口罩脸孔资料集的标注、资料前处理与资料扩增
我们已将资料集上传到 nilvana 的 Vision Studio 中, 也知道标注格式的种类与基本内容, 这篇我们来执行标注、资料前处理与资料扩增.
资料标注
标注方式可分为机器标注与人工标注,Vision Studio 的机器标注提供半自动标注及全自动标注两种
- 全自动标注: 载入内建或者训练出来的模型, 就由系统完成所有的标注工作, 适用情境是对该模型的准确度有信心时, 例如在相同情境下已使用过相同模型执行标注且标注的结果符合预期. 全自动标注会直接进行标注作业, 就像亲自手工标注一样.
- 半自动标注: 载入内建或者训练出来的模型, 系统会将标注结果以等待确认的方式呈现(以虚线呈现), 然後再由人工方式确认系统所标注的结果(确认後的结果以实线呈现),只需要检查并点击进行微调,即可完成标注工作。 适用情境是当资料集或演算法是新采用的情况, 那先由系统做初步的标注再由人工方式确认可以节省时间.
- 人工标注:不经由机器协助进行标注,以人工方式进行标注,这个方法的标注结果最为准确,但也相对需要耗费较多人力
- Nilvana 的 Vision Studio 支援多人即时标注,可直接於系统中进行多人协作,省略资料传递与合并的流程,管理者能即时掌控所有标注状况,也能即时与协作者进行讨论,更便利於确认标注结果,藉此提升标注品质
接下来回到Nilvana的Dataset页面, 请点击下图的Machine Annotation按键
