[Day 25] 交叉验证 Cross-Validation 简介
今日学习目标
- 常见的交叉验证方法
- K-fold
- Leave one out cross validation
- Random Subsampling
- Bootstrap
前言
为了避免模型训练发生过度拟合,通常我们还会从训练集切一小部分资料出来进行验证。验证集的用处则是用来检视模型在训练过程中每次的迭代结果训练的好不好。但该如何切出这个验证集比较有公信力呢?如果我们仅切一小份的资料他是能有有效的评估训练时模型的好坏吗?在某些情况底下单纯直接从资料集里面切一块出来当验证集,是没有办法很有效的去评估一个模型训练的好坏。说不定训练出来的模型在这一份验证集恰好表现得不错,如果又随机抽另一份资料来当验证集说不定结果会变得很糟糕。这就表示模型泛化能力不足。为了避免这种情况发生并且有效的切割验证集来评估模型,我们可以采用交叉验证 Cross-Validation 的技巧来获得最佳验证。
什麽是交叉验证?
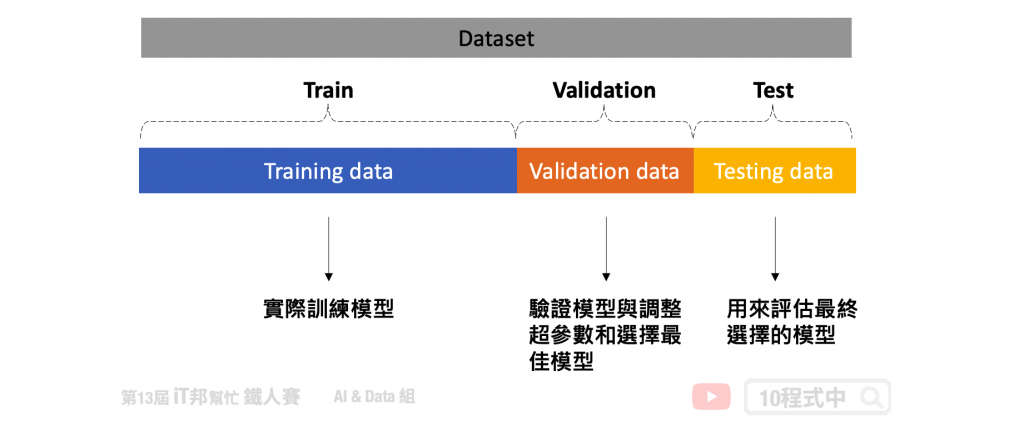
在解释交叉验证之前我们先来讨论将资料集切分为训练集、测试集和验证集的问题。在一般状况下我们会将资料先切割成两等份,分别为训练集和测试集。其中在训练阶段模型只会对训练集进行拟合,另外测试集的资料并未参与训练,因此可以拿来当作最终评估模型的好坏。但是我们训练的模型希望找到一个不错的超参数,使得模型在训练集和测试集都有不错的成绩,也就是说 loss 要越低越好。因此最常见的作法会将训练资料再切出一个验证集来找出一个最佳的模型参数,使得验证集的表现要最好。但是为了避免模型对於我们所切的验证集过度拟合,因此可已透过交叉验证的方法对模型做更好的评估。所谓的交叉验证简单来说是将训练资料进行分组,一部分做为训练子集来训练模型,另一部分做为验证子集来评估模型。用训练子集的数据先训练模型,然後用验证子集去跑一遍,看验证集的损失函数(loss)或是分类准确率等。等模型训练好之後,再用测试集去测试模型的性能。主要的交叉验证法有以下几个方法:
- Holdout
- K-fold
- Leave one out cross validation
- Random Subsampling
- Bootstrap

Holdout Method
此方法是最经典且最简单实作的交叉验证法,Holdout 顾名思义就是将资料切出一部分作为模型评估的依据。在这种方法中,我们将资料随机分为三部分:训练集、验证集和测试集。其中只有训练集资料实际参与训练,其余的资料仅拿来评估模型好坏。验证集使用时机是在训练过程中可以检视训练的趋势,若有发现过拟合拟合迹象可以提早发现并解决。以及方便我们进行调整超参数以及选择最佳的模型。当然仅透过验证集不能代表全部,因此最後确定好模型时。我们会再拿事先切好的测试集进行最终的评估,检视模型的泛化能力。
优点:
- 简单实作。
- 验证集可以被拿来评估模型在训练过程中的学习成果。
- 测试集可以评估模型泛化能力。
缺点:
- 当资料集变异量较大时,验证集与测试集可能无法足以评估模型。
- 不适合用在资料不平衡的资料集。
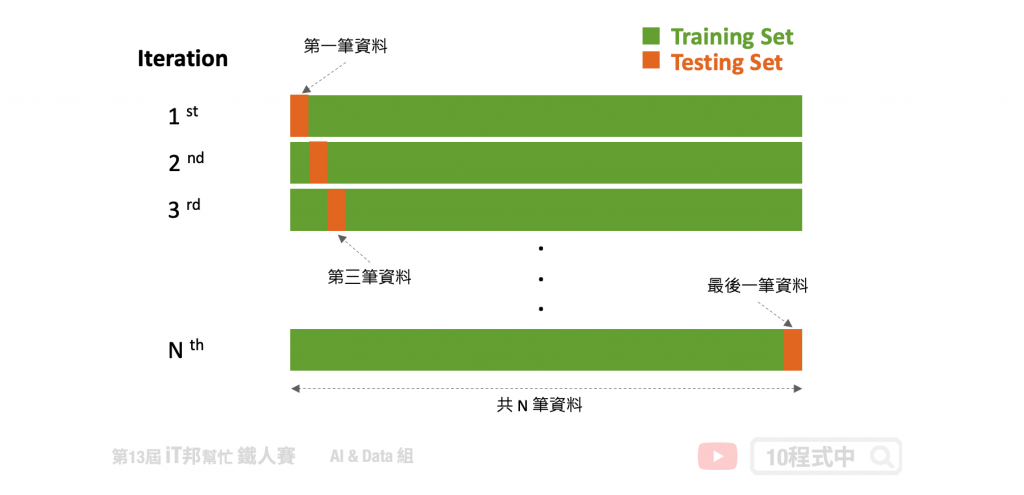
K-fold Cross-Validation
上一个方法虽然简单,但是在训练过程中仅切一份验证集往往不能够代表全部。因此我们可以透过一些技巧切割验证集,使得训练过程中有一个更公正的评估方式。我们可以透过 K-Fold 方法将训练资料再依序切割训练集与测试集,K-Fold 里面的测试集可以当成验证集。K-Fold 的方法中 K 是由我们自由调控的,在每次的迭代中会选择一组作为验证集,其余 (k-1) 组作为训练集。透过这种方式学习,不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不会那麽敏感。

