【27】遇到不平衡资料(Imbalanced Data) 时 使用 Undersampling 解决实验
不平衡资料集(Imbalanced Dataset) 指的是当你的资料集中,有某部分的 label 是极少数的状况,在这种状况下,若单纯只用准确度 accuracy 作为指标会有些偏颇,也会容易让模型偷懒,试想要是今天二分类问题,某样本出现的机率本身就很小,那我是不是每次都回答另一个样本就有99%准确度。
我们今天会使用 mnist 来实验遇到这种问题时,用 Undersampling 方式,降低其他多数样本来提升少数样本的准确度。
由於我们要故意降低 mnist 某些样本数,所以这次不使用 tfds 官方提供的数据,而是自己去下载原先的 mnist 来测试。
!wget http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz .
!wget http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz .
!wget http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz .
!wget http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz .
下载结束後,将档案解压出来。
import gzip
image_size=28
num_images = 60000
with gzip.open('train-labels-idx1-ubyte.gz') as bytestream:
bytestream.read(8)
buf = bytestream.read(1*num_images)
train_labels = np.frombuffer(buf, dtype=np.uint8).astype(np.int64)
with gzip.open('train-images-idx3-ubyte.gz') as bytestream:
bytestream.read(16)
buf = bytestream.read(image_size*image_size*num_images)
train_images = np.frombuffer(buf, dtype=np.uint8).astype(np.float32)
train_images = train_images.reshape(num_images, image_size, image_size, 1)
num_images = 10000
with gzip.open('t10k-labels-idx1-ubyte.gz') as bytestream:
bytestream.read(8)
buf = bytestream.read(1*num_images)
test_labels = np.frombuffer(buf, dtype=np.uint8).astype(np.int64)
with gzip.open('t10k-images-idx3-ubyte.gz') as bytestream:
bytestream.read(16)
buf = bytestream.read(image_size*image_size*num_images)
test_images = np.frombuffer(buf, dtype=np.uint8).astype(np.float32)
test_images = test_images.reshape(num_images, image_size, image_size, 1)
这次实验我选定数字 6, 8, 9 这三个样本当作不平衡的少数样本,原因是我觉得这三个数字形状上有某些部分相似。
我们先将资料集按照顺序排好。
idx = np.argsort(train_labels)
train_labels_sorted = train_labels[idx]
train_images_sorted = train_images[idx]
idx = np.argsort(test_labels)
test_labels_sorted = test_labels[idx]
test_images_sorted = test_images[idx]
查看各个样本数个是多少
unique, counts = np.unique(train_labels_sorted, return_counts=True)
dict(zip(unique, counts))
产出:
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 5918,