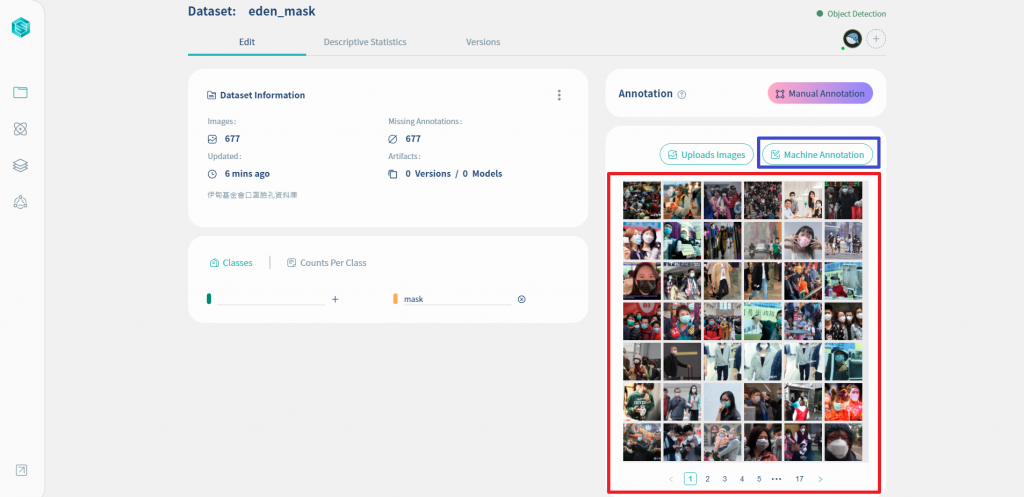
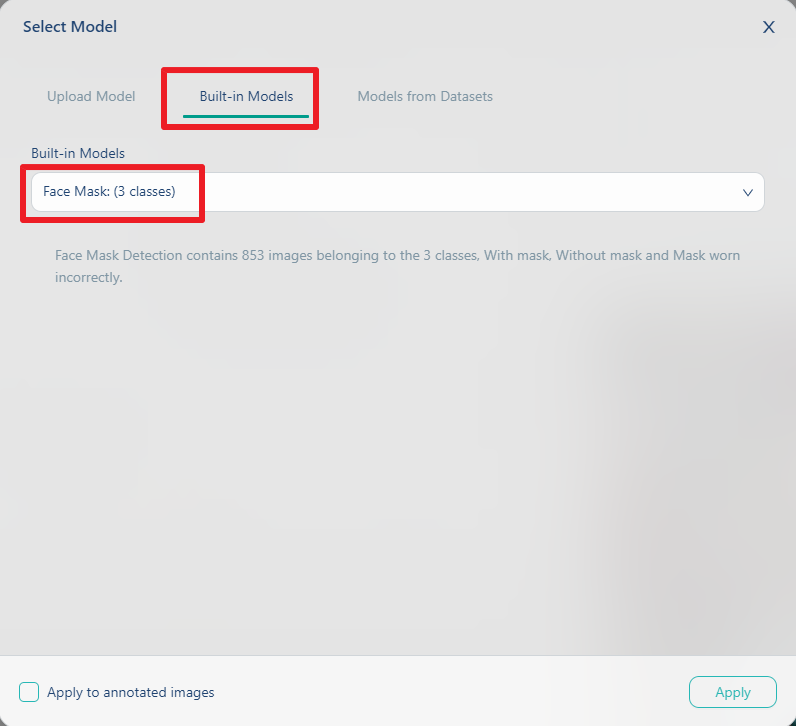
在下图中, 我们择选中间的tabBuilt-in Models, 表示我们要使用内建模型. 内建模型大部份是基於开放资料集,并经过验证与调教训练而成,包含:
- 口罩侦测模型:提供口罩的穿戴验证,包含
有戴口罩、没戴口罩及口罩穿戴不正确三种类别。 - COCO 80 模型:透过 COCO (Common Object in Context) 资料集训练而成,涵盖较常使用的 80 种物件类别,例如 car, dog, cat, bus, bicycle, motorcycle 等。
在这个步骤中, 我们选择Face Mask(口罩侦测模型), 再点击apply键
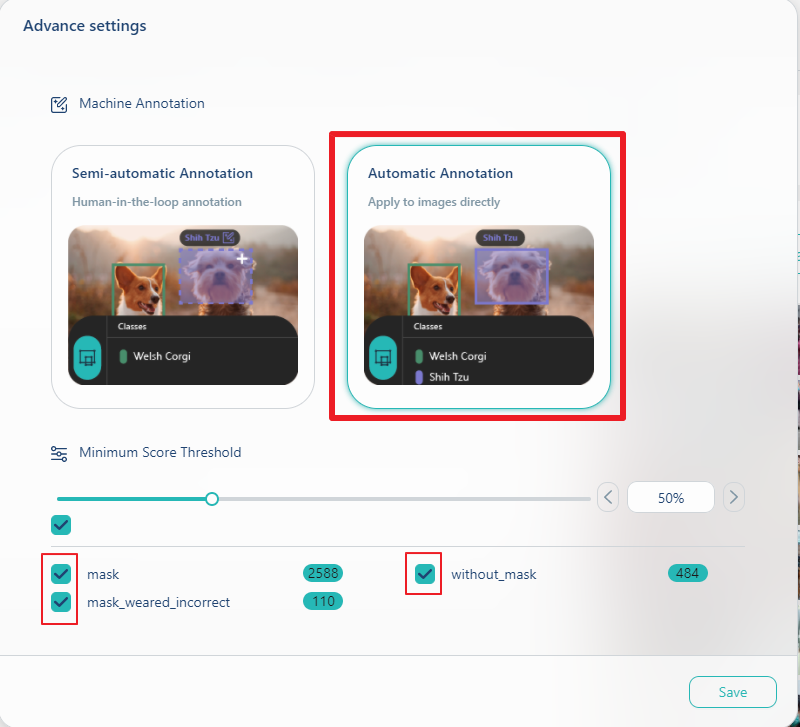
接着要选择执行全自动标注还是半自动标注, 这里我们选全自动标注Automatic Annotation
针对Minimum Score Threshlod, 可以左右拉动最小机率门槛值做设定, 数值越大则误判机会越小, 但可能会漏掉一些物件.
然後进行确认要标注的标签, 在我们的范例中, 被标注为有戴好口罩的数量有2588, 没有正确戴口罩的数量有110, 而没有戴口罩的数量有484, 我们把这三个checkbox都勾起来.