优点:
- 降低模型训练对於资料集的偏差。
- 训练集与验证集完整被充分利用与学习。
缺点:
- 不适合用於资料不平衡的资料集。
- 如果要简单的 K-fold 来寻找超参数会有资料泄漏问题导致训练结果有偏差,因为在每个 Fold 中都会使用同一组资料进行验证。
- 在相同的验证集计算模型的误差,当找到了最佳的超参数。这可能会导致重大偏差,有过拟合拟合疑虑。
Leave One Out
此方法是 K-fold 其中一种特例,当 K 等於资料集的数量时就等於 Leave One Out 方法。也就是在每次训练时仅会把一笔资料当成测试资料,其余的 N-1 笔资料作为训练模型的资料。此作法相当简单明了,但是训练负担会非常重且耗时。然而 Leave p-out 是另一种技巧,其中的 p 使用者可以自己设定每次训练需要留几笔资料作为测试集。
优点:
- 简单且容易理解,好实作。
缺点:
- 需要花费更多的训练时间。
Random Subsampling
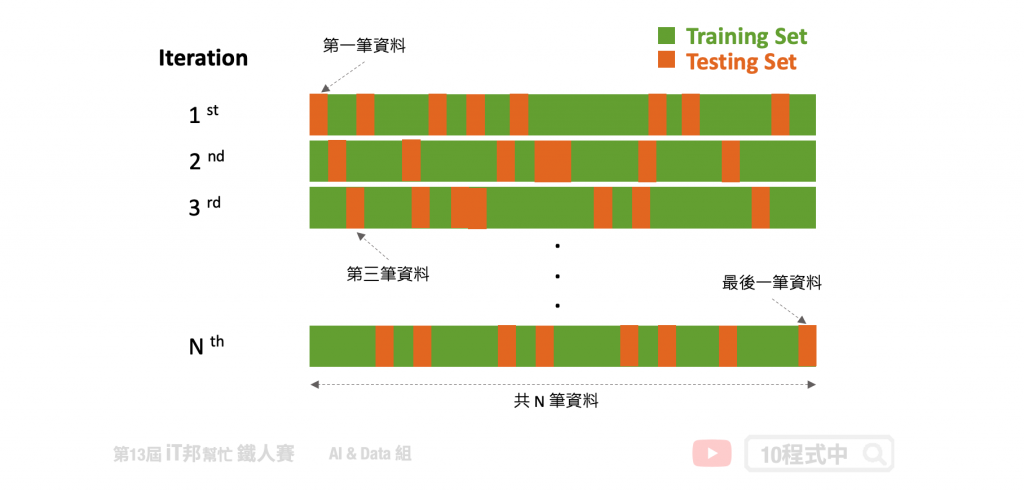
Bootstrapping
还有一种比较特殊的交叉验证方式,Bootstrapping 自助抽样法。是一种从给定训练集中有放回的均匀抽样,也就是说,每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。假设每次训练都采样十个样本,在这十笔资料中很有可能会再次被随机抽到。剩下没有抽到的资料则都变成测试集,用来评估训练完的模型。

小结
交叉验证是训练模型中非常重要的技巧,尤其是当手边的资料集有限时更应该使用。透过交叉验证技巧,即使在数据有限的情况下,我们也能够获得准确的结果,并且可以避免模型过度拟合。并为我们提供更准确的模型预测性能估计方式,同时也能够提升模型的泛化能力。以上的方法可以直接使用 scikit-learn 里面 model_selection 底下的 cross_val_score 方法进行实作。
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: [Day22] Deployment Manager
理解 HTTP(三):透过 HTTP 上网安全吗?浅谈网路安全、HTTPS、中间人攻击
聊了 HTTP 的基本概念(网站内容是怎麽被下载到电脑里的?、Method、Status Code)...
【Day10】ASI 自动插入分号
ASI(Automatic Semicolon Insertion) 当 JavaScript 语句...
Rails belong_to
belongs_to 的设定 optional 在 Rails 5.1 之後的版本,belongs_...
接API
缘由: 接API大概是在科技业的面试时最常问的问题了吧,但老实说资料的复杂性能不能接得正确好像才是关...
Day29 Data Storage in iOS 05 - Core Data 实作专案范例
之前在Android 就接触过MVC、MVP以及MVVM,这边先不对各差别去作比较分析,直接来对M...