Day 27. slate × Normalizing × normalize
前一篇我们介绍了 Slate Normalizing 里负责实作节点正规化以及让使用者自定义 constraints 的主要函式: create-editor 编辑器的 normalizeNode action 。还没阅读过的读者 传送门 在此~
今天我们紧接着要介绍 Normalizing 章节的另一个主要函式:interfaces/editor.ts 的 normalize method 。以及辅助函式: withoutNormalizing 、 isNormalizing 。
它们除了负责呼叫 normalizeNode 执行节点的正规化之外,还有处理整个 Normalizing 功能的效能优化以及实作我们在 Day24 里提到过的特性。
如果説 normalizeNode 是肉眼可见的表皮的话,那麽今天要介绍的 normalize method 以及它的小夥伴们就是支撑着整个 Normalizing 系统能够顺利运作的骨干啊!
那麽事不宜迟,让我们直接深入它的 code 一探究竟
normalize Method Content
我们可以把整个 method 拆成两个部分:
- 函式宣告与主要段落的预处理( Preprocess )
- 搭配
withoutNormalizing实作的主要段落( Main-Process )
Preprocess 的部分除了几个判断式负责辅助主要段落之外,还有一些额外的功能:
-
取得 Dirty-Path value
这部分很基本,就是另外宣告一个
getDirtyPathsfunction 提供给後续的功能取得DIRTY_PATHS的 value 而已:normalize( editor: Editor, options: { force?: boolean } = {} ): void { const getDirtyPaths = (editor: Editor) => { return DIRTY_PATHS.get(editor) || [] } // ... } -
处理
forthoptionforth参数代表的含意就是忽略计算出来的 Dirty-Path 结果,强行正规化编辑器内的所有节点。这里的做法也很简单:透过
Node.nodesmethod 取出编辑器当前存在的全部节点,并设定进DIRTY_PATHS里:normalize( editor: Editor, options: { force?: boolean } = {} ): void { // ... if (force) { const allPaths = Array.from(Node.nodes(editor), ([, p]) => p) DIRTY_PATHS.set(editor, allPaths) } // ... }
接着就轮到了主要段落的部分了,我们会依序介绍下方它所实现的功能们:
- Normalization Deferring (正规化延迟)
- Multi-pass Normalizing (正规化的 Infinite-loop )
- Empty Children Early Constraint Execution (第 1. constraint 的初始正规化)
Normalization Deferring
还记得在 前一篇 文章中提到过, Slate 正规化的运作方式是『一组完整的 FLUSHING 搭配一次 Normalize 』, withoutNormalize 就是实现这项功能最核心的 method ,所有会需要 Normalizing 功能的 Transform methods 里都一定会包进这个 method 里来实作,随便举个 insertNodes 当作范例:
insertNodes<T extends Node>(
editor: Editor,
// ... args
): void {
Editor.withoutNormalizing(editor, () => {
// ... Implementation
})
},
先一起来看一下它的 code 长啥样子:
/**
* Call a function, deferring normalization until after it completes.
*/
withoutNormalizing(editor: Editor, fn: () => void): void {
const value = Editor.isNormalizing(editor)
NORMALIZING.set(editor, false)
try {
fn()
} finally {
NORMALIZING.set(editor, value)
}
Editor.normalize(editor)
},
它首先储存了 isNormalizing method 回传的资料作为 NORMALIZING WeakMap 的初始值。
isNormalizing 其实单纯就是回传当前 editor 的 NORMALIZING value ,代表编辑器当前是否为『完成正规化』的状态,只是多加了一层三元判断:如果 value === undefined 则回传 true (因为 undefined 为初始值,编辑器的初始状态就是已经完成正规化的状态了)。
/**
* Check if the editor is currently normalizing after each operation.
