[Day 20] Edge Impulse + BLE Sense实现唤醒词辨识(上)
在[Day 16]和[Day 17]「TFLM + BLE Sense + MP34DT05 就成了迷你智慧音箱」时已介绍过如何用Google TensorFlow Lite for Microcontrollers (TFLM)完成语音(命令)辨识,在[Day 19] tinyML开发好帮手─云端一站式平台Edge Impulse简介 时已介绍过如何建置Edge Impulse开发的环境建置。接下来就实际操练一下,看看如何把原来的英文的「Yes」、「No」单词改成中文的「红」、「绿」及「未知(Unknow)」和「背景音(Silence)」。
目前Edge Impulse提供了两个和声音有关的范例「Responding to your voice」、「Recognize sounds from audio」。前者为唤醒词侦测(Key Word Spotting)或语音命令辨识,其语音内容为一短单词(1秒内),有明显间歇、变化的内容。而後者为一连续性没明显变化的不同背景音分类,如背景讲话声(离很远、听不清楚的内容)和水流声等。但其实这两者的本质还是相同的,就是把连续声音切成很多小段(视窗)再进行分类(辨识)工作。接下来我们就取前者范例依序来说明如何完成这个范例。不过由於文章内容较长,所以将会拆成几篇来说明。
Edge Impulse 操作介面
Edge Impulse 操作介面选单如图Fig. 20-1所示。包含下列项目。如果想要移除已建立的专案或资料集,在主要仪表板的最下方有一个危险区域(Danger zone),按【Delete this project】可删除专案,按【Delete all data in this project】可删除所有资料集。另外如果你嫌训练时间过长,他们亦有提供商业版本,可修改仪表板上的「Performance settings」来动用GPU或更多平行计算资源来帮忙,目前免费版本是无法修改这些数值的。
Edge Impulse工作选单
- Dashboard 主要仪表板
- Devices 连线装置
