爬虫怎麽爬 从零开始的爬虫自学 DAY27 python网路爬虫开爬8-储存问题解决
前言
各位早安,书接上回我们将程序码的规模扩大成多档案的规模,也发现了三个大问题,今天我们就要来解决它并顺便小小优化一下程序码
开爬-储存问题解决
昨天我发现的三个问题
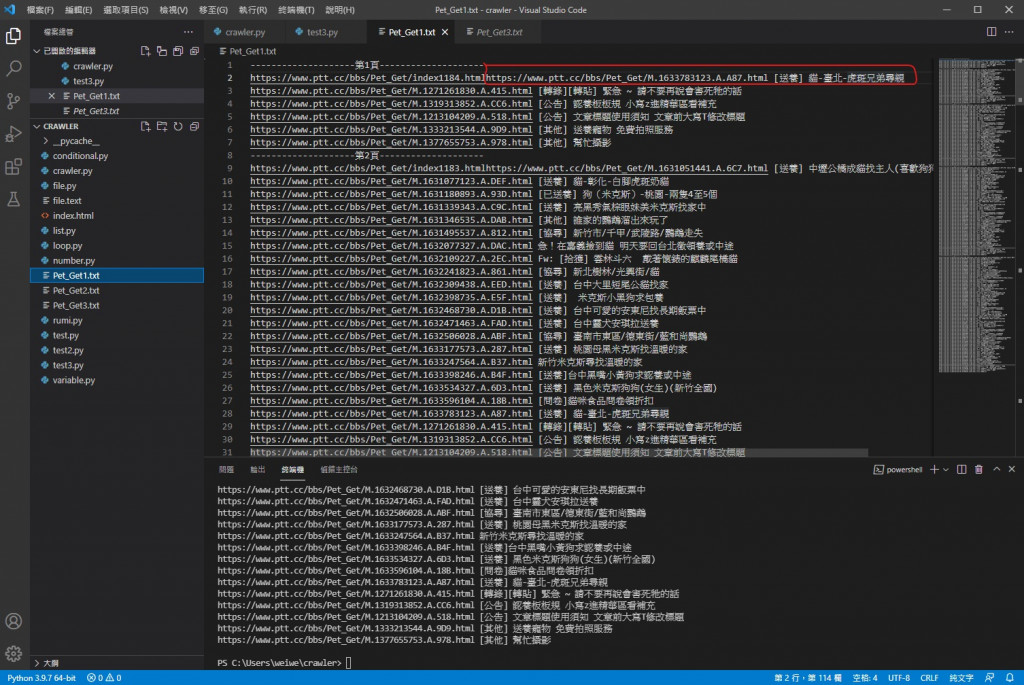
1.第一行文章的原网址没有换行 导致第一篇文章被往後挤不好看
2.文章原网址竟然是下一页的...
3.标题竟然越来越多???