*/
isNormalizing(editor: Editor): boolean {
const isNormalizing = NORMALIZING.get(editor)
return isNormalizing === undefined ? true : isNormalizing
},
接着将 NORMALIZING value 设为 false ,等执行完传入的 fn 以後再设 NORMALIZING 回先前存下来的初始值,并重新执行 normalize method 。
这麽做的用途是推延执行 normalize ,在 normalize 里有一行 statement 会去呼叫 isNormalizing 回传的 value ,如果回传 false 就直接跳过这次的 normalize
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
if (!Editor.isNormalizing(editor)) {
return
}
// ... Implementation
}
这使得一组 Transform 里头除了最初呼叫的那次包进 withoutNormalizing 的 fn method 会推迟执行 normalize method 之外,其余在过程中呼叫的 normalize 都会因为 isNormalizing 回传值为 false 因而直接跳过。
Multi-pass Normalizing
基本上整个 normalize method 是否结束完全取决於 DIRTY_PATHS 里头是否仍然有值,前面也有提到过 normalize method 的主要段落是搭配 withoutNormalizing ,放在传入的 fn 参数里去执行,所以就算完整地执行完 fn 的内容以後仍然会再执行一次 normalize method :
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
// Main-Process
Editor.withoutNormalizing(editor, () => {
// ...
});
},
withoutNormalizing(editor: Editor, fn: () => void): void {
const value = Editor.isNormalizing(editor)
NORMALIZING.set(editor, false)
try {
fn()
} finally {
NORMALIZING.set(editor, value)
}
Editor.normalize(editor)
},
它会不断地重复执行 normalize method ,直到从 getDirtyPath 取得的 length 为 0 时才真正结束。
所以我们不会在函式里看到将 Dirty-Paths 设为空阵列之类的初始化动作,它只会不断地重复执行 Normalizing 直到随着每次新的 Operation 呼叫,透过 apply method 重新计算出要设定进 DIRTY_PATHS 的 value 为空阵列(详请请回顾 上一篇 的内容)以後再透过预处理段落的辅助判断式来跳出 method :
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
if (getDirtyPaths(editor).length === 0) {
return
}
// Main-Process
Editor.withoutNormalizing(editor, () => {
// ...
});
},
在主要段落里也是透过一组 while loop 重复 pop 出 Dirty-Path 的 value 来重复呼叫 normalizeNode 。当然作者还是有设一个门槛不让整个正规化的次数无限上纲,也会先确定 pop 出来的路径所指向的节点确实存在於 document 中再呼叫 normalizeNode :
// Main-Process
Editor.withoutNormalizing(editor, () => {
// ...
const max = getDirtyPaths(editor).length * 42 // HACK: better way?
let m = 0
while (getDirtyPaths(editor).length !== 0) {
if (m > max) {
throw new Error(`
Could not completely normalize the editor after ${max} iterations! This is usually due to incorrect normalization logic that leaves a node in an invalid state.
`)
}
const dirtyPath = getDirtyPaths(editor).pop()!
// If the node doesn't exist in the tree, it does not need to be normalized.
if (Node.has(editor, dirtyPath)) {
const entry = Editor.node(editor, dirtyPath)
editor.normalizeNode(entry)
}
m++
}
});
原来如此!再综合上一小节的内容就能够确保『正规化会被推延到最後才执行那麽一次』了!
但我想问个问题:如果在呼叫normalizeNode执行正规化的过程中为了更新 document 而又另外呼叫了 Transform method 又会发生什麽事呢?这些 method 所推延的normalizemethod 会在最後成功执行吗?
答案是:不会!
还记得 normalize 将主要段落包进 withoutNormalizing 这件事吗?