然後也再点击save键
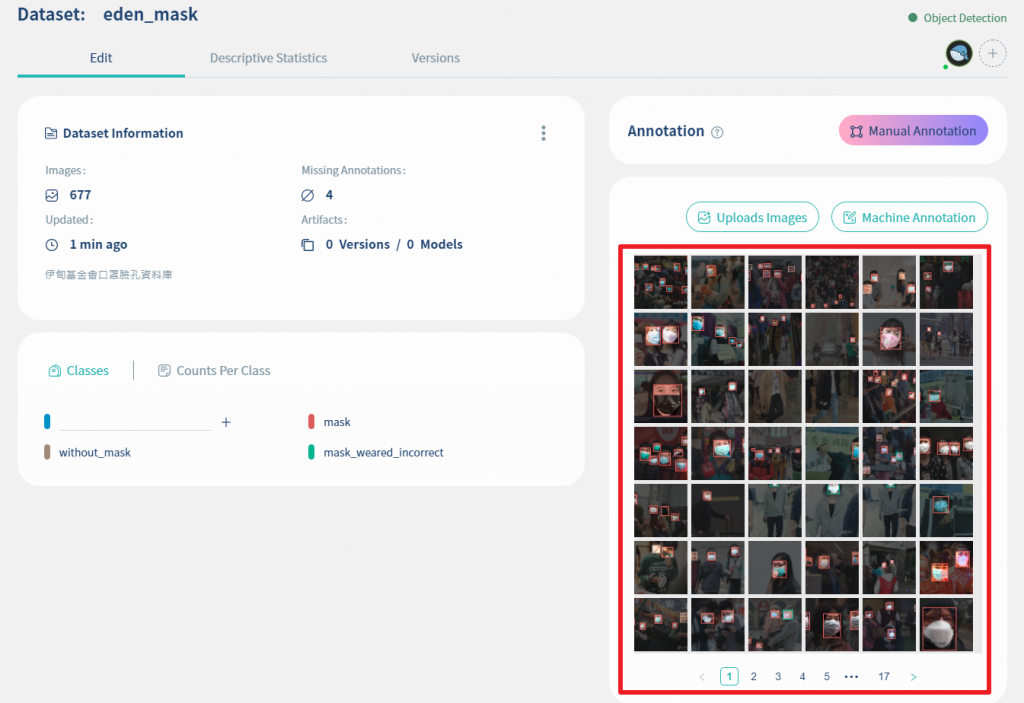
然後即可看到自动标注後的结果, 如下图红框处
建立版本
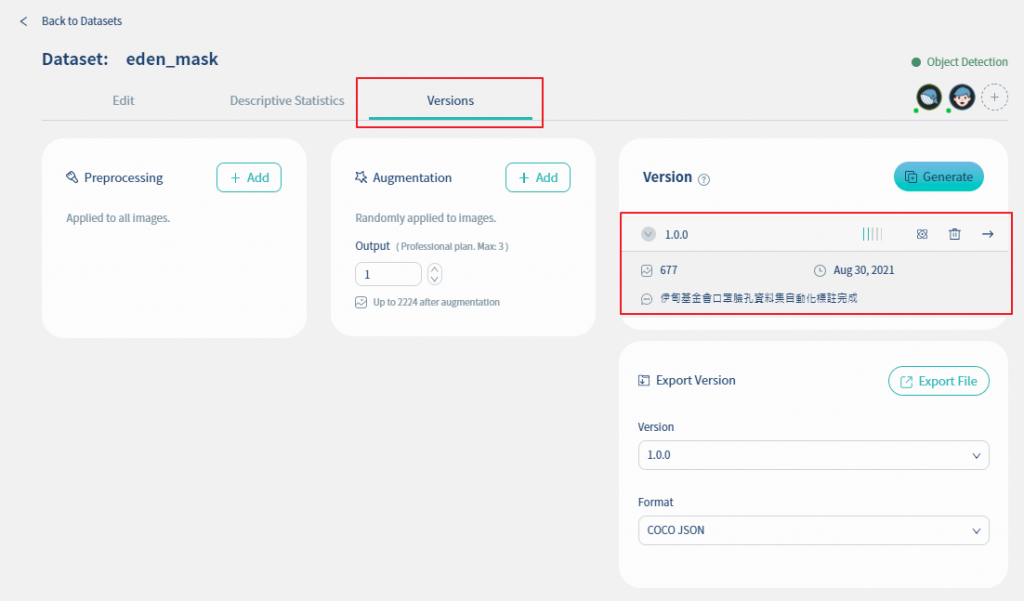
完成资枓标注之後, 以目前的图档建立一个新的版本, 版本名称为1.0.0, 图档数量为677张, 如下图所示. 但目前的图档版本品质为二格, 品质属於尚可(fair), 因此接下来我们来(1)加入更多图档, (2)使用资料前处理与资料扩增技术增加资料集的品质
增加图档资料
为了增加图档品质, 其中一种方式是增加图档, 上传图档的方式请参考Day24的内容.
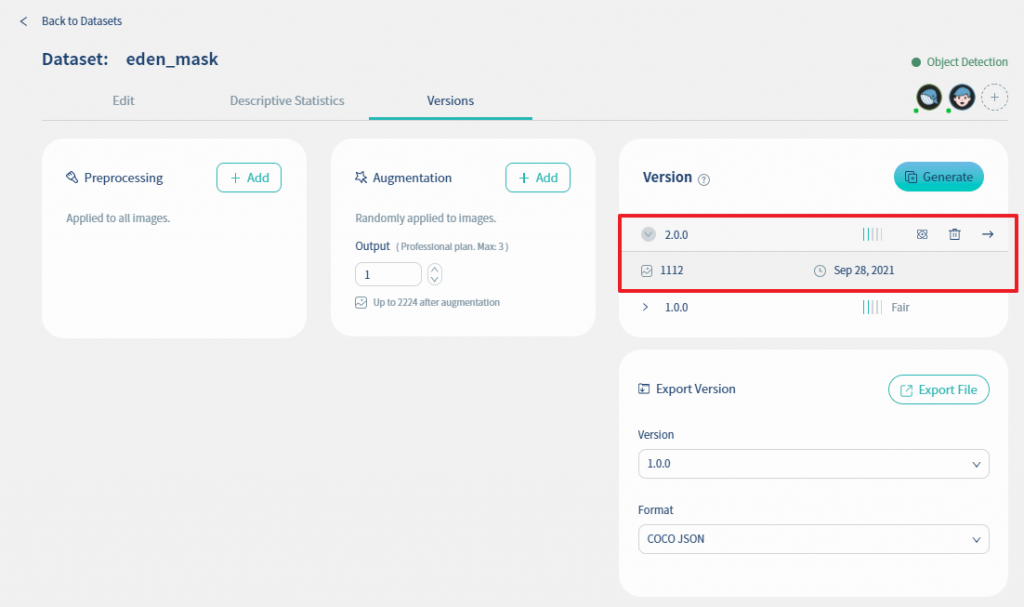
增加图档後, 图档的数量增加为1112张, 并且将版本命名为2.0.0, 如下图所示.