- Data acquisition 资料撷取
- Impulse design 模型设计
- EON Tuner 参数调校(Edge Optimized Neural, 新AutoML工具)
- Retrain model 重新训练
- Live classification 即时分类
- Model testing 模型测试
- Versioning 版本管控
- Deployment 模型布署
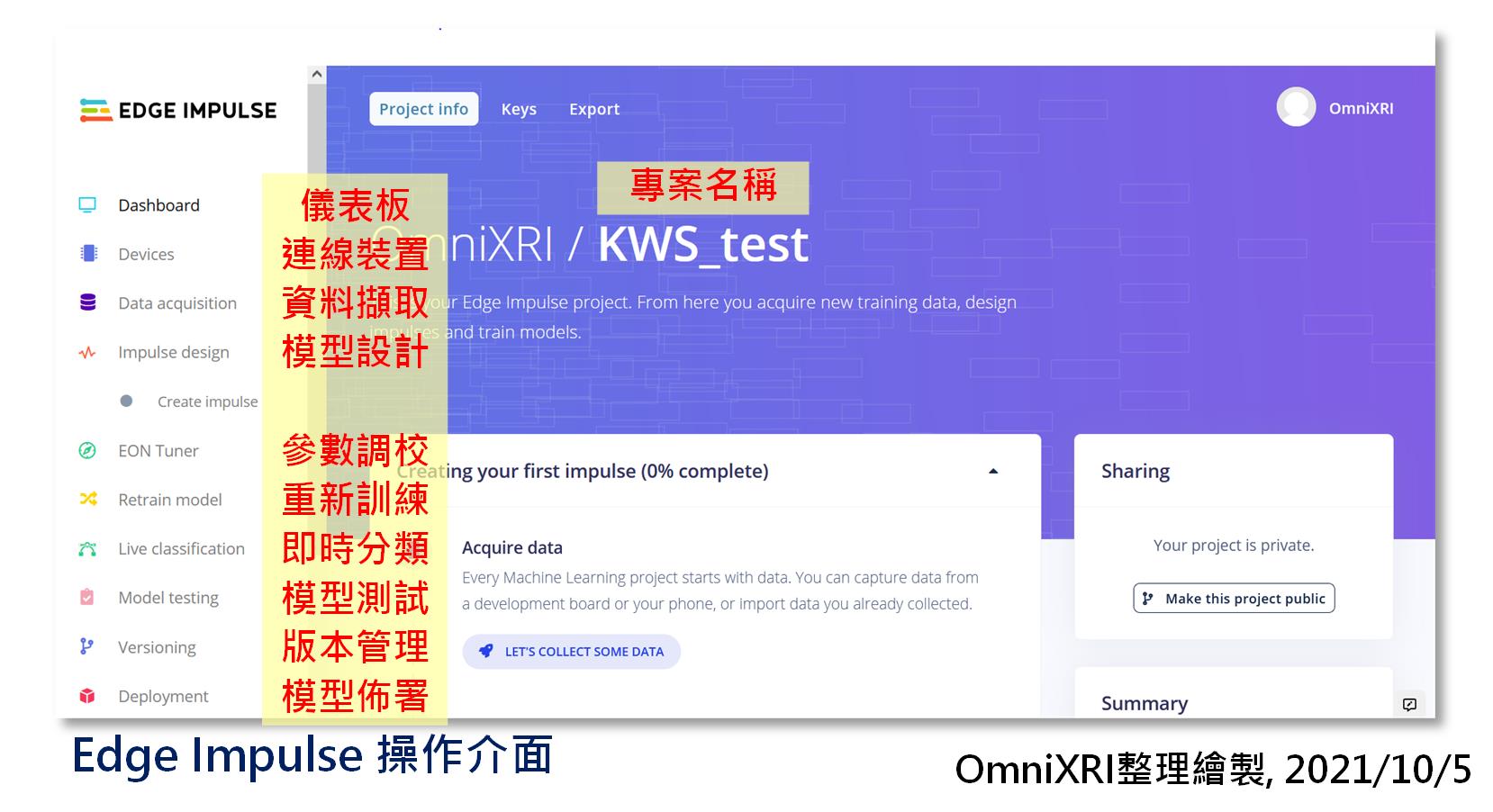
Fig. 20-1 Edge Impulse 操作介面。(OmniXRI整理绘制, 2021/10/5)
连线装置
在[Day 19] tinyML开发好帮手─云端一站式平台Edge Impulse简介时已说明过如何将开发板连上网页浏览器,这里就不多作说明。不过如果有发生上网正常,Edge Impulse工作网页开着但是开发板却连不上时,建议可先拔除USB,稍待数秒後再插回,接着再进到Windows命令列模式执行下列指令,强迫重新连线,此时就会出现提示输入使用者姓名(或电子邮件)、登入Edge Impulse密码及开发板名称,如此便可重新连线。
edge-impulse-daemon --clean
资料撷取
目前Edge Impulse提供离线把样本及标注资料准备好再上传,或者线上直接从开发板上的硬体(麦克风、运动感测器)撷取原始资料再从线上进行资料分割及标注,如图Fig. 20-2所示,这里会以後者进行介绍,即由使用者自行录音产生资料集。
取样前,要指定装置(Device),通常只有连接一组开发板时不用选。感测器(Sensor)部份则要选择内建麦克风(Build-in microphone)。接着设定取样时间(单位mS),可以设定长一点(比方10秒),方便一次录长一点,後面再来分割。再来设定取样频率,这里预设为16KHz,无法变更。然後指定标签(Label),比方说Green, Red等,不要用中文命名,但录音内容则没有限制,甚至台语也OK。最後按下【Start Sampling】,等待【Waiting to start】结束,出现【Sampling】就能开始录制,录制时会出现倒计时,方便使用者了解剩余时间。
