爬虫怎麽爬 从零开始的爬虫自学 DAY20 python网路爬虫开爬-3抓取整页标题
前言
各位早安,书接上回我们已经知道抓取想要的网页资讯的逻辑了,也成功抓到了,今天我们的目标是抓取一整页文章标题
开爬-整页标题抓取
一样以 PTT 股票版为例
继续加强我们的程序
我们先打开原始码看看标题在哪
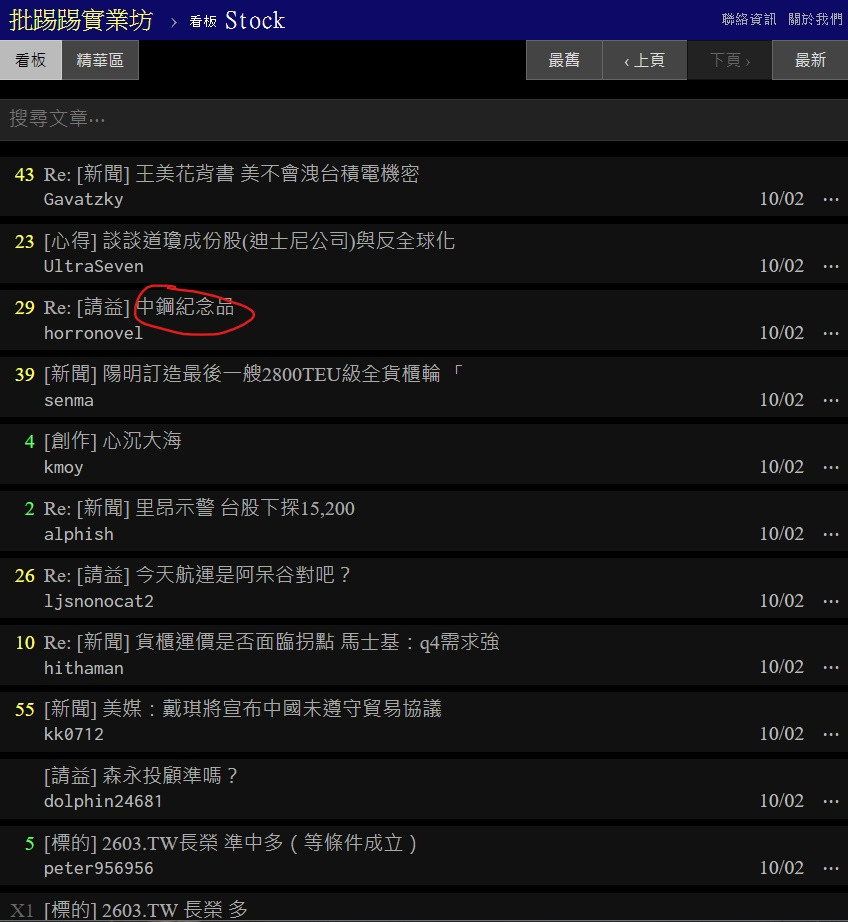
可以看到跟昨天文章内容不一样 因为这上面的资讯都是实时更新的
我们要的标题位置以中钢纪念品为例
一样右键检视网页原始码 接着按 CTRL+F
就会出现可以查询文字的地方
打上要搜寻的 中钢纪念品 它就会显示文字位置
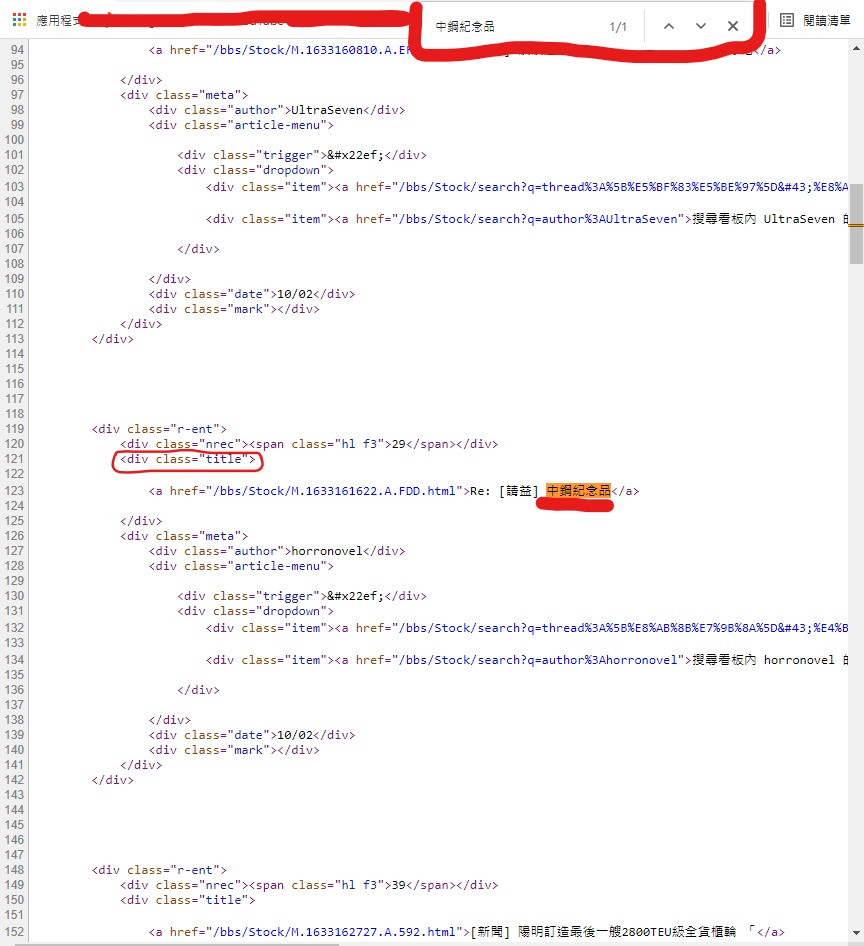
可以看到它是在 < div class="title" > 标签内
