[Day 21] Edge Impulse + BLE Sense实现唤醒词辨识(中)
=== 书接上回 [Day 20] Edge Impulse + BLE Sense实现唤醒词辨识(上) ===
模型设计
这项功能原来英文为「Impulse design」,但翻译成「冲动设计、驱使设计、推动设计」亦或其它,好像也有点怪,所以乾脆直接以它的作用「模型设计」来翻译。其主要工作画面如图Fig. 21-1所示。接下来就介绍组成它的几大区块。
- 时间序列资料
- 信号处理区块
- 学习模型区块
- 输出特徵储存
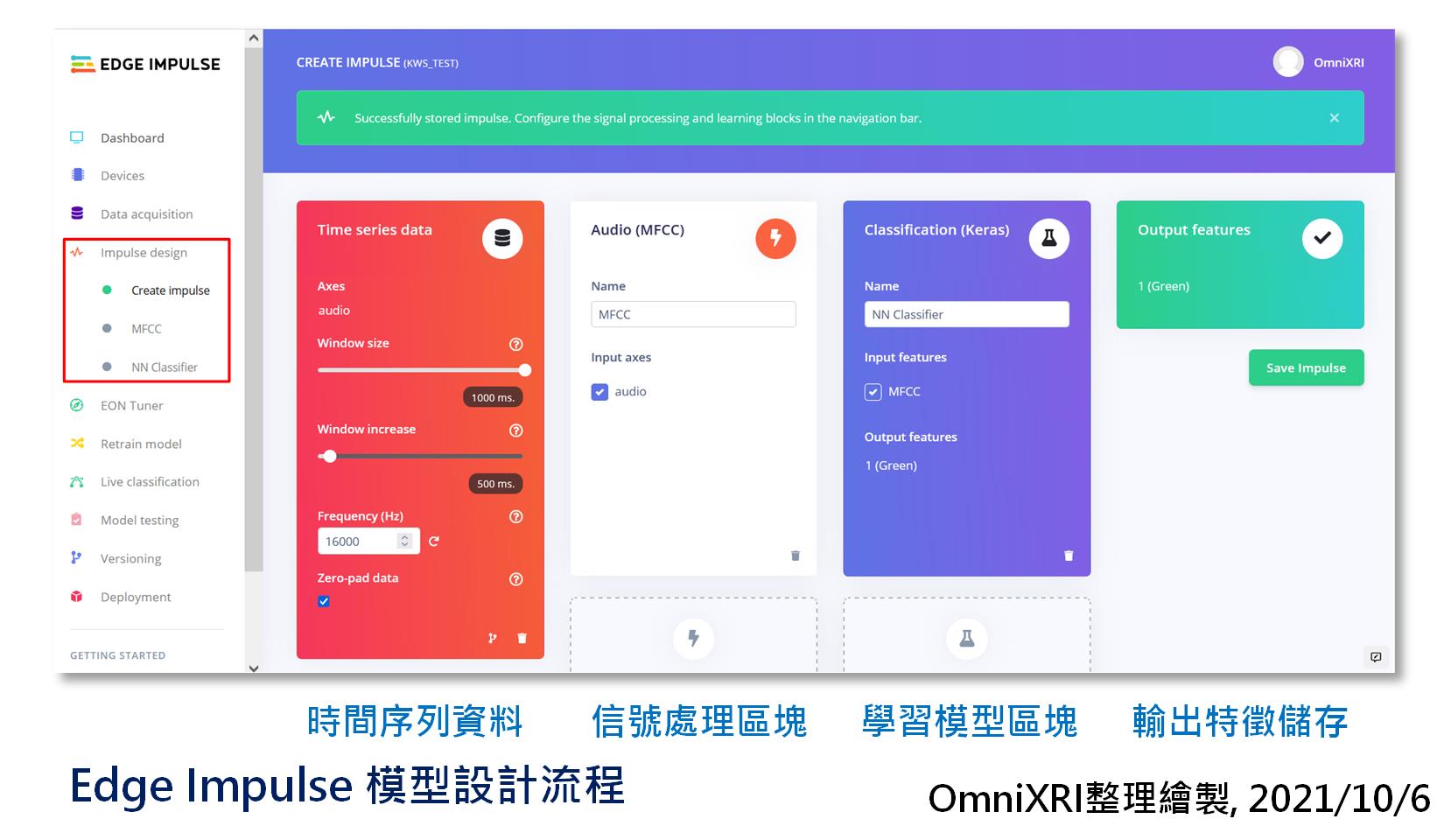
Fig. 21-1 Edge Impulse 模型设计流程。(OmniXRI整理绘制, 2021/10/6)
时间序列资料
在这个区块主要设定时间序列资料处理的基本参数,包括视窗大小(预设1000ms)、视窗移动递增(预设500ms),取样频率(预设16KHz)及资料不足视窗大小时是否补零(Zero-pad data,预设勾选,会自动补零)。
信号处理区块
点击闪电符号,新增信号处理区块(Add a processing block),即一小段信号前处理程序,可包括声音、影像或感测器信号处理,可支援的项目如下所示。另外亦可选择使用不处理的原始资料或自定义处理区块。选择时需依信号类型选择。在这个范例中,主要是针对人类语音辨识,所以选择「MFCC」即可。
