[Python 爬虫这样学,一定是大拇指拉!] DAY22 - 实战演练:HTML Response - 抓取股票代码清单 (1)
承接上篇,抓日成交资讯时,我们得知道股票代码,那如果我想要有一个可以定时更新的股票代码清单,要去哪里拿呢?
抓取所有股票代码 - 寻找 URL
-
一样到证交所网站,点选
产品与服务,证券编码底下的证券编码查询或证券编码公告两个都可以用。差别在於证券编码查询出来的结果可以自己设定Filter,而证券编码公告就是全部上市的股票代码,包含股票、权证、ETF等等全部都给你啦!至於要使用哪个,可以依照自己的需求去做选择。我自己是只需要上市股票的代码而已,又懒得另外处理分类,所以选择从证券编码查询抓取股票代码。

-
点选
证券编码查询页面的证券编码 分类查询。
-
会来到此页面,把
Filter条件设定好,按下确定。
-
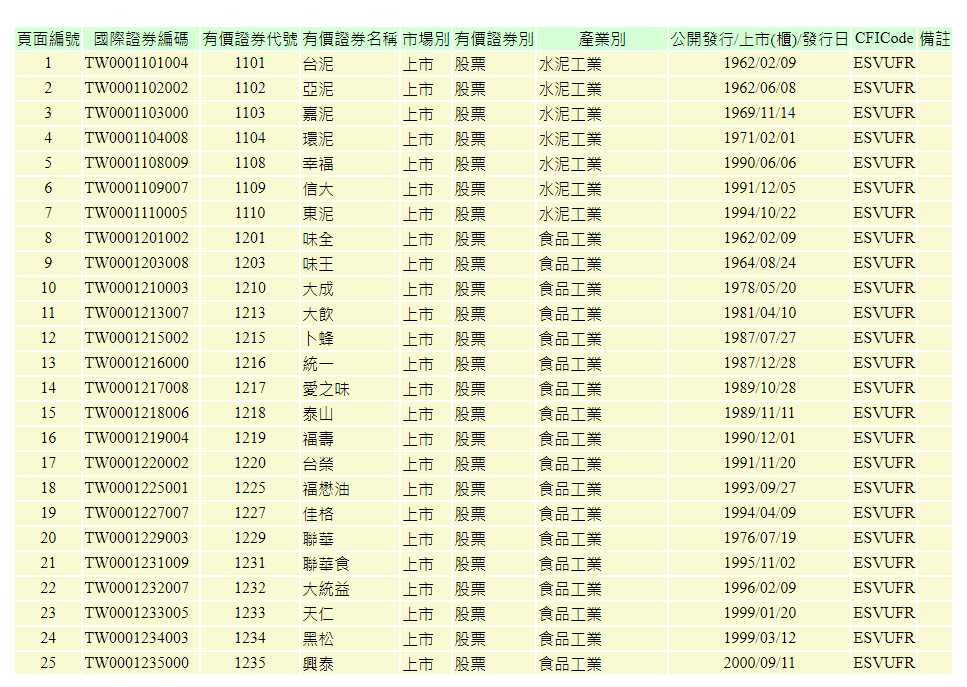
结果页面:
-
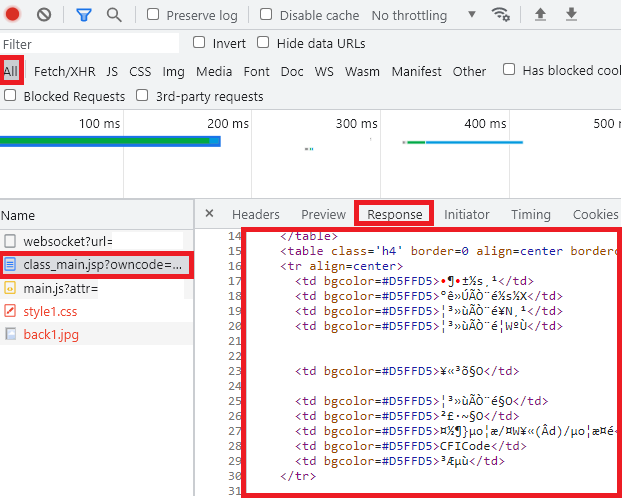
依照前篇所教的来确认 URL、Headers、Query、Request/Response 等资讯。另外,前篇提到从
Fetch/XHR去找 URL 的方法,但我们在这个页面上用Fetch/XHR找的话是找不到该 URL 的,所以可以知道这是静态网页 HTML。我们只要把开发人员工具切换到All就能找到了。
-
奇怪!?阿怎麽 Response 有乱码?
一样根据前篇所教的,确认它Response Headers的Content-type。
Content-Type:text/html;charset=MS950
OK!是编码的问题,所以之後在爬虫程序记得处理,避免乱码。
-
整理一下所知资讯:
- URL:
https://isin.twse.com.tw/isin/class_main.jsp。 - 必要的 Query:
market=1&issuetype=1&Page=1&chklike=Y。 - 所以可以根据需求在 Query 的 market、issuetype、Page、chklike 代入自己要的值。
- HTTP Method 是 GET。
- Content-Type:text/html;charset=MS950,所以格式是 HTML,编码为 MS950。
- URL:
抓取所有股票代码 - 安装 Beautiful Soup
但 Requests 套件本身没有支援 HTML 的 parser,所以要嘛自己写要嘛装别的套件。
用膝盖想也知道,当然是装套件罗!
我们要使用的是套件叫做 Beautiful Soup。它的特色就是让不同的 HTML Parser 透过它提供的 Interface 来统一操作方法 。
-
安装 Beautiful Soup。
pip install beautifulsoup4 -
再来是安装 Parser。Beautiful Soup 除了有支援 Python 原生的 HTML Parser,也有支援一些第三方的 Parer。
引用自Beautiful Soup 官方:If you can, I recommend you install and use lxml for speed. If you’re using a very old version of Python – earlier than 2.7.3 or 3.2.2 – it’s essential that you install lxml or html5lib. Python’s built-in HTML parser is just not very good in those old versions.
官方文件是推荐使用 lxml。所以我们就安装 lxml 吧!
-
安装方法:
pip install lxml另外,下图是官方有支援的 Parser 及差异比较。
-
都安装完成後测试一下。
from bs4 import BeautifulSoup html = "<html>test test test</html>" soup = BeautifulSoup(html, "lxml")

本篇章目前先这样,让大家消化一下,Beautiful Soup 的基本用法就不另外讲解了,建议可以看一下 Beautiful Soup 官方文件的 Quick Start。下篇文章就要开始讲解怎麽用程序抓股票代码清单罗!
[Day08] 第八章-Laravel的CRUD操作及一些简单指令
前言 今天会介绍laravel一些简单的指令 以及建立路由还有CRUD方法 跟资料库连线喔!! 目标...
Material UI in React [Day9] Inputs (Radio) 单选 & (Switch) 开关
Radio 当用户需要查看所有可用选项时使用单选按钮,如果可用选项可以折叠,请考虑使用下拉菜单(Se...
[Day9] Cloud SQL
昨天介绍完了储存各种档案可以使用的 Cloud Storage,今天要来介绍另外一个很常见的储存服务...
机器学习:演算法
线性代数 LR:逻辑回归(Logistic Regression): 预测事件发生的机率(y=1)...
Day 29 : 用於生产的 TensorFlow Extended (TFX) 实作
用於生产的机械学习系统,在 Day 28 介绍 TensorFlow Extended (TFX)...