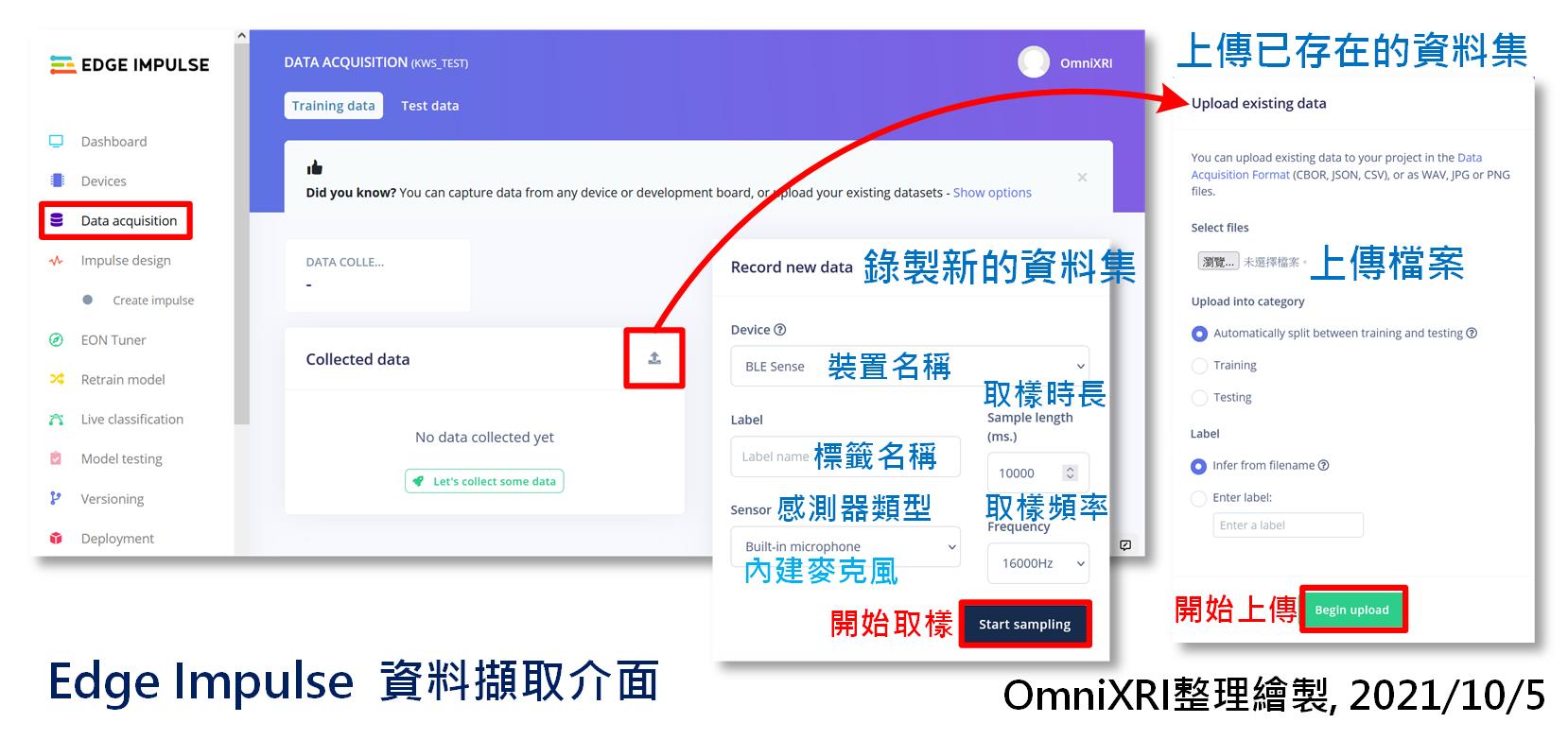
Fig. 20-2 Edge Impulse 资料撷取介面。(OmniXRI整理绘制, 2021/10/5)
录的时候请不要直接对着嘴巴而是要偏一边,以免录到太多气音。另外请在背景音较安静的环境下录制,届时辨识效果会更好些。以想要录「绿」这个中文单词为例,就连续发出「绿—绿— … 绿—绿—」(—号代表停顿),直到取样时间到,系统会自动命名存档。录完後已蒐集资料(Collected data)清单上会多出一笔资料,当点击这笔资料时画面左下角会出现录制到的声音档波形,按下三角形播放键就能听到刚才录制的结果。如果样本数不够,则再多录几次即可。
接着点击清单上最右边的三个点符号,选择「Split sample」,做声音资料自动分割。进入後会看到系统已自动帮忙切割好1000ms为单位的格子,如果长度不符可自行调整右上角的「Set segment length(ms):」的数值,按下【Apply】即可重新分割。如果分割的位置不理想,可将游标移到格子上方(会出现手掌游标)再按下滑鼠左键拖拉左右移动。若有漏框到的,亦可点左上角「+Add Segment」再利动游标到想分割的地方点击下去,就会产生新格子。当点击指定格子时,可按下方三角形播放键,试听一下内容是否正确,若不满意可按格子上方的红色按键【Remove segment】删除格子。最後按下左下角【Split】就能分割资料。回到资料清单後,就会发现原来的档案已被分割成数个单独「绿」单词的声音样本。完整步骤如图Fig. 20-3所示。
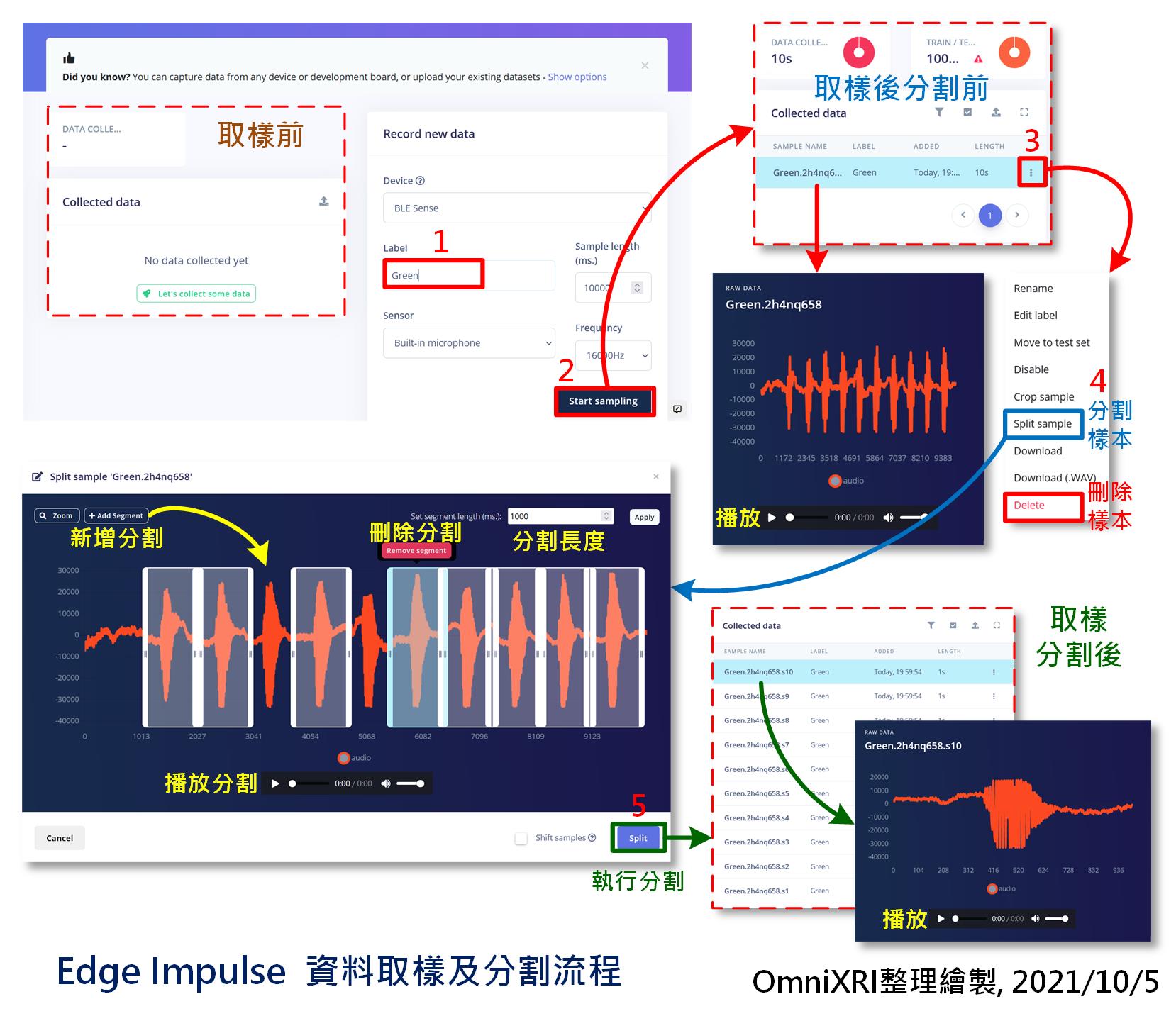
Fig. 20-3 Edge Impulse资料取样及分割流程。(OmniXRI整理绘制, 2021/10/5)
依据Edge Impulse官方文件建议,一个标签(Label)最好能录个10分钟,假设每样本为1秒钟,那10分钟就有600个样本。当然如果可能的话,可以找10个人一个人录1分钟,或者加入不同的背景杂音,以增加资料集的多样性,更有利模型训练。当然好的样本是不嫌少,越多越好,但如果只是想练习一下,不考虑准确性,那至少每个标签要准备个10到20笔。