但增加了图档数量之後并没有增加图档品质, 图档品质仍属於尚可(fair).
资料前处理与资料扩增
前述增加图档数量之後并没有增加图档品质, 因此接下来要执行资料前处理与资料扩增, 预期资料品质会提高.
- 资料前处理
一般来说,模型学习时的图片尺寸大小与推论时的尺寸一致,会有较好的辨识结果。但搜集资料的过程中,往往会因为撷取影像的设备、环境等不同原因,导致蒐集到的每张图片大小、长宽比例都不一样。而且适当的调整图片尺寸,也有助於减少训练的时间以及提升推论的速度。
Nilvana Vision Studio 提供 Resize 与 Modify Classes 等项目,在进行图片尺寸及类别格式统一更便利,能为模型训练及模型推论带来许多帮助 - 资料扩增
当拥有的资料有限时,可以透过资料扩增的方式增加资料的多样性及数量,较常见的方式是将资料进行左右翻转、色调调整、角度调整等等,举例来说,图片中的鸟做了左右翻转或色调调整後,依旧还是图片中的鸟,但对於演算法来说,调整过後的资料都是新的资料,等於是提供了更多资料让机器进行学习,可以为训练模型时带来帮助,增加训练出来的模型可用性。顺带一提,进行资料扩增时,较少使用上下翻转的方式,因为上下颠倒的影像於现实世界中较少出现,因此这种方法对於训练模型时较无帮助
资料前处理与资料扩增是OpenCV的专长
资料前处理
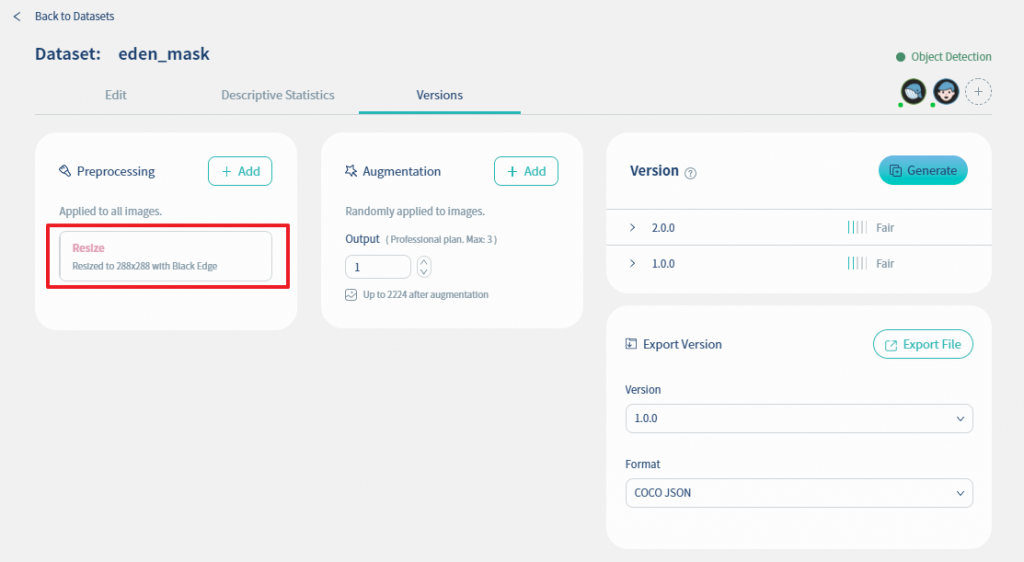
接下来我们使用Nilvana来做resize. 首先在下图中选择Versions页签, 然後点击Preprocessing的Add键
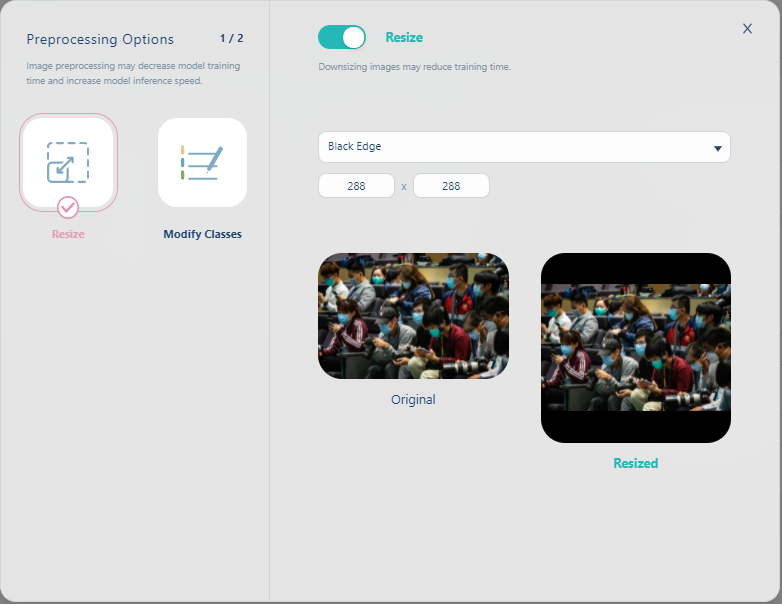
然後在下图选择Resize, 并且在右侧的下拉式选单选择Black Edge, 表示我们要影像档固定为同一个size(288x288), 如果有多出来的部份以黑底填满. 最後再将Resize切换为enabled.