所以程序码後面加上
titles = data.find("div", class_ = "title")
建立 titles 变数存放我们的资料
资料从 data 里解析过的资料内 抓取 标签为 < div > 且 class = "title" 的资料
也就是我们刚刚看到 中钢纪念品 的位置
因为我做这篇时间太久
所以 PTT 更新了
但是我们要抓的依旧是文章标题没错
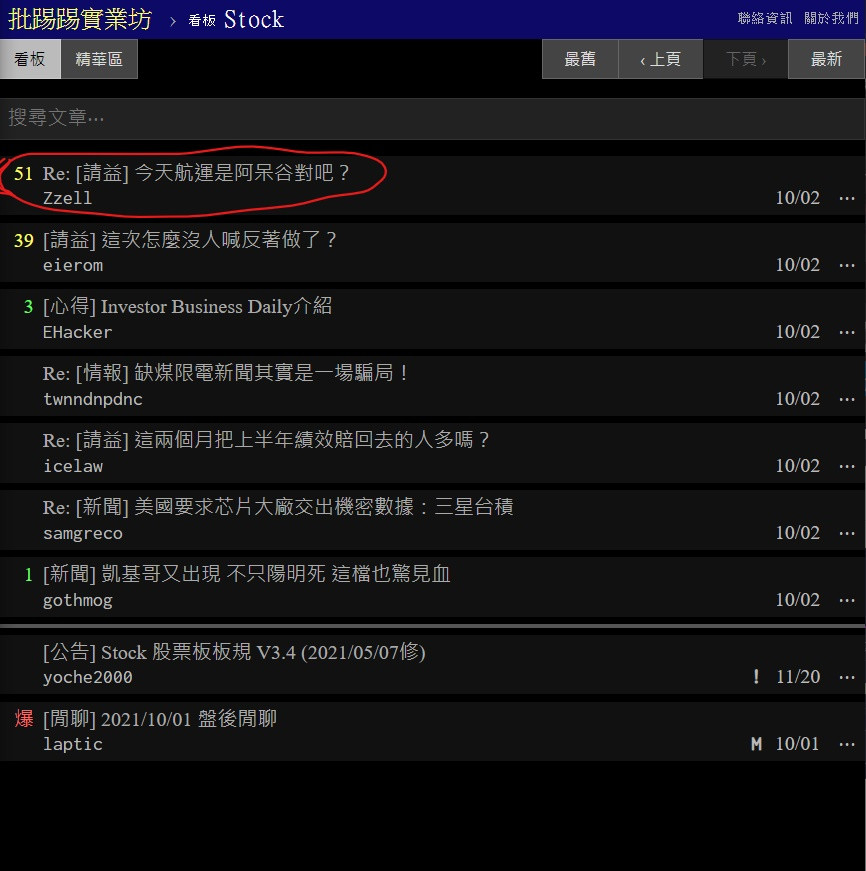
等等应该会抓到这个标题
到时候你们抓到的会是你们网页开起来後的第一个标题
最後把 print 内改成 titles
程序码目前是这样
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的网页原始码
request = requests.get(url)