- Audio (MFCC) : 使用梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients, MFCC)从声音讯号提取特徵,很适合人类语音**(推荐使用)**。关於更多MFCC的原理可参考官方说明文件。
- Audio (MFE) : 使用梅尔滤波器组能量(Mel-filter bank energy, MFE)从声音讯号提取频谱,很适合非人类语音**(推荐使用)**。关於更多MFE的原理可参考官方说明文件。
- Flatten : 将轴展平为单个值,对於缓慢移动的平均值(如温度数据)很有用,用来结合其他区块。
- Image : 预处理和正规化影像数据,并可选择降低色彩深度(通道数)。
- Spectral Analysis : 频谱分析非常适合分析重复运动,例如来自加速度计的数据。提取信号随时间变化的频率和功率特性。
- Spectrogram : 从音频或感测器数据中提取频谱图,非常适合非语音声音或具有连续频率的数据。
- Audio (Syntiant) : 仅适用Syntiant产品。从声音信号计算对数梅尔滤波器组能量特徵。
- Raw Data : 使用未经预处理的数据。如果想使用深度学习来学习特徵则很有用。
- Custom Block : 自定义区块处理,更进一步作法,可参考官网说明文件。
根据维基百科「梅尔频率倒谱系数」的说明如下。白话一点来说就是类似[Day 17]介绍过的频谱转换,把时间域转成频率域再转成频谱图的作法,以提取更有用的声音特徵出来。