这里将资料的尺寸及类别格式统一的好处是可以帮助你减少模型训练所要花费的时间.
设定好的画面如下图所示:
资料扩增
接下来我们要做资料扩增, 请点击下图的Add键
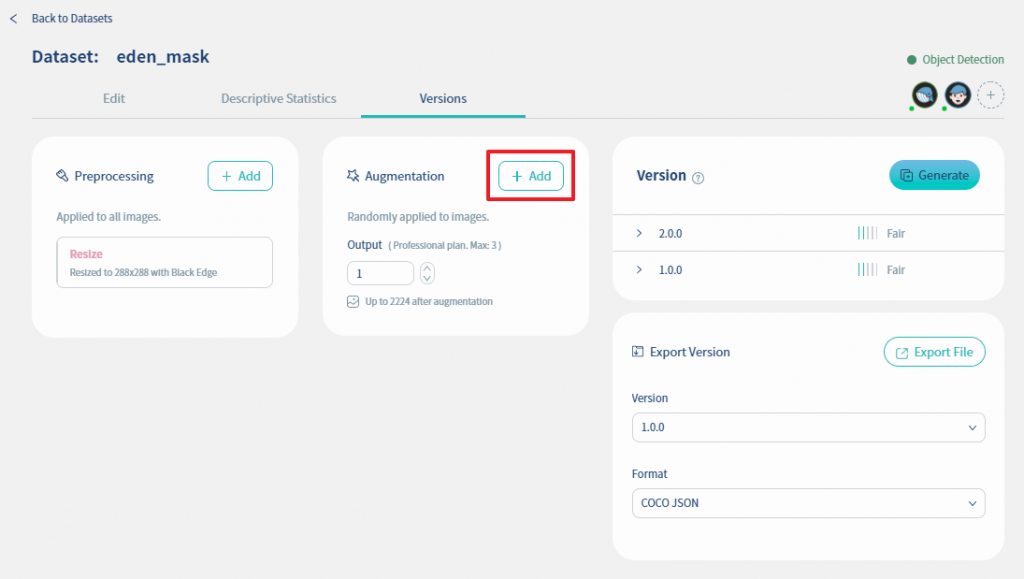
Nilvana提供多种方式, 透过小幅度的改动资料, 可以为你优质的资料增加多样性以及降低过度拟合的现象, 提高资料集整体品质. Nilvana提供以下演算法辅助你增强图像,包含:Noise, Saturation, Brightness, Hue, Flip, Exposure, Shear, Rotation, Blur, Grayscale 等。
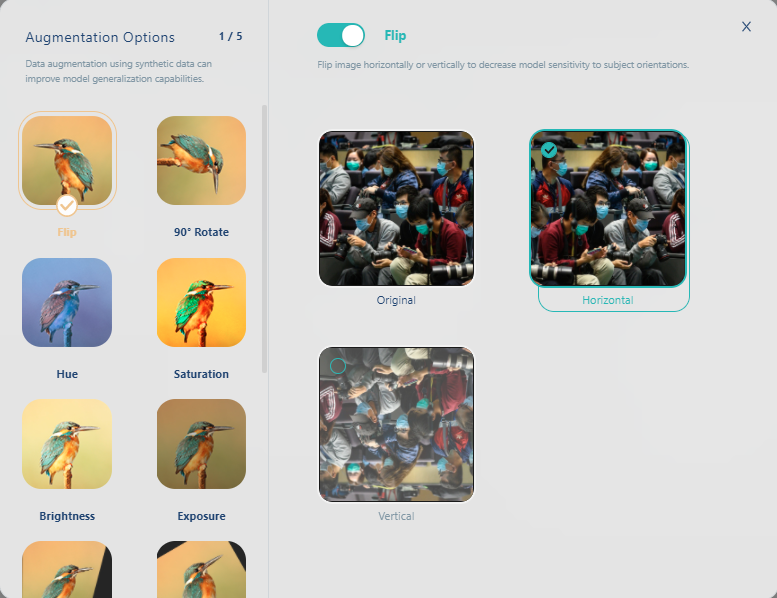
在我们的范例中, 选择左右翻转(Flip)
