[Python 爬虫这样学,一定是大拇指拉!] DAY21 - 实战演练:JSON Response - 抓取个股日成交资讯
好的,讲解完 Requests 套件的基本介绍後,终於要进入真实情况的爬虫应用拉!
但我们一步一步来,先从简单的开始,运用我们前面提到的基本应用来做个小爬虫。
所以我们要来爬什麽呢?
我们来爬股票吧!毕竟股票一直都是人气很高的项目,不管在任何领域
爬虫前要注意:爬下来的资料在你打算使用的地方,是否有违反该网站的申明。
总之爬虫前要记得详阅网站规章喔
我们要抓的是台湾证券交易所的资料,我们操作前确认一下使用条款,确认没问题我们就开始罗!
抓取个股日成交资讯 - 寻找 URL
-
抓资料前我们得先看看要透过哪个 URL 才能取得资料,那怎麽找呢?
-
连线至台湾证券交易所。
-
点选上方
交易资讯,选择个股日成交资讯。

-
来到此页面。
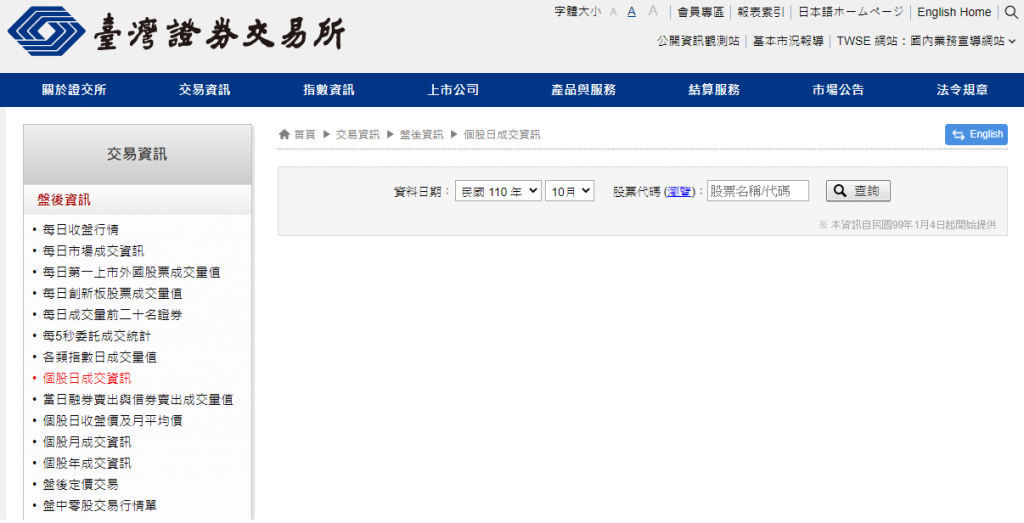
-
依照网页提供的介面操作,输入
股票代码後点击查询按钮,确认资料是我们想要的。
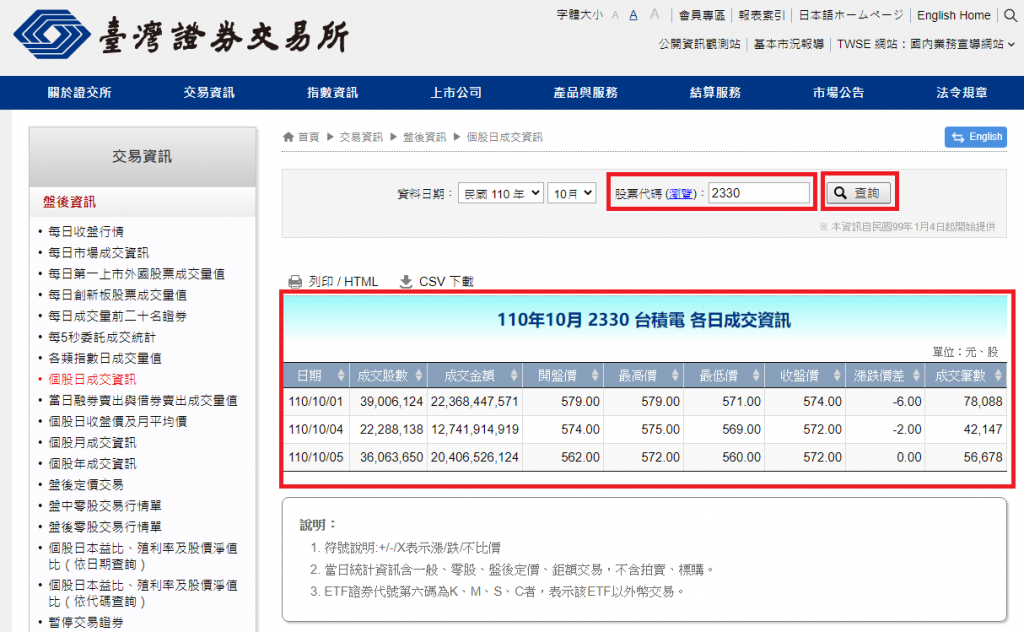
-
确认无误後,开启
开发人员工具(Chrome 快捷键为 F12)。依照图片红框项目,选取栏位Network、Fetch/XHR。请确保图片第二排左边之红框红灯是恒亮状态(表示有在记录网页的行为),若有其他杂其砸八的 URL 一直跳出来扰乱请点击第二排右边之禁止符号(clear 的意思)。
Fetch/XHR:主要是陈列 AJAX 的 HTTP Request / Response。
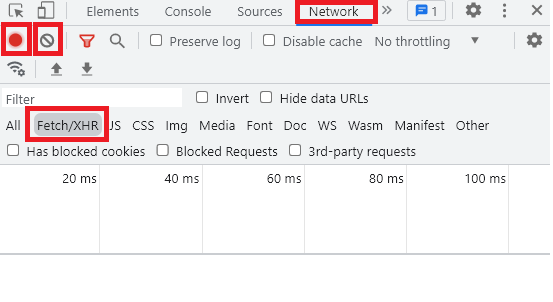
-
重复步骤4,依序确认左列清单得到的 Response(Preview 栏位会帮你把资料整理好,比较好看)。所以我们确定第一个清单项目就是我们要的,如下图。
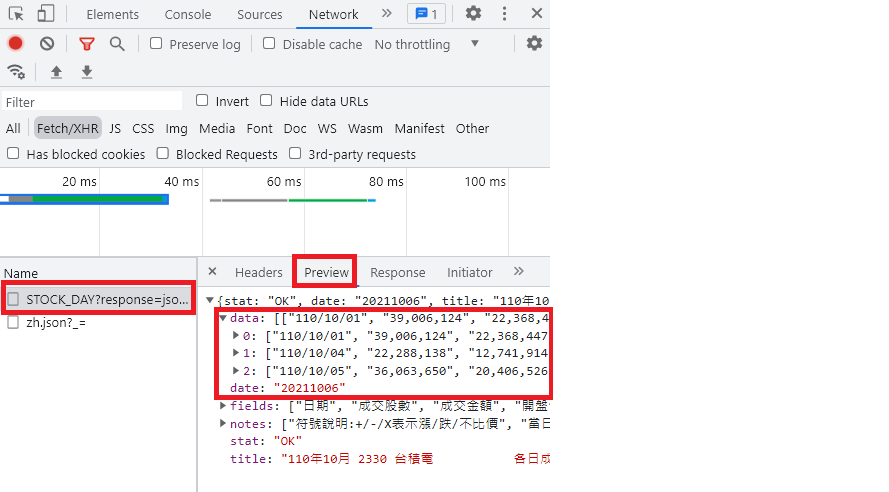
-
点选
Headers,看General的Request URL及Method与Response Headers的Content-Type可以知道:

