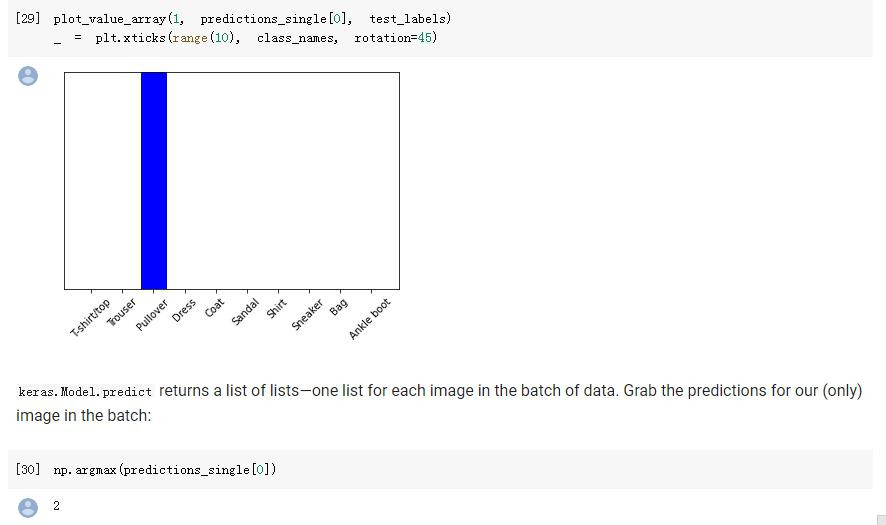
img = test_images[1] # 拿第二张
print(img.shape) # (28, 28)
img = (np.expand_dims(img,0)) # 扩展一个维度,让它变成"一组"
print(img.shape) # (1, 28, 28)
predictions_single = probability_model.predict(img) # 现在可以predict了
print(predictions_single)
[[5.1490115e-05 9.7672521e-14 9.9936408e-01 2.5379993e-12 1.0796214e-04
6.6310263e-10 4.7655238e-04 2.3014628e-11 2.8894394e-08 5.6684479e-12]]
最终结果顺利预测出该图片是Pullover(套头衫)。
虽然从上到下讲得相当长,
但其实只是很粗浅的示范了一下最基础的范例而已,
深度学习除了图像分类以外,
从图片到文字,再到声音,各种应用可以说是包山包海;
更不用说还有不同的模型建立方式与架构,
今天的介绍连冰山一角都称不上XD
若读者有更深入的兴趣的话,可能就要从更基本的机器学习部分出发了!
除此以外,若要自己进行深度学习的训练的话,
架构一个环境还是很有必要的,
就再请读者阅读一下其他大大们的教学呦!
那麽,我们就明天见罗!
<<: NestJs 延伸篇 - Gateway 与 前端接通
Rails 如何新增 Migration 档案
执行以下指令,就会在 db/migrate/ 目录下产生如 20110203070100_migra...
JavaScript 进阶笔记一 (变数)
一、变数 JavaScript 七种型态 Primitive type null undefine ...
D06 - Web Serial API 初体验
让我们透过 Web Serial API 连接 COM 吧! 首先来建立页面。 建立共用样式 准备撰...
#21-用Canvas做科技感的动态球!(+什麽时候该用CSS/SVG/Canvas?)
今天正式进入Canvas的世界了! 老样子先看成品: 今天来做点科技感的画面,橘色是滑鼠的游标,这个...
[Day 09] 简单的单元测试实作(三)
昨天我们已经测试了4这个数字, 但是除了4是闰年以外, 去年(2020年)应该也是闰年, 所以我们再...