在声音处理领域中,梅尔频率倒谱(Mel-Frequency Cepstrum)是基於声音频率的非线性梅尔刻度(mel scale)的对数能量频谱的线性变换。
梅尔频率倒谱系数 (Mel-Frequency Cepstral Coefficients,MFCCs)就是组成梅尔频率倒谱的系数。它衍生自音讯片段的倒频谱(cepstrum)。倒谱和梅尔频率倒谱的区别在於,梅尔频率倒谱的频带划分是在梅尔刻度上等距划分的,它比用於正常的对数倒频谱中的线性间隔的频带更能近似人类的听觉系统。 这样的非线性表示,可以在多个领域中使声音讯号有更好的表示。例如在音讯压缩中。
梅尔频率倒谱系数(MFCC)广泛被应用於语音识别的功能。他们由Davis和Mermelstein在1980年代提出,并在其後持续是最先进的技术之一。在MFCC之前,线性预测系数(LPCS)和线性预测倒谱系数(LPCCs)是自动语音识别的的主流方法。
一段声音经过MFCC转换会图Fig. 21-2所示。如果想检查某一个已分割好的声音样本,可点选左上角下拉式选单选择档案。此时网页上方就会出现原始时域信号,亦可按三角形播放键来听一下内容,而下半部份的MFCC参数有需要时可进行调整,原则上可先不动它,使用预设值即可。右侧就会显示MFCC转换後的结果及在Arduino Nano 33 BLE Sense (Arm Cortex-M4F @ 64MHz)运作时所需的时间和占用的记忆体大小。由图上的数据可知,将一个声音讯号转换成MFCC需要234ms,若再加上模型推论时间,则每秒大概只能推论2到3次,看似有点慢,但足够用在像智慧音箱或语音控制家电的反应时间了。