这麽做除了会让 normalize method 被重复执行之外,也会同时将 NORMALIZING 设为 false ,因此在新的 Transform method 执行的过程中所呼叫的 normalize method ,包含 Transform 开头包进 withoutNormalizing 受到推延执行的那一组 normalize method 都会因为 NORMALIZING 被设为 false 而跳出:
// New "Transform" call during "normalizeNode"
withoutNormalizing(editor: Editor, fn: () => void): void {
const value = Editor.isNormalizing(editor) // set "value" to false
NORMALIZING.set(editor, false)
try {
fn()
} finally {
NORMALIZING.set(editor, value) // set "NORMALIZING" the value of "value" variable, which is still false
}
Editor.normalize(editor) // "normalize" won't execute successfully since "NORMALIZING: false"
}
因此在过程中执行新的 Transform 只会更新 document 以及 Dirty-Paths 的 value 而已,并不会再次出发执行另一组 Normalization ,直到完整执行完 Transform 的内容以後才会回到原本尚未执行完的 normalize method 里,以新的 DIRTY_PATHS value 继续执行正规化。
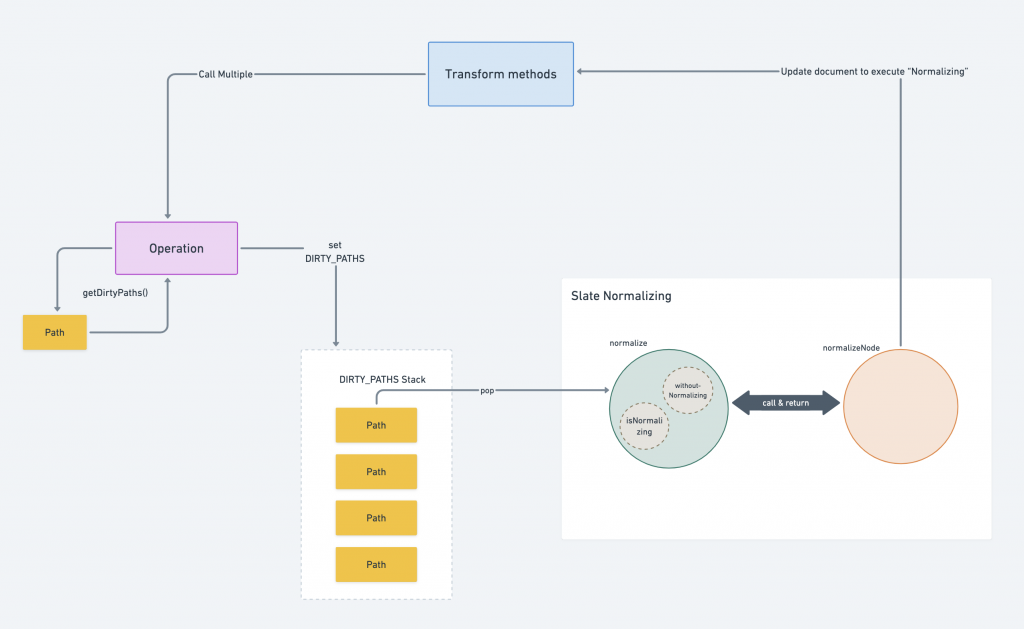
综合前两篇介绍的内容,我们可以将整个 Normalizing 与 Transform / Operation 的互动流程以下图呈现:
Empty Children Early Constraint Execution
这一段的 code 基本上与 normalizeNode 实作第 1. constraint 的内容大同小异。
就是取出所有的 Dirty-Paths ,确保这些路径指向的节点都确实存在於 document 里之後,将不存在子节点的 Element node 插入空的 Text void 节点:
Editor.withoutNormalizing(editor, () => {
/*
Fix dirty elements with no children.
editor.normalizeNode() does fix this, but some normalization fixes also require it to work.
Running an initial pass avoids the catch-22 race condition.
*/
for (const dirtyPath of getDirtyPaths(editor)) {
if (Node.has(editor, dirtyPath)) {
const [node, _] = Editor.node(editor, dirtyPath)
// Add a text child to elements with no children.
