[Day27]程序菜鸟自学C++资料结构演算法 – 堆积排序法(Heap sort)
前言:在第16、17天的时候有介绍到堆积,今天要利用堆积的特性来实现排序法,忘记或不知道堆积是甚麽的人可以回去这两篇看看。
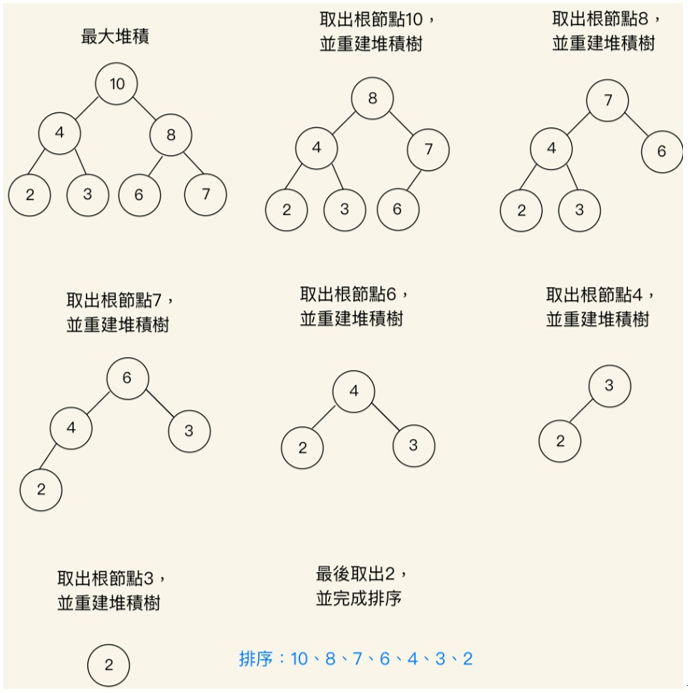
堆积排序:
快速帮大家复习一下,堆积是一颗完整二元树,且堆积的父节点都比其左右子节点的资料大或相等,而堆积排序就是一种树状结构的排序法,最主要的工作就是建立「堆积」。
建立好堆积後就可以开始执行堆积排序,操作步骤可以大致分成三个阶段
- 从二元树调整节点或建立成堆积。
- 在输出堆积的根节点後,将剩下的二元树节点重建成堆积。
- 重复操作直到所有节点输出。
执行效率分析:堆积排序法的执行效率是当排序的资料个数为n时,堆积排序的主回圈一共执行n-1次,每次执行的效率为树高(即Log n),可以得知时间复杂度为O(n Log n)。
堆积排序法不需要额外的记忆体空间,不过这种排序法并不稳定,因为在调节根节点时,可能会交换到相同件值得元素。
堆积排序实作:这次的排序会实作在之前堆积的档案,因为有很多已经写好的函示会使用到,大家可以先把堆积实作的档案找出来。
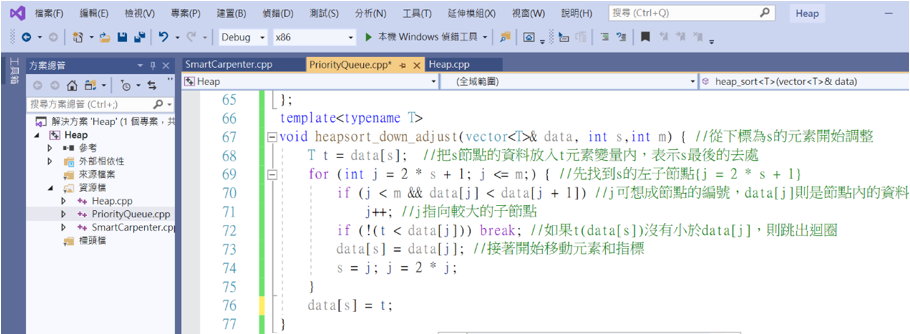
首先要来修改之前向下调整的函式。
如果不想改原来的程序,可以先复制下来然後照着上面改,但是函式名称要修改,不然程序会不知道要执行哪个向下调整的方法。
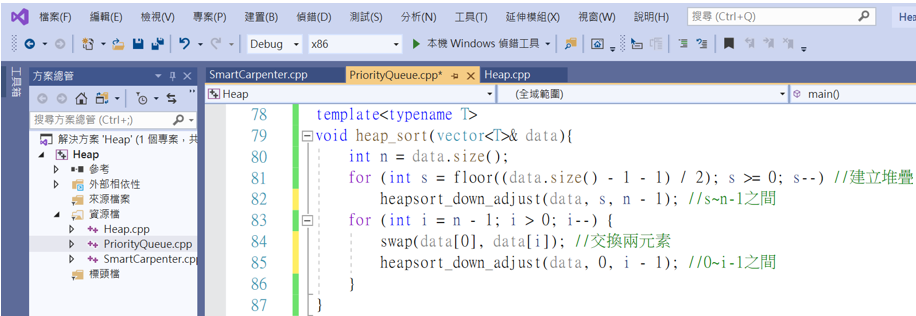
接着是堆积排序的主要执行方法。
最後来看看执行结果。
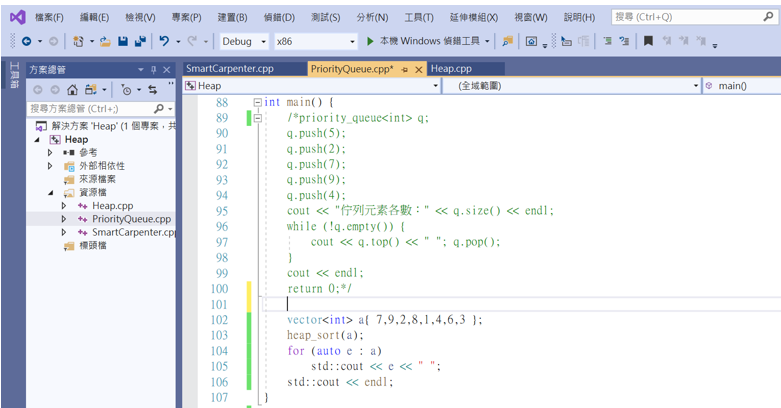
这样堆积排序就完成了。
本日小结:堆积排序法的执行速度在各排序法中也是佼佼者,但是因为堆积需要使用到树状结构,不仅架构时比较麻烦,如果之後有出错或需要维护的话也会稍嫌困难,在撰写程序时,这些问题都是必须要纳入考量的。虽然这麽说好像很复杂似的,但是简单的堆积排序其实只要使用一般的阵列就可以时做出来,就如同今天的实作一样,下一篇要来介绍基数排序法(^・ω・^ )
template<typename T>
void heapsort_down_adjust(vector<T>& data, int s,int m) { //从下标为s的元素开始调整
T t = data[s]; //把s节点的资料放入t元素变量内,表示s最後的去处