另外补充一点在[Day 17]图Fig. 17-2的单一视窗FFT结果是以横轴(X方向)排列,而緃轴(Y方向)为时间轴,组成最後的频谱图(Spectrogram)(粉红色那块)。而这里的频谱图采相反表现方式,纵向代表频率而横轴代表时间。从图Fig. 21-1左下角的图示中,大概可以看出单纯的图谱转换和使用MFCC在特徵(比较红的区域)表现上有明显的差异,较有利後续模型训练及推论。
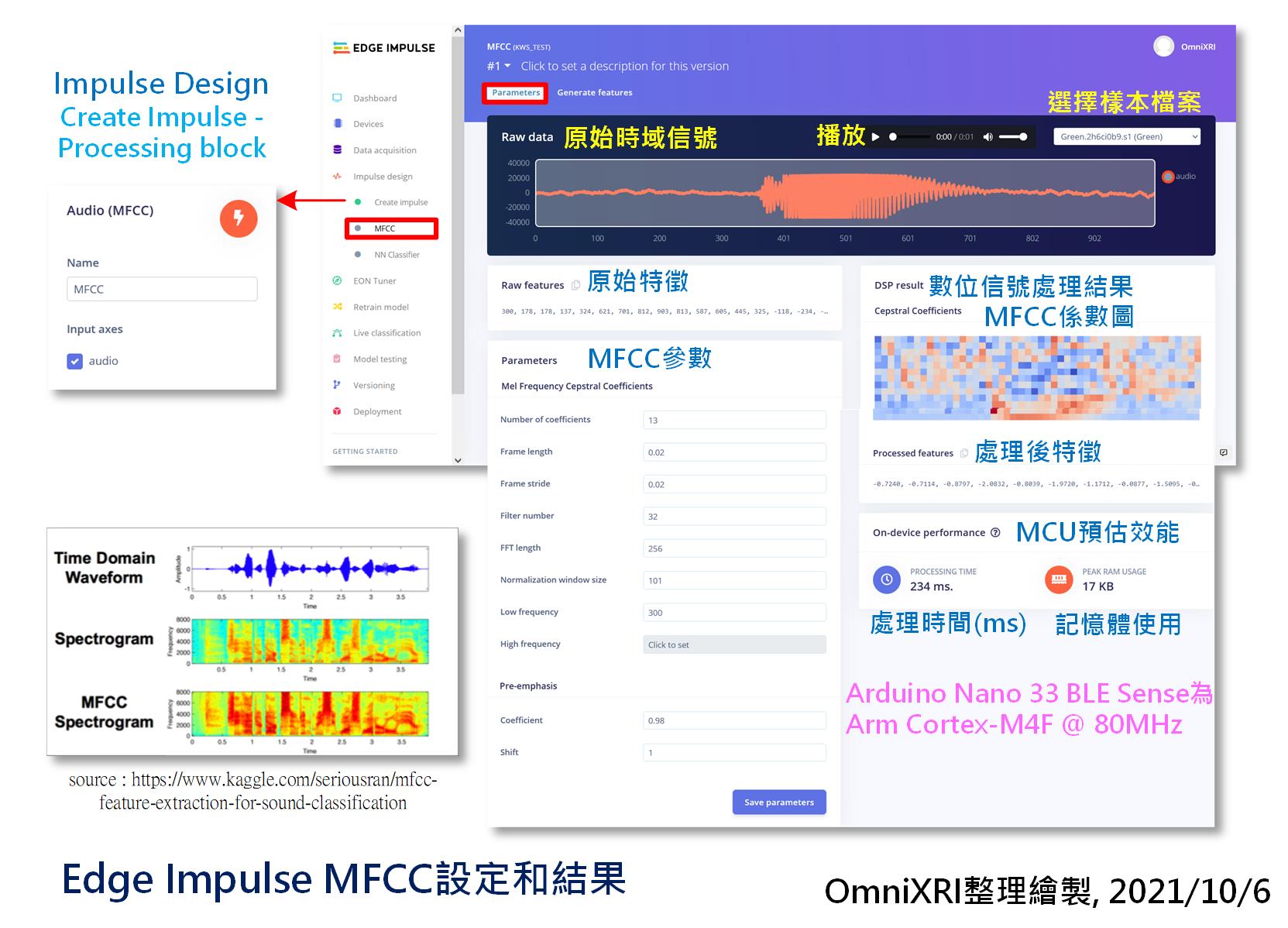
Fig. 21-2 Edge Impule MFCC设定和结果。(OmniXRI整理绘制, 2021/10/6)
接着还要从页面上方点击「产生特徵(Generate features)」切换页面,如图Fig. 21-3所示。进入後会显示目前训练集的基本参数,这里准备了四个分类,背景音(BG)、红(Red)、绿(Green)及未知(Unknow),每个分类训练集有16个声音档案,而测试集则有4个,合计80个样本。不知道如何产生资料集的朋友可以参考[Day 20] Edge Impulse + BLE Sense实现唤醒词辨识(上)「资料撷取」小节说明。
