语义检索 Semantic Search NLP ( BM25 +wordcloud+LSA summary )
本文将完成:
- 语义检索 从 IMDB影评档(100则)-->
- 从文字栏位'IMDB_plot',找出BM25分数最高者。-->
- 以worldcloud图示之 Top 10 words -->
- Summarize LSA method 摘要三句话
dataset来源:Kaggle movies.csv
程序码 参考来源
pypi官网 rank-BM25 安装+范例
BM25 algorithm是一种优化的TF/IDF检索方式,运算公式请自行参阅 wikipaedia说明 我们今天只实作 【程序码在 GitHub】
import套件
from rank_bm25 import BM25Okapi
import pandas as pd
import os
#--- NLP summarize lib
import sumy
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer as sumyToken
from sumy.summarizers.lsa import LsaSummarizer
#--- wordcloud
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from PIL import Image
载入csv 取栏位 “title” “imdb_plot”

# load from csv
df = pd.read_csv('movies.csv',dtype=object)
movies = df[['title','imdb_plot']]
mtitle = movies['title'].astype(str)
mimdb = movies['imdb_plot'].astype(str)
开始使用BM25
#--- tokenize
tokenized_corpus = [doc.split(" ") for doc in mimdb]
#--- initiate
bm = BM25Okapi(tokenized_corpus)
# query --> 要查询的 字词
query = "music "
tokenized_query = query.split(" ")
# 计算 BM25 score (log)
scores = bm.get_scores(tokenized_query)
idx = scores.argmax()
scores.argmax() 代表'分数最大'的元素之index ,我们可以使用此index来找出 mtitle[idx] mimdb[idx]文字内容。我们先使用keyword "music"查询看看:
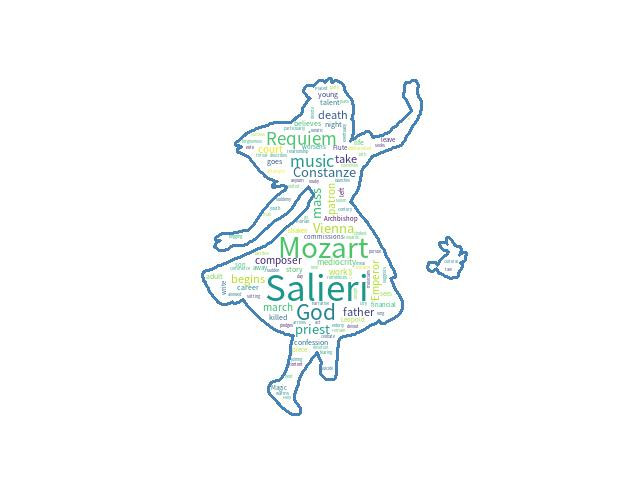
最佳配对(BM/best match)是第30则,分数是3.11332... ,电影title Amadeus,影评前60个字是The story begins...
idx: 30
3.1133320601273993
Amadeus
The story begins in 1823 as the elderly Salieri attempts sui
如果把每一则的score都印出来看看...
[0. 1.45850928 0. 0. 0. 0.
0. 1.9614662 0. 0. 0. 0.
0. 0. 0. 0. 0. 2.7574558
1.81637605 0. 0. 1.6851387 0. 0.
0. 0. 0. 0. 0. 1.94504518
3.11333206 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 1.9093863
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. ....略
文字云wordcloud
'有图有真象',Make wordcloud 把该则影评的关键字show出来。(使用遮罩alice_mask.png)
cloud.words_ 是一个已经完成排序的 dict,列出前面10个就是了...
-->图片存档
#--- make wordcloud
def mkCloud(txt):
mask = np.array(Image.open('alice_mask.png'))
font = 'SourceHanSansTW-Regular.otf'
cloud = WordCloud(background_color='white',mask=mask,font_path=font,
contour_width=3, contour_color='steelblue').generate(txt)
plt.imshow(cloud)
plt.axis("off")
plt.show()
# keywords 已经完成排序的 一个 dict
keywords = cloud.words_
mostly = list(keywords.keys())
print('Top10 keywords: ',mostly[:10])
mostkeys = str(mostly[:10])
pmt = f'Top10 keywords in the text\n{mostkeys}'
print(pmt)
# 将wordcloud 存档
destFile = 'bmFig.jpg'
cloud.to_file(destFile)
# show image on screen
if os.path.exists(destFile):
img = Image.open(destFile, 'r')
img.show()
top 10 words
Top10 keywords: ['Salieri', 'Mozart', 'God', 'Requiem', 'music', 'priest', 'Vienna', 'Constanze', 'mass', 'begins']
Summarize 三句话,摘要说一下内容
#--- make summary ---
def mkSummText(content):
# Initializing the parser
my_parser = PlaintextParser.from_string(content, sumyToken('english'))
# Creating a summary of 3 sentences
lsa_summarizer = LsaSummarizer()
Extract = lsa_summarizer(my_parser.document,sentences_count=3)
conclusion = []
for sentence in Extract:
#print(sentence)
conclusion.append(str(sentence))
return conclusion
结果,三句话:
>> He believes that God, through Mozart's genius, is cruelly laughing at Salieri's own musical mediocrity.
>> When Salieri learns of Mozart's financial straits, he sees his chance to avenge ...略
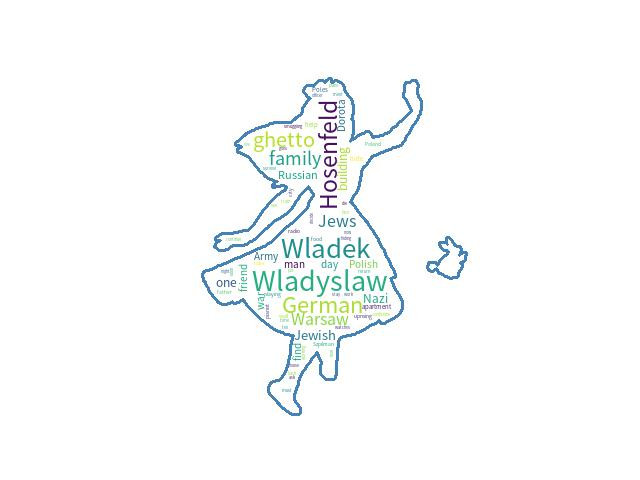
另外改用keyword: 'musician'检索,结果:
idx: 58
4.300402699706742
The Pianist
"The Pianist" begins in Warsaw, Poland in September, 1939, ...
代码+csv+ alice_mask.png 在GitHub
>>: 予焦啦!结论与展望(一):Hoddarla 专案的过去、现在与未来
Day 18 ( 中级 ) 阵列点灯 ( 显示图形 )
阵列点灯 ( 显示图形 ) 教学原文参考:阵列点灯 ( 显示图形 ) 这篇文章会介绍如何使用「阵列」...
Day 15 - UML x Interface — Notifier
UML Notifier 的 UML 主要是根据 Ant Design 的设计画出来的,而在 Ma...
#13-消失吧!Navbar!让你的网页更多空间 (JS)
好的Nav bar的动态可以让网站不那麽呆板, 其实实作的技术也不难,就是侦测页面的滚动 向下滑的时...
ML专案的特徵工程为什麽存在?包含哪些层面?怎麽练手感?
在讨论MLOps的过程当中,许多客户会针对他们有兴趣的事情提出不同的问题,像是:模型监测、安全性、常...
Windows 10 KB5006670 更新导致电脑连接已安装的网络印表机,显示“0x00000709错误”
这几天公司连接网路印表机的电脑报出"0x00000709"无法使用错误 目前爬文...