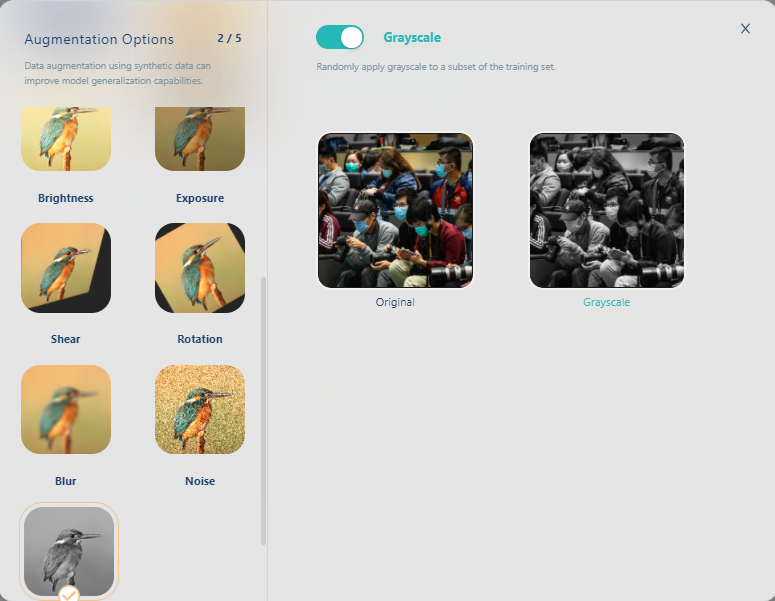
再选灰阶(Grayscale)
再选旋转(Rotation)
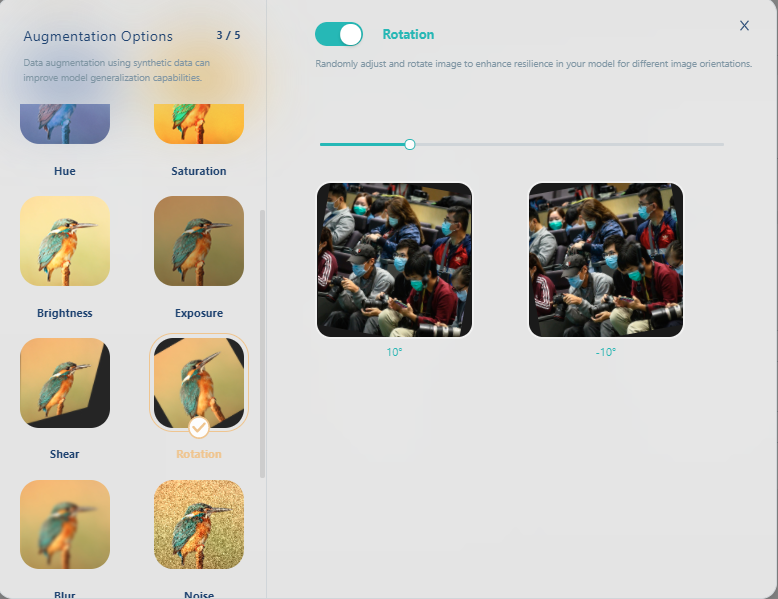
再改变色调(Hue)
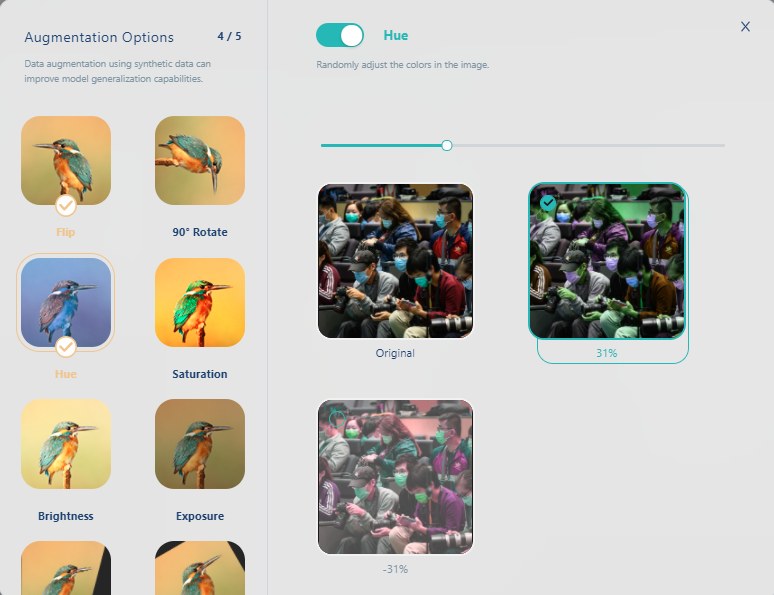
再选变亮(brightness)
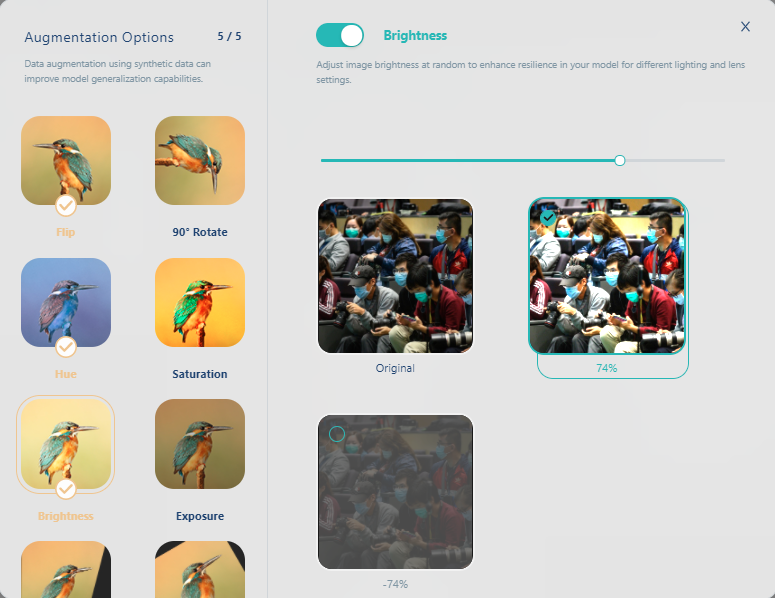
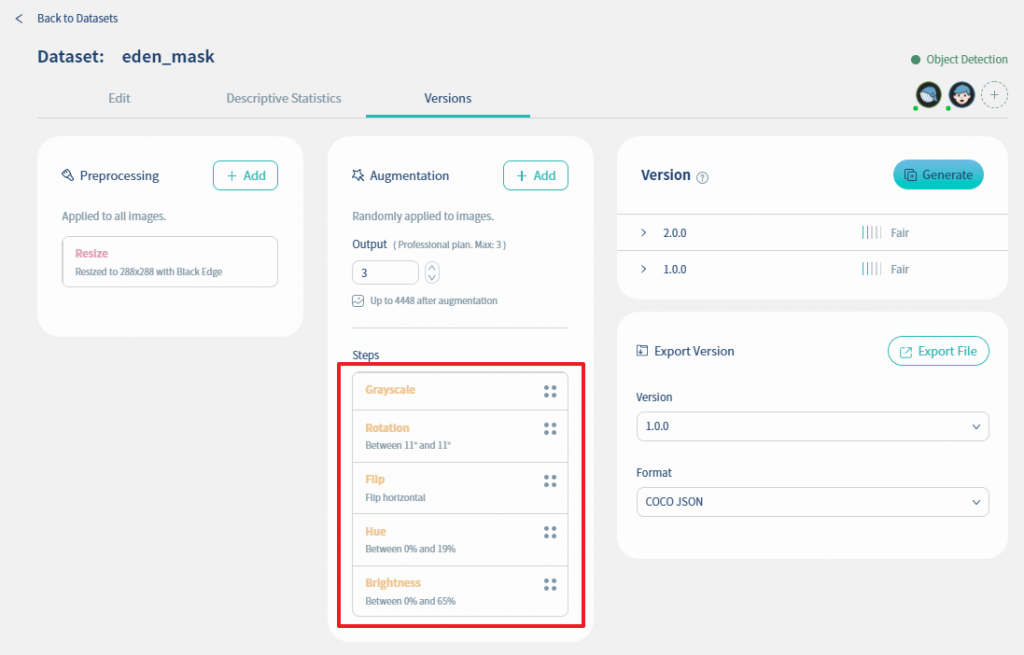
这时就可以看到我们把五种资料扩增机制加进来了. 同时再把output数设定为3. 这时可以看到资料集的图片张数增加到4448张
为资料集定义版本
当完成资料前处理与资料扩增之後, 就要把这组资料集给定一个版本, 这样之容易界定不同的资料集的差别, 也易於之後执行训练时选择不同版本名称就可以选到不同的资料集.