接着再按下【Generate features】,泡杯咖啡稍等一下(资料集大的话就泡个面或泡个澡再回来)。完成特徵提取後就会产生一个资料集三维分布图,可在图上按住滑鼠左键上下左右移动来旋转观看视角,当按住滑鼠右键移动则为平移视窗内容,而滚动中键滚轮则可用来改变视图缩放比例。从这个资料分布图大概可看出是否容易辨识(分割),若资料集交错重叠的很严重,则後面训练出来的准确率可能就不会太高,需要重新检讨资料集建立的方式,透过增加数量及多样性来改善。
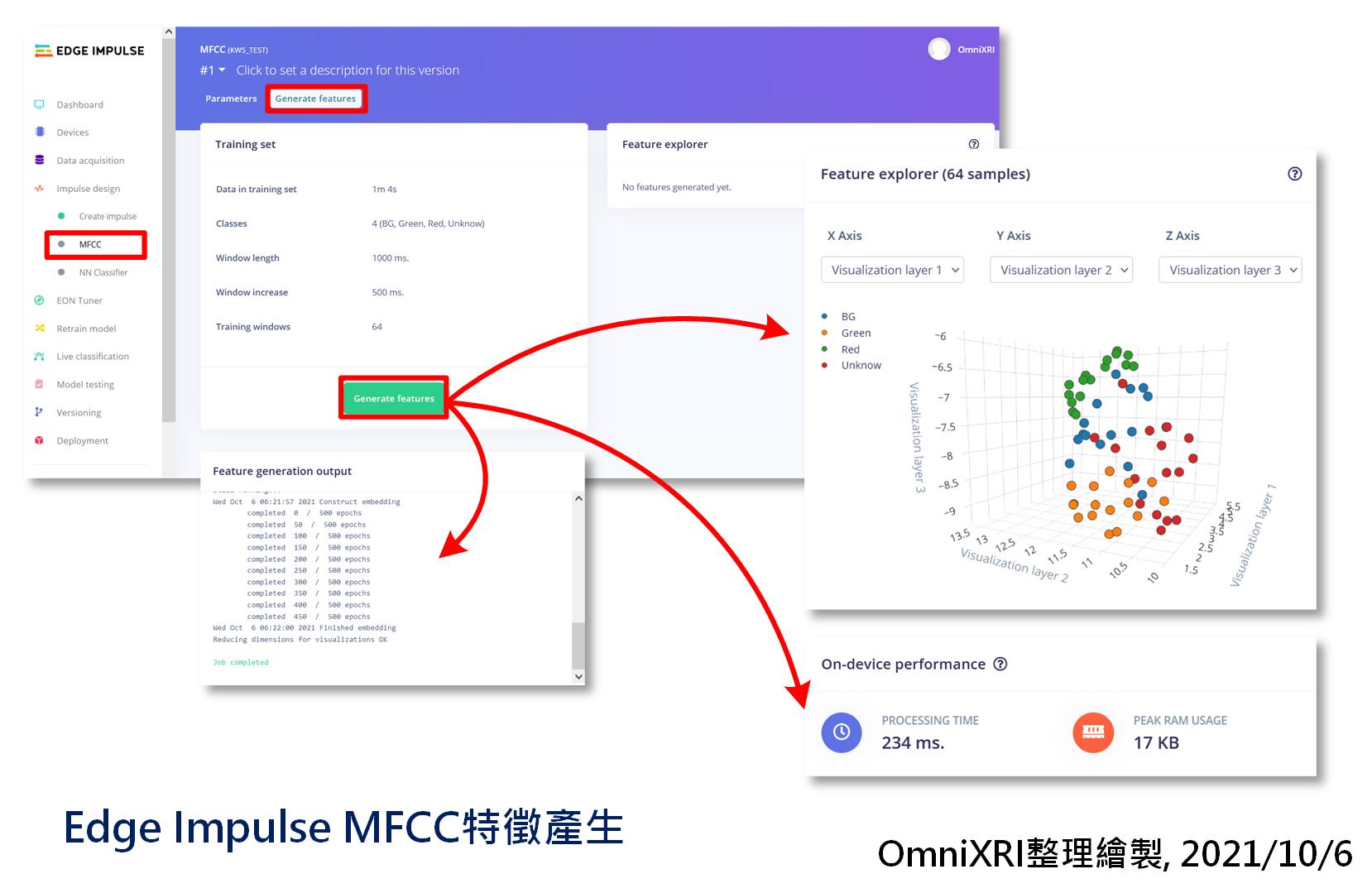
Fig. 21-3 Edge Impulse MFCC特徵产生。(OmniXRI整理绘制, 2021/10/6)
学习模型区块
再来就是tinyML最重要的一部份,神经网路(或称模型)的建置和训练。进到Impulse design的页面新增一个「学习区块(Learning block)」,选择「Classification(Keras)」,按下【Add】,即可产生一个新的区块,上面显示勾选MFCC,输出有四个分类,如图Fig. 21-4所示。
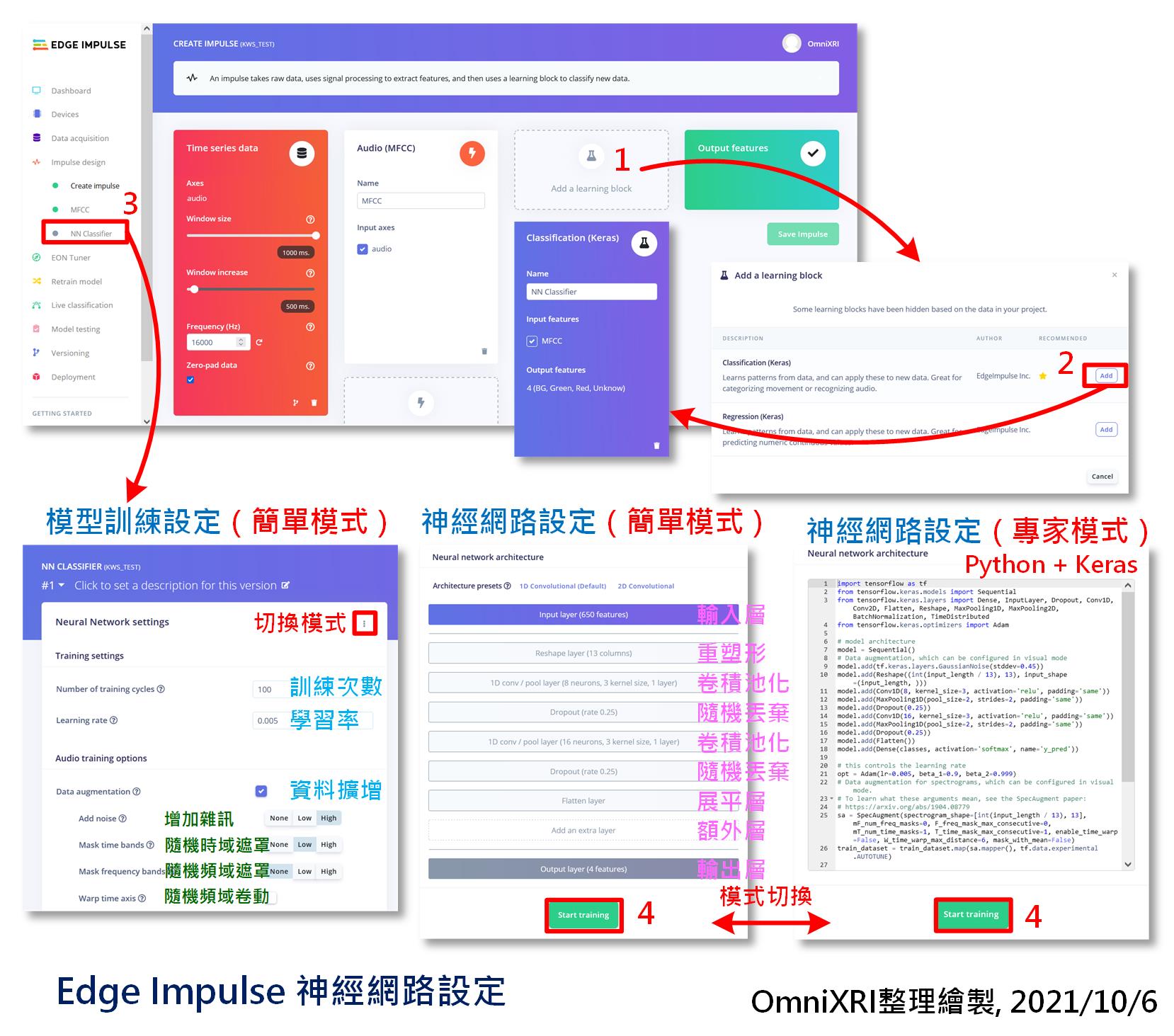
Fig. 21-4 Edge Impulse 神经网路设定。(OmniXRI整理绘制, 2021/10/6)
接着切到「NN Classifier」页面,设定训练次数、学习率及是否启动声音资料的扩增(Data Augmentation),包括增加杂讯、随机时域/频域的遮罩和随机频域卷动。如果一开始不知如何设定那就先用预设值即可。再来是设定模型的网路结构,这里已先帮我们建好了一个,直接使用即可。若你已是熟悉Python和Keras且了解AI模型设计方式的人,也可切换到「专家模式(Expert)」直接改动程序(网路设计)即可。如图Fig. 21-4所示。