最後收集完足够的资料後,还要将资料再分成训练集(Training data)和测试集(Test data),才算完成。通常建议训练集80%,测试集20%,可自由调整,且每个标签的数量要尽可能平均,不要差太多,以免後续训练时造成有特殊倾向。分割资料集只需点击「Collected data」右侧的「打勾」符号,样本档案名称左边就会出现方框等待勾选,待勾选完後再点击【Move to test set】就可将勾选内容搬到测试集中。若想重新调整,则可点击页面最上方的【Test data】就可进到测试集,进行反向操作,勾选档案并点击【Move to training set】即可将资料重新搬回训练集中。
更完整的说明可参考文末连结[说明文件]。
=== 未完待续 ===
参考连结
Edge Impulse Tutorials - Responding to your voice 说明文件
>>: Day 20 - Maybe Monad II (Piping)
【Day 30 】 Custom field 进阶篇,让你学会与custom post type 一并使用
在上次介绍关於custom field时,我们有提及过有关於栏位类型部份。不过那时候,主要是介绍一些...
[DAY18]Helm棒~~
Helm 常用command 以下指令应该是常常会操作到 helm create : 建立chart...
Kotlin Android 第10天,从 0 到 ML - Kotlin 与 Java 互动操作
前言: 虽然kotlin 为android 官方首选语言,新专案大都也是用kotlin ,但是免不了...
[Vue.js] 基本语法
(以下文章适用於Vue.js 2.X版本) Vue.js 官方手册 起手式 引入 Vue.js ne...
(Hard) 30. Substring with Concatenation of All Words
You are given a string s and an array of strings w...