请点下图的Generate键
输入版本编号
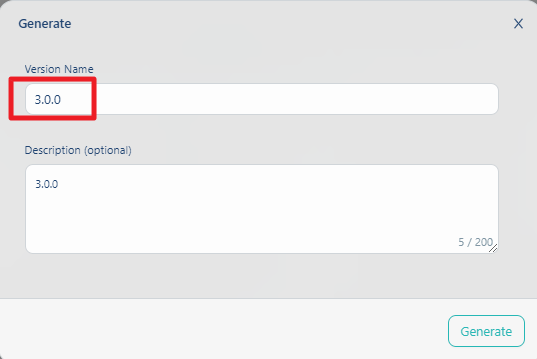
完成了之後, 可以看到Dataset版本已建立, 如下图. 在这个版本, 影像张数为4448张, 而且资料品质增加为三格(Good),可见资料扩增功能已有效增加dataset张数与品质.
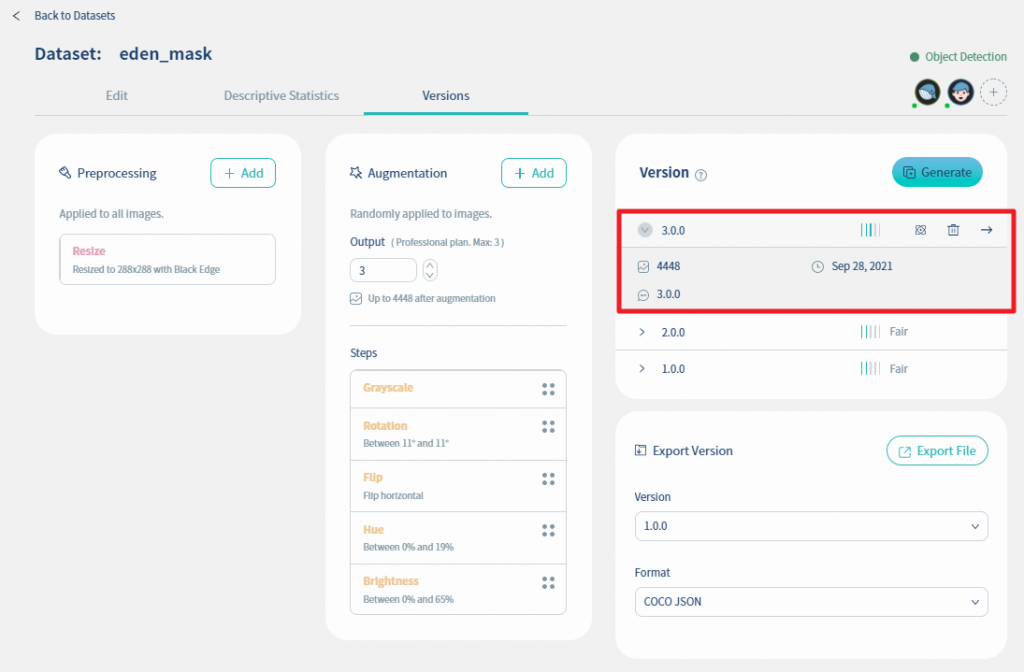
到这里我们使用使用机器标注中的全自动标注功能完成了口罩脸孔资料集的标注, 也完成资料前处理、资料扩增与版本建立, 下一篇我们就来执行训练
<<: 找LeetCode上简单的题目来撑过30天啦(DAY24)
网页颜色-30天学会HTML+CSS,制作精美网站
好的网站除了内容传达之外,颜色是进入网站的第一印象,可以针对文字大小、框线、背景色...等做变化,是...
Spring Framework X Kotlin Day 9 Rest Repository
GitHub Repo https://github.com/b2etw/Spring-Kotlin...
第二次参加铁人赛
今天要来分享我第二年参加铁人赛的故事!这时故事的时间线已经来到去年暑假。 进入正题 去年暑假,除了做...
Day 09 : 用於生产的机械学习 - 定义范畴 Scope
在 Day 05 ML 专案生命周期介绍分为 4 个阶段与 7 大主题,第 1 个阶段为「定义范畴...
Day-04 说明什麽是Rack?
官网的说明是: Rack, a modular Ruby webserver interface R...