今天我们要来一一解决它
1.第一行文章的原网址没有换行
这个问题不能简单在放入 infor 时加上 "\n" 就好
因为输出网址时多一个 "\n" 就会找不到网页
当然可以利用字串的新增删除来解决
但是那样就必须在写入时加进去又在读出来时删掉很麻烦
所以我想了更好的方法来解决 跟第二个问题一起处理
2.文章原网址是下一页的
这个问题就是我的程序结构有问题 本来以为很难处理
结果在想怎麽解决第一个问题时就顺便解决了
因为原本是在 getData(infor) 内就先抓到下一页连结并存入 infor 内一起丢出去
所以外面得到的文章原网址已经是下一页的了
我想到的方法是把文章的原网址跟其他资料分开写入
并且改变一下顺序在进去跑 getData(infor) 之前先写入文章原网址进去
之後再写入文章标题跟 URL
做法是把
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"页--------------------\n")
for inf in infor:
file.write(inf)
file.close()
改成
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
file.write("--------------------第"+str(i)+"页--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
把写入页数提到前面
再将文章的原网址跟其他资料分开写入并改到 getData(infor) 前写入
写入文章的原网址改在这里写入也就可以只在写入档案时加上 "\n" 而不用
然後第二层回圈才把剩下的部分也就是文章标题跟 URL 写入
这样就能解决了
改之前的档案内
改完之後
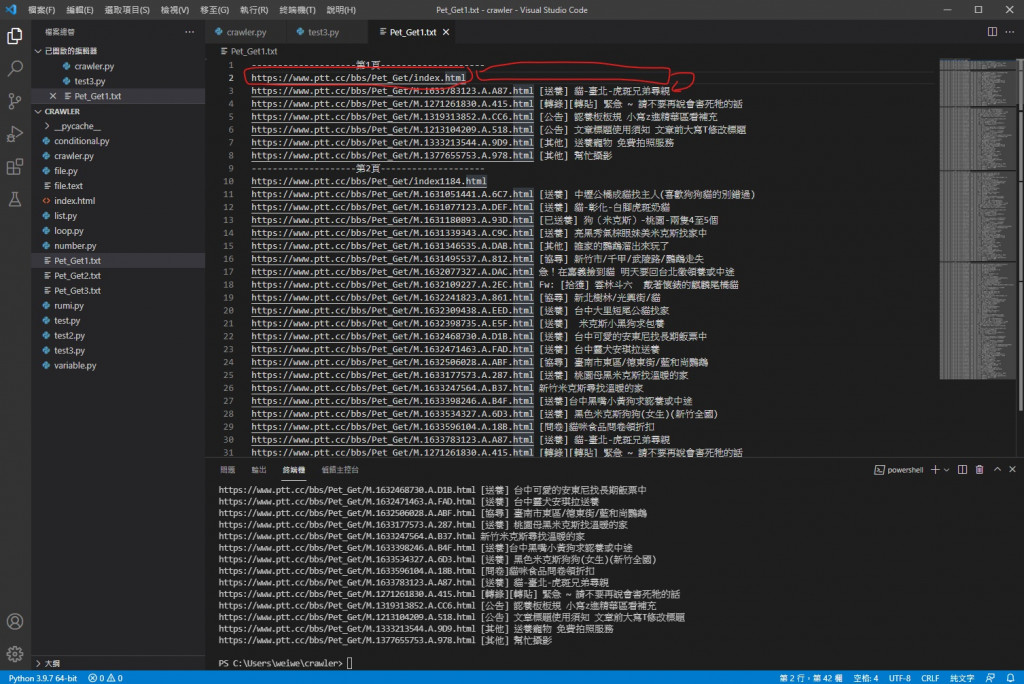
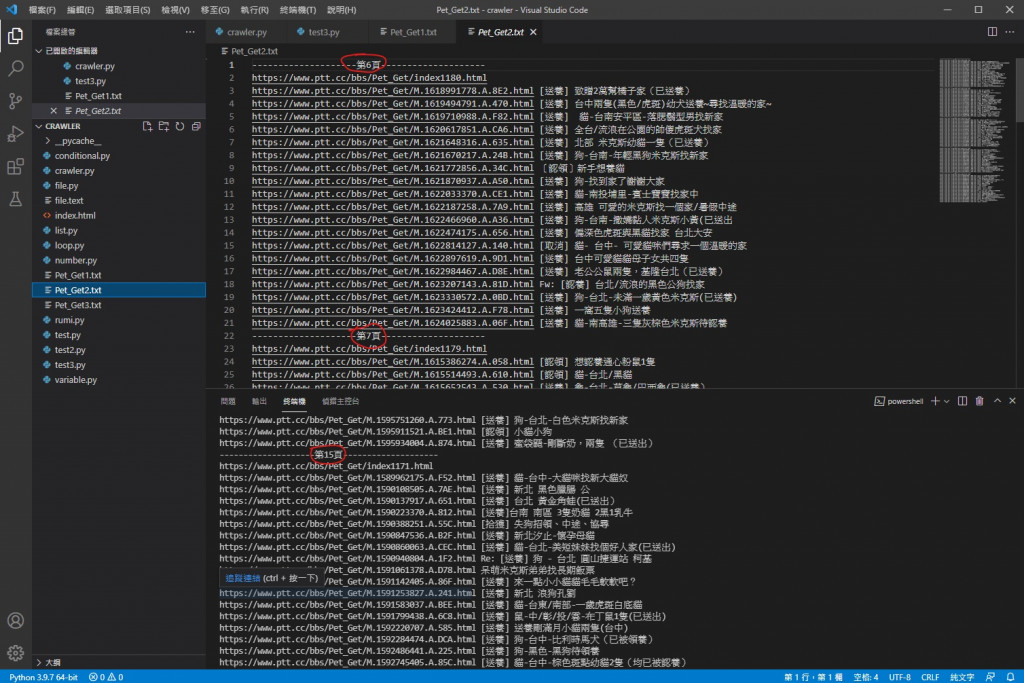
可以看到换行跟文章原网址错页的问题解决了
3.标题越来越多
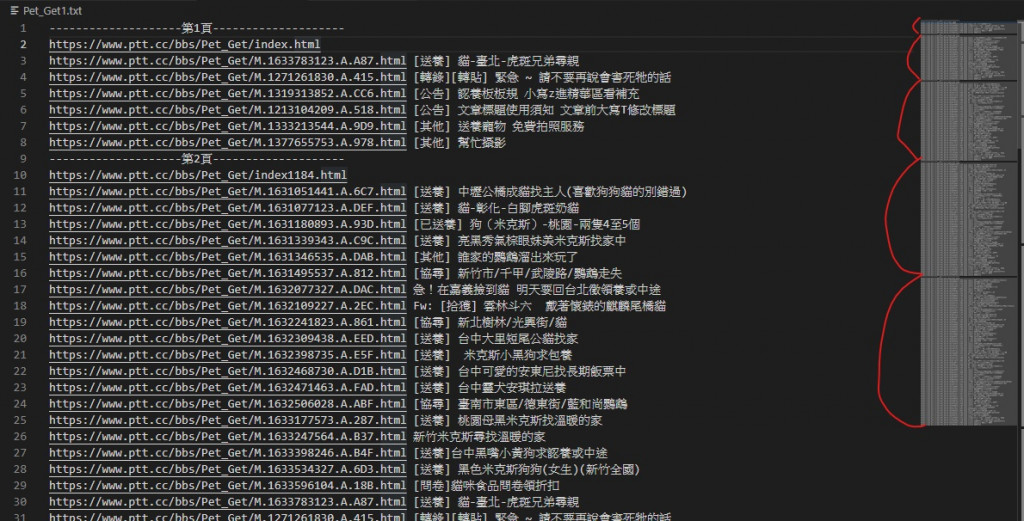
经过多次观察跟分析比对 我最终发现文章标题越来越多是因为我使用的 insert( )
我忘记它是新增元素不是取代了
所以导致 infor 内元素越来越多
所以只要在合适的位置清空它即可
正确的位置是在 request 用完上一页的 URL 之後清空它
简单的 infor = [""] 就可以处理了
改之前
改之後
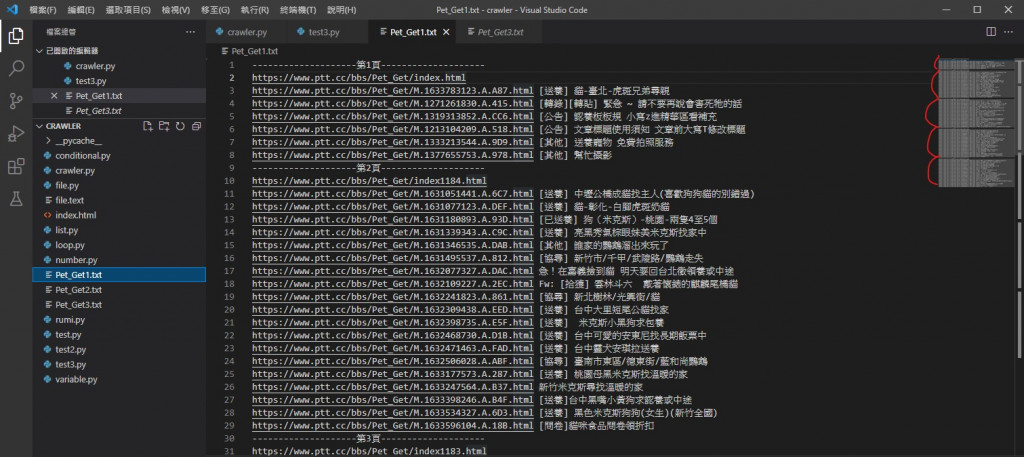
可以看到明显变少也不再递增而是差不多了
文章数量也跟网站上一致
最後是小小优化
把for回圈内建立变数让我们能更直观的设定档案数量跟每个档案放内几页