7: 6265,
8: 5851,
9: 5949}
接下来限定 6,8,9 的样本各取100笔。
idx_we_want = list(range(sum(counts[:6])+100)) + list(range(sum(counts[:7]) ,sum(counts[:8])+100)) + list(range(sum(counts[:9]) ,sum(counts[:9])+100))
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
取完之後再确认一下个个样本数:
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 100,
7: 6265,
8: 100,
9: 100}
以上是训练及的部分,再来,因为6,8,9的样本变少了,但是其他样本仍然多数,为了更有感觉模型在6,8,9这三种样本的准确度如何?我们在测试资料集中针对这三种样本单独抽出来,作为训练时的验证资料集。
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+counts[6])) + list(range(sum(counts[:8]),sum(counts[:8])+counts[8])) + list(range(sum(counts[:9]),sum(counts[:9])+counts[9]))
test_label_689 = test_labels_sorted[idx_we_want]
test_images_689 = test_images_sorted[idx_we_want]
测试集样本分布状况:
{6: 958, 8: 974, 9: 1009}
好的,清洁完资料後,我们开始来测试在这种不平衡的状况之下,训练模型会有什麽样的问题。
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_im,
epochs=EPOCHS,
validation_data=ds_test,
)
产出:
Epoch 24/30
loss: 0.0195 - sparse_categorical_accuracy: 0.9932 - val_loss: 0.8394 - val_sparse_categorical_accuracy: 0.8089
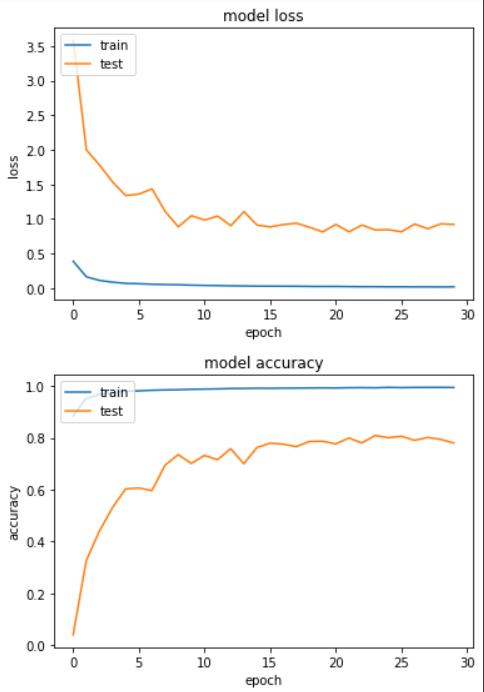
我们得到测试集的准确度在80%左右。
接下来,我们把训练集中的资料每个样本各取100笔,大幅度将6,8,9以外的样本减量到一样100笔来训练。
{0: 100,
1: 100,
2: 100,
3: 100,
4: 100,
5: 100,
6: 100,
7: 100,
8: 100,
9: 100}
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_im,
epochs=EPOCHS,
validation_data=ds_test,
)
产出:
Epoch 27/30
loss: 0.1910 - sparse_categorical_accuracy: 0.9370 - val_loss: 0.2793 - val_sparse_categorical_accuracy: 0.9300
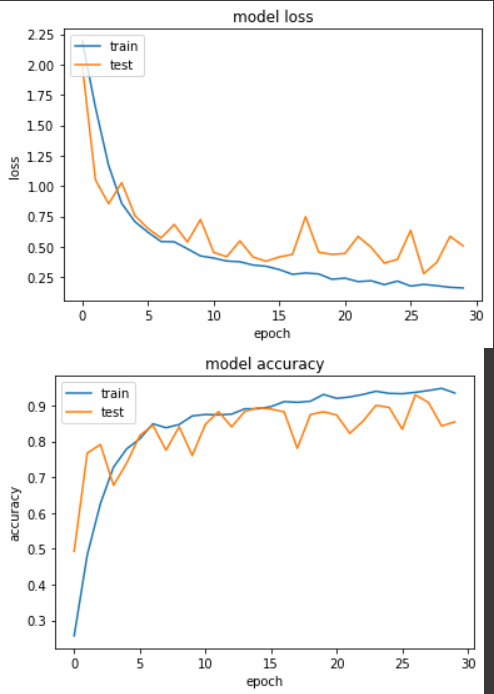
准确度提升成至93%,这次将 Undersampling 方法套用在 mnist 实验算是有效果的。
<<: 卡夫卡的藏书阁【Book27】- Kafka - KafkaJS Admin 4
JavaScript学习日记 : Day4 - 基本型别(二)
1. Object 相对於其他数据类型,object在JavaScript中用来储存键值对(Key-...
Day01_老太太的前言~落落长~XD"
重回职场之後,常常听到内稽跟外稽,一直搞不清楚到底是要鸡稽什麽XD"所以就自费去上课啦~ ...
Day 13 - 物品借用纪录系统 (3) 程序码解说
今天主要是来补足 Day11 和 Day12 简(ㄏㄨㄚˊ)约(ㄕㄨㄟˇ)的部分。 我们会讲两个东西...
更新网格交易机器人
改成使用targetCapital这个变数来控制总部位大小,不用每天开机器人的时候还要算加减多少钱。...
[Day-26] R语言 - 分群应用(五) 分群预测 - 资料分群 ( data clustering in R.Studio )
您的订阅是我制作影片的动力 订阅点这里~ 影片程序码(延续昨天) #步骤二: 资料分群,哪个演算法?...