【24】如果把 Dropout 放在 CNN 之後会发生什麽事
不知道大家有没有发现,目前现在主流的网路结构中已经愈来愈少看到 Dropout 了,在早期 VGG 还当红时,Dropout 在 Dense Layer 中是个很好的防过拟合手段,然而近年主流的网路结构朝全 CNN 层的思维来设计,Dense Layer 越少出现就导致了 Dropout 越少被使用。
那CNN就不能用Dropout 吗?这篇文章 Don’t Use Dropout in Convolutional Networks 做了几个实验比较 Batch Normalization 和 Deopout 比较的实验,文章认为 BN 可以很好的取代 Dropout。
那麽为什麽在 CNN 里面使用 Dropout 效果并不好?这篇文章 Dropout on convolutional layers is weird 有很好的证明,文章内中提到,一般 Dropout 用在 Dense Layer 时,我们就是屏蔽掉某几个节点的权重,但是如果 Dropout 用在 CNN 层时,因为 CNN 的卷积是有空间性的(例如3x3个像数),所以你无法很乾净的屏蔽权重的更新,因为邻近的 kernel 权重都会影响。
看完以上比较偏重理论的部分,我们还是要来实验当你硬要会发生什麽事?模型就拿 mobilenetV2 来做修改。
实验一:把所有 BN 全部替换成 Dropout
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False, drop_rate=0.0):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_dropout(shape, rate):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True, drop_rate=rate) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False, drop_rate=rate) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False, drop_rate=rate) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
return input_node, net
DROP_RATE=0.1
input_node, net = get_mobilenetV2_dropout((224,224,3), DROP_RATE)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
# model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 2.3033 - sparse_categorical_accuracy: 0.0998 - val_loss: 2.3033 - val_sparse_categorical_accuracy: 0.1000
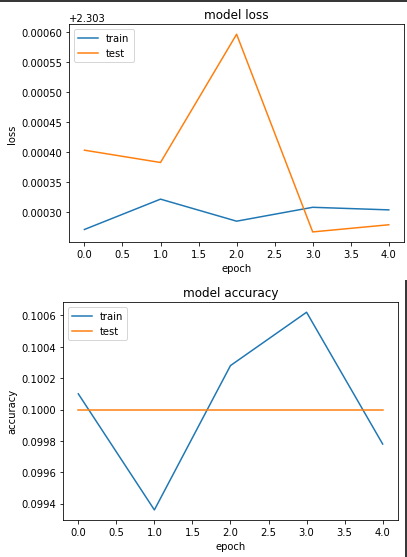
完全没在训练,很明显这样做并不行...
实验二:在有 BN 之後接 Dropout
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False, drop_rate=0.0):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(drop_rate)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_bn_with_dropout(shape, rate):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True, drop_rate=rate) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True, drop_rate=rate) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True, drop_rate=rate) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False, drop_rate=rate) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True, drop_rate=rate) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True, drop_rate=rate) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True, drop_rate=rate) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False, drop_rate=rate) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Dropout(rate)(net)
return input_node, net
DROP_RATE=0.1
input_node, net = get_mobilenetV2_bn_with_dropout((224,224,3), DROP_RATE)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
# model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出
loss: 0.6246 - sparse_categorical_accuracy: 0.7846 - val_loss: 0.7367 - val_sparse_categorical_accuracy: 0.7511
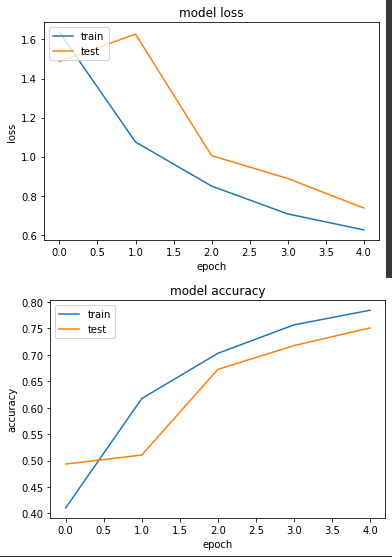
实验二有跑起来,虽然测试的 epoch 数量不多,但至少是有再训练的。
我个人实务上会用上 dropout 的时机大部分也是在模型後段如果有用上 Dense Layer 时,才会套用 Dropout,毕竟现在防止过拟合已经有更多手段可以选择。
<<: TailwindCSS - 价目表卡片实战 - 登入弹窗开发
>>: Day24-React 效能优化篇-上篇(四个优化效能的技巧)
Day18 Web Server 相关扫描
网站服务器是恶意攻击者最常攻击的目标,因为在许多设备都会有 web 介面,常见的网站服务器为 apa...
用资料结构看 evernote - 修改後 - DAY 11
修改的想法 整个结构应该会偏向某个知识领域,不太适合用於专案类型,但概念可以斟酌参考。 原先在记事本...
D29 - 用 Swift 和公开资讯,打造投资理财的 Apps { 三大法人成交比重实作.4 }
在上一篇,我们完成了 三大法人 vs. 非三大法人占比。 不过,三大法人占比还可以再用细项来分出,把...
【Day6】窗涵式,n_fft ,hop_length 到底什麽意思啊?
回填之前的坑 在往 Vocoder 迈进之前,我们先回顾一下之前我们在做 melspectrogra...
op.26 《全领域》-全域开发实战 - 居家植物盆栽 Mvt I (NodeMCU & MQTT)
op.26 打造属於你的时空廊道 为你我打造一个专属你的自由往返通道 让你可以任意地穿越 不再受拘...