- URL:
https://www.twse.com.tw/exchangeReport/STOCK_DAY。 - 必要的 Query:
response=json&date=20211006&stockNo=2330。 - 所以可以根据需求在 Query 的 response、date、stockNo 代入自己想要的值。_是代表 Cache 的意思所以在程序里可以不用代入(後面的数字我码掉了)。
- HTTP Method 是 GET。
- Headers 的 Content-Type:application/json;charset=UTF-8 所以格式是 JSON,编码为 UTF-8。
- 另外我们也知道了,
不管我们 Query 的 date 是几号,他的 server 是整个月份的日成交资讯都回给你,这点要注意一下喔!
- URL:
-
抓取个股日成交资讯 - 爬虫程序
-
从上面的已知资讯,我们程序可以这样写
import requests url = "https://www.twse.com.tw/exchangeReport/STOCK_DAY" res = requests.get(url, params={ "response": "json", "date": "20211006", "stockNo": "2330" }) # 把 JSON 转成 Python 可存取之型态 res_json = res.json() # 我们要的每日成交资讯在 data 这个栏位 daily_price_list = res_json.get("data", []) # 该栏位是 List 所以用 for 回圈印出 for daily_price in daily_price_list: print(daily_price) -
输出:

比对一下跟使用浏览器得到的结果一样就是没问题罗!
以上就是寻找目标 URL 及抓取个股每日成交资讯,程序部分因为只是个范例,可以再依照自己需求去做变化!
>>: Urban Kitchen 名厨都汇自助餐厅 #万豪酒店 #澳门银河渡假村 Galaxy Macau
【LeetCode】Dynamic Programming I
今天依然手动 redirect 【Day 5】逻辑时间与广播 反正网路上讲 dp 的多的是,dp写得...
Day 23:二元树分支总和 sums of the branches
今天这题题目是国外论坛分享的面试题, 其实也是LeetCode-Path Sum的衍生题,直接来刷题...
Chapter3 - 动感DJ续篇 进一步操作阵列,让音乐嗨起来
打了2000字消失了怎麽办呢(´・_・`) 先去上个厕所压压惊,恳请IT邦邦忙快优化界面 在编辑介面...
DAY23:优化器(下)
开始比较各种优化器 这边都采用变动学习率CosineAnnealing。示范我这边T_max只用6。...
30天程序语言研究
今天是30天程序语言研究的第十七天,由於深度学习老师多让我们上了python的进阶课程里面包括之前没...