for (int j = 2 * s + 1; j <= m;) { //先找到s的左子节点{j = 2 * s + 1}
if (j < m && data[j] < data[j + 1]) //j可想成节点的编号,data[j]则是节点内的资料
j++; //j指向较大的子节点
if (!(t < data[j])) break; //如果t(data[s])没有小於data[j],则跳出回圈
data[s] = data[j]; //接着开始移动元素和指标
s = j; j = 2 * j;
}
data[s] = t;
}
template<typename T>
void heap_sort(vector<T>& data){
int n = data.size();
for (int s = floor((data.size() - 1 - 1) / 2); s >= 0; s--) //建立堆叠
heapsort_down_adjust(data, s, n - 1); //s~n-1之间
for (int i = n - 1; i > 0; i--) {
swap(data[0], data[i]); //交换两元素
heapsort_down_adjust(data, 0, i - 1); //0~i-1之间
}
}
<<: Day 26 Wireless Attacks - 无线攻击 (aircrack-ng)
>>: Day26 X Memory Management In JavaScript
模型的内容08 test()
这个章节,我们将谈到 test()的部分。 进入主题之前,我们要注意的是,test_loader是固...
Swift 新手-ios 应用软件开发资料与云端储存篇(ㄧ)
将 Swift 连上 Firebase 资料库,从 cocoapods 安装 Firebas、App...
【从零开始的 C 语言笔记】第二十六篇-变数的生命周期(1)
上一篇我们介绍了副函式的概念,一般来说我们会把特别处理某些资料的部分,另外拉出一个副函式来处理,除...
在 Clear Linux 上安装 VirtualBox 6.1.26
前言 我是先把 Kernel 等相关套件,以及 VirtualBox 安装起来之後,再从错误讯息去尝...
Vaadin login with Facebook - day28
目的 使用 Facebook 登入 本日重点 : 本篇使用 Facebook Graph API 登...