通常使用预设的「简单(Simple)」模式即可。它还提供一个新增额外层的项目,可选择项目如下所示。如果对神经网路基本元素不清楚的朋友,可以到[Day 05] tinyML与卷积神经网路(CNN)复习一下。
- Dense 全连结层(将两层所有节点都连在一起)
- 1D Convolution / Pooling 一维卷积和池化层(用於声音或感测器连续信号)
- 2D Convolution / Pooling 二维卷积和池化层(适用於影像资料)
- Reshape 重塑形(用来调整输入矩阵的维度,可由多维变一维或由一维变多维)
- Flatten 展平层(把二维的节点全部变成一维排列,做为全连结之前的准备)
- Dropout 随机丢弃(用於训练时避免过拟合的机制)
最後按下【Start Training】就会开始训练,这个步骤所需耗费的时间和资料集大小和模型复杂度、参数多少有直接关连。若不想等太久,可先把训练次数调小一点,看看输出结果是否有变好趋势。如果有,只是推论精准度不足,那就把训练次数加大,以提高精准度。待训练完成後,会产生准确率(Accuracy)、损失值(Loss)、混淆矩阵(Confusion Matrix)、特徵提取(Features Expolorer)分布及预计布署在MCU上後推论时间(Inference Time)、记忆体使用峰值(Peak RAM Usage)及程序码(模型结构及参数)使用量(Flash Usage)。如图Fig. 21-5所示。至於训练结果好坏及调整方式就留待後面章节再行说明。