// This is safe to do in any order, by definition it can't cause other paths to change.
if (Element.isElement(node) && node.children.length === 0) {
const child = { text: '' }
Transforms.insertNodes(editor, child, {
at: dirtyPath.concat(0),
voids: true,
})
}
}
}
}
*里头的 comment 是说因为其他的正规化有些需要这项正规化事先完成後才能继续执行,为了防止 catch-22 race condition 的发生所以进行一次 initial 的 Normalizing ,但原谅笔者没有时间去找出实际会发生 race condition 的情境 ? 等未来有时间再补充这边的内容! *
最後我们放上一张延续 Day10 , Slate 完整的运作流程图:
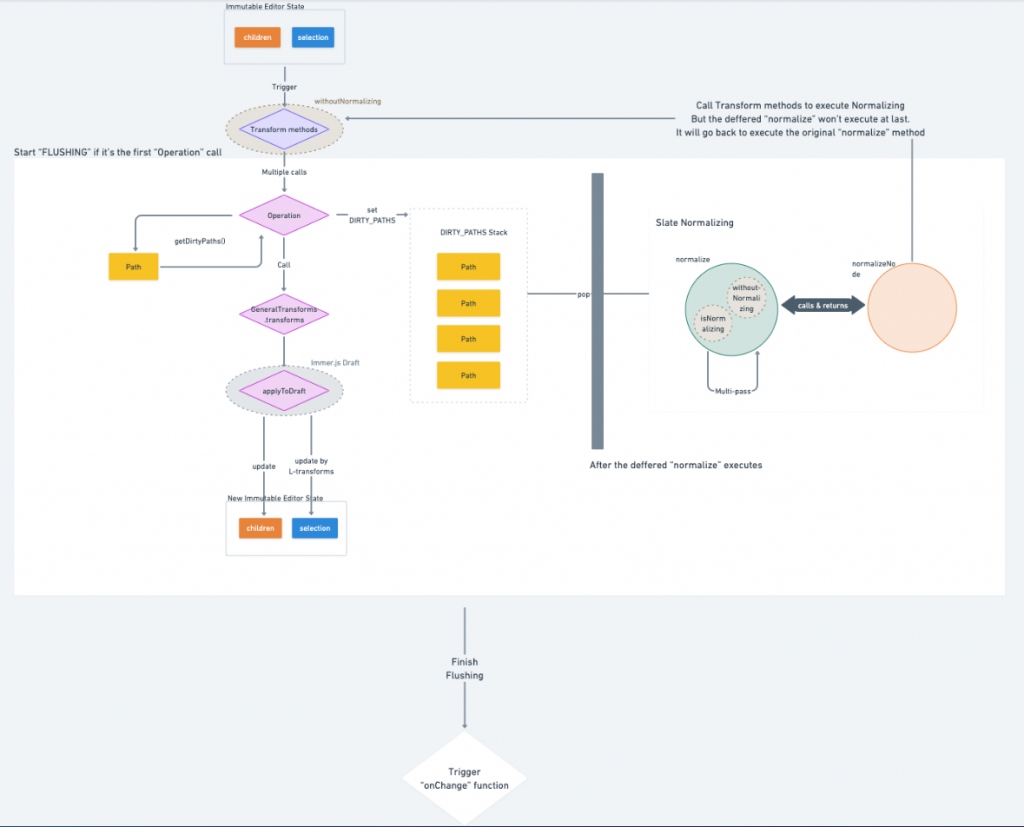
- 我们透过 Transform method 触发编辑器的更新,并复数次地呼叫 Operations
- 首次呼叫的 Operation 除了会执行
transform与normalize之外,也会将FLUSHING设为true,并将onChange的执行以 Promise 的 Micro-Task 包装起来 - Operation 透过
getDirtyPath取得并更新DIRTY_PATHSWeakMap variable - Operation 再透过
GeneralTransforms.transform搭配 Immer Draft State 呼叫applyToDraft更新children与selection - 执行 Transform 所推延的
normalizemethod 搭配normalizeNode执行 Dirty-Paths 的节点正规化,再次呼叫 Transform 来更新节点以满足 constraints 的规范并重跑一次相同的 Transform 流程,除了被推延的normalize不会正确地被执行以外 - 完成所有 synchronous 的编辑器更新後,执行 Micro-Task 的内容,将
FLUSHING设为false并触发onChangefunction ,结束一轮完整的编辑器更新!
到此为止我们终於完整介绍完了一整轮 Slate 编辑器的运作与更新流程了!整个正规化的章节也在今天告一个段落~
相信具备了完整知识的读者们未来在开发上或是处理类似的情境问题时都会更有解题的方向。
接下来我们准备要进入到整个系列文章的最後一个章节:『 Transform 』。
前面这麽常提到它,相信读者对它肯定是不陌生的,一切相关的介绍我们就留到明天吧~
[iT铁人赛Day1]JAVA下载与执行
JAVA是一个大家既熟悉又陌生的程序语言 稍微知道怎麽编写但会写错,也可能写还不知道怎麽储存,还有不...
JS语法学习Day5
学习目标 if判断&switch case 、取得html元素 if判断 if(条件)-&g...
第一次谈谈清单
在使用Android 手机时,满多机会因为画面的大小限制,在呈现较多资料的时候,需要一个介面可以渐次...
[Day 22]第二主餐-aws,始动
好的,经过了前两篇的中场休息後 今天我们要来把我们的code架到服务器上面 也就代表我们要进入第二主...
Day11-Kubernetes 那些事 - Ingress 篇(三)
前言 昨天的文章提到 Ingress 其实也可以用来做负载平衡,只是要利用其他种方式来实现,所以接下...