再加上能档案间叠加显示爬到第几页的小小功能
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
file.write("--------------------第"+str(i)+"页--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
for x in range(1,4,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
Number_of_files = 3
Number_of_pages = 5
for x in range(1,Number_of_files+1,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,Number_of_pages+1,1):
file.write("--------------------第"+str(Number_of_pages*(x-1)+i)+"页--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
for x in range(1,Number_of_files+1,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
可以看到不再都是1~5页了
赞赞
python 网路文字爬虫的最终程序码
import requests
import bs4
def getData(infor):
headers = {"cookie" : "over18=1"}
#建立headers用来放要附加的cookie
request = requests.get(infor[0],headers = headers)
#将网页资料利用requests套件GET下来并附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
infor = [""]
#将infor内清空
i = 1
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
infor.insert(i, "https://www.ptt.cc"+title.a["href"]+" "+title.a.text+"\n")
i = i+1
#利用for回圈把资料放进infor[1]开始的位置内并筛选掉已被删除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上页")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上页按钮内URL
infor[0] = newUrl
return infor
#将newUrl放进infor[0]再把infor传出去
infor = ["https://www.ptt.cc/bbs/Pet_Get/index.html"]
#抓PTT领养版的网页原始码
Number_of_files = 3
Number_of_pages = 5
#设变数方便设定档案数跟页数
for x in range(1,Number_of_files+1,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,Number_of_pages+1,1):
file.write("--------------------第"+str(Number_of_pages*(x-1)+i)+"页--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
#写入资料
for x in range(1,Number_of_files+1,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
#读取档案中资料并印出
到今天为止我们成功完成我们的 python 网路文字爬虫了 耶~~
持续改进到今天它已经是一只功能相对完整的程序了
希望大家可以利用它在PTT上找到更多有用的资讯 也能遇见合适的浪浪给牠们一个温暖的家
当然也能用在其他任何需要的地方 那实作皆属个人行为 笔者不付任何法律责任
希望大家能把爬虫用在好的地方让生活更方便
明天我们要来搞新的爬虫 敬请期待
早安闲聊区
你知道吗?
罗马帝国可能是因为在供水管线大量使用铅而导致铅中毒而衰败的喔
每日二选一
如果必须选你会吃花生酱味道的大便还是大便味道的花生酱呢
>>: [Day 28 - 小试身手] Todolist with React (3)
qclipboard 用法
在main中初始化,传给处理模块: ClipBoardManagement clipboardMan...
Day 19 - Unreal Webcam Fun [更新]
前言 JS 30 是由加拿大的全端工程师 Wes Bos 免费提供的 JavaScript 简单应用...
Day-18 再次点亮那传递无尽创意的紫色魔方 GameCube
Nintendo GameCube、以下简称 NGC。这部主机在上市前、市场上其实是一片骂声的。缤纷...
Day20 Android - Retrofit(Get)
今天主要要来提提Retrofit,Retrofit主要透过interface连线串接以取得资料,像是...
[Vue] 判断图片是否存在
在开发Vue专案时,时常会使用binding的技巧,用以动态变更参数的值, 如下 <div c...