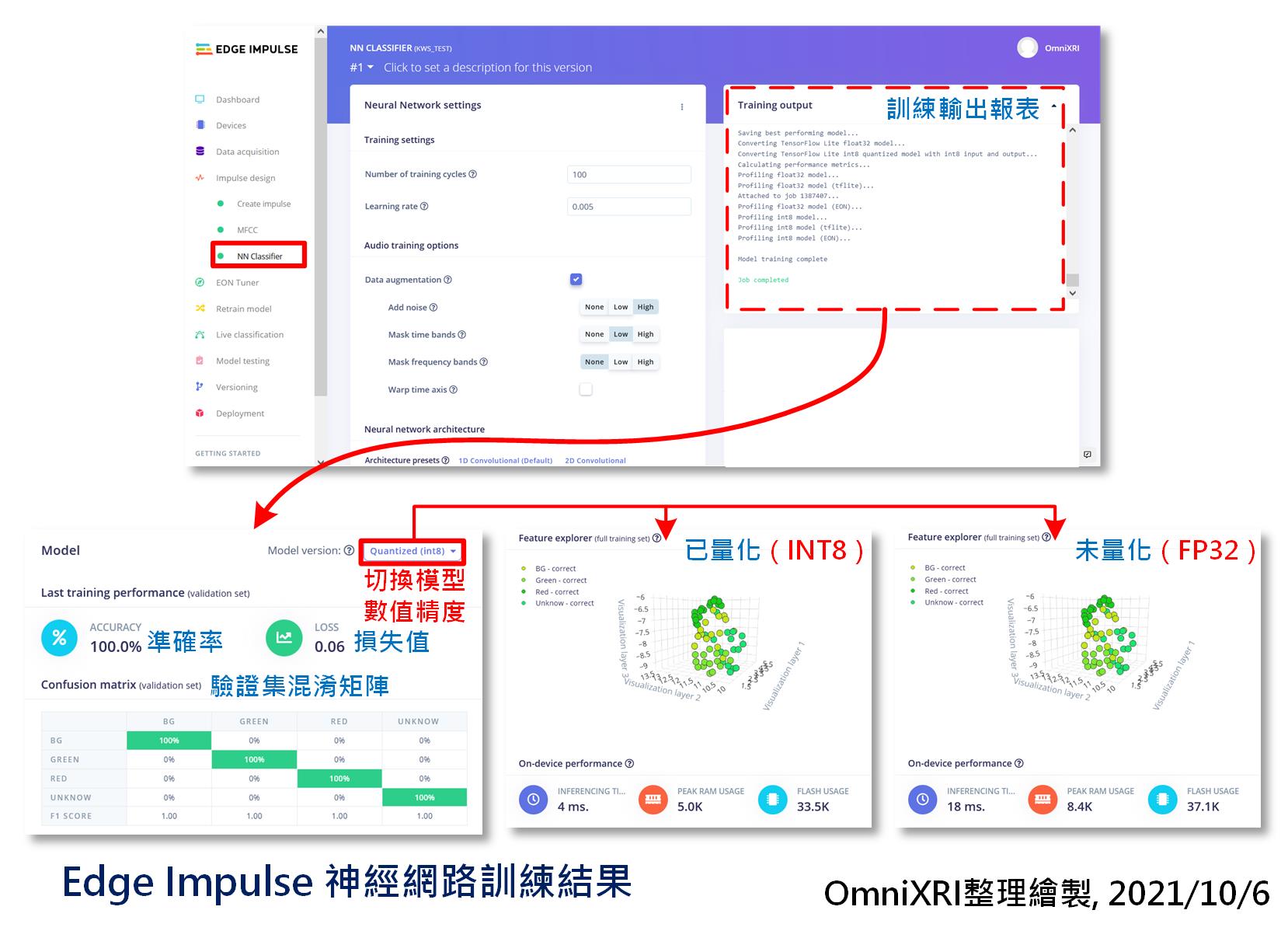
Fig. 21-5 Edge Impulse神经网路训练结果。(OmniXRI整理绘制, 2021/10/6)
另外系统预设会使用INT8(8bit整数)方式进行量化(优化),若想切回FP32(32bit单精度浮点数)原始训练结果来提升一点准确度,则可自行切换,如图Fig. 21-5所示,系统会自动重新算出MCU所需资源,方便评估是否满足推论速度及超出MCU硬体规格需求。但要注意的是,如果是不支援浮点数计算或者单指令周期浮点数指令的MCU,那推论时间可能就会大幅增加。以这个案例举例,MFCC转换花了234ms,INT8推论用了4ms,加上其它一些IO或通讯所需,合计应该不会超过250ms,换算後大约1秒可取样辨识4次结果,算是很OK的速度了。
输出特徵储存
在「Impulse design」这个页面最右边的选项,基本上并没任何动作,按下【Save Impulse】就完成初步工作。
Impulse Design 小结
看到这里有没有觉得[Day 17] TFLM + BLE Sense + MP34DT05 就成了迷你智慧音箱(下)所提及的声音资料采集、分割、分群(训练/验证/测试集)、信号处理、频谱转换、模型选用、训练等工作都变简单了,这里不用写半行程序,也不用使用额外工具,一口气就全部完成了。如果前面有被劝退跳过课程的朋友可自行回补一下,应该会更容易看懂。
=== 话多了点,还得再一篇才说得完,敬请期待 ===
参考连结
Edge Impulse Tutorials - Responding to your voice 说明文件
Edge Impulse Tutorials - Processing blocks 说明文件
<<: 不只懂 Vue 语法:为何懒加载路由和元件会提升网页效能?
[Day26] Click and Drag to Scroll
[Day26] Click and Drag to Scroll 需要用到的技巧与练习目标 mous...
[Day03] .NET 5
咱们写扣的人,大概只有学生时代会自己手刻玩具来用,目的多半是为了交作业或者第一份工作的面试要 dem...
Day18:图形搜寻-戴克斯特拉演算法(Dijkstra's algorithm)
贪婪(Greedy)演算法 贪婪演算法是考虑局部最佳解,在子结构中解决问题是相当有利的,但放入整体问...
Day28 LINE BOT & NBA - 球员数据查询
今天因为时间的关系,原本应该要完成两个功能,但是先完成一个,段考完再来补QQ 今天要实现的功能有 查...
JavaScript Day16 - 箭头函式
函式陈述式与函式表达式 函式陈述式:之前直接定义 function 的方式 会被提升到最上面,所以可...