#将网页资料利用requests套件GET下来
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find("div", class_ = "title")
print(titles)
#解析网页原始码
执行 python crawler.py
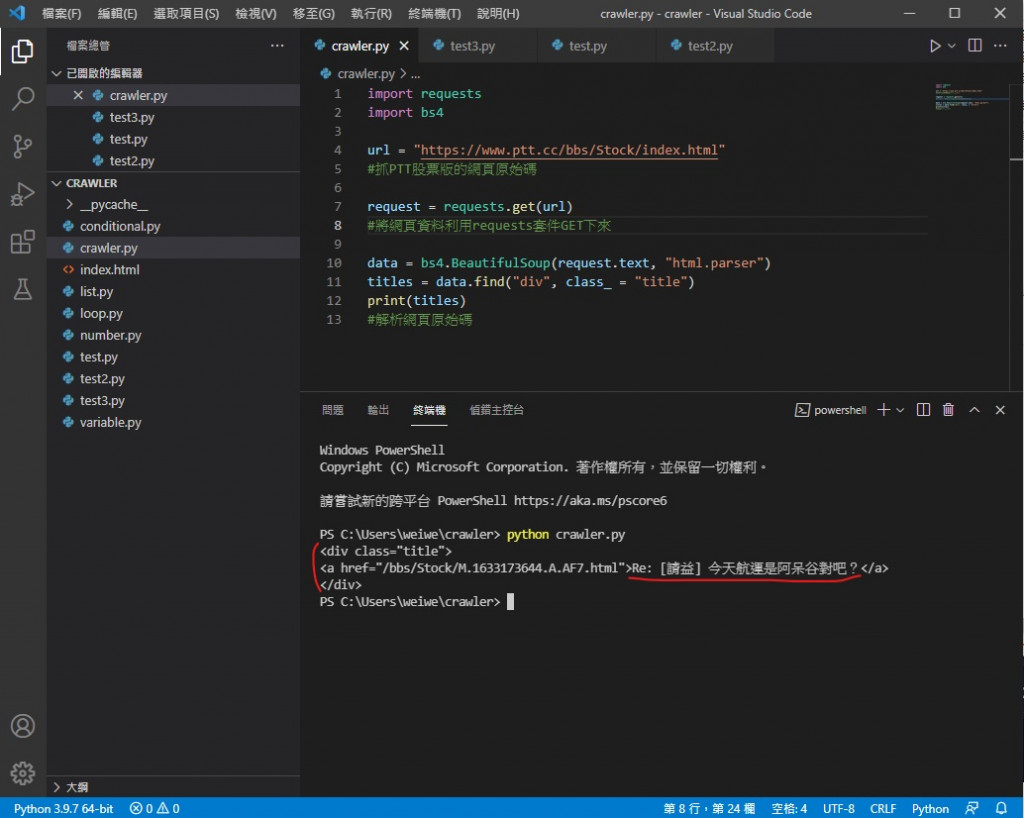
成功印出了 但是有讨厌的标签在不好看
那如果想要去掉标签
就要再往内指定
把 print(titles) 改成 print(titles.a.text)
因为可以看到我们要的文字部分是在 < div > 标签内的 < a > 标签里
而变数 titles 本身就已经指定到 < div > 标签内了
所以再 .a 就好
最後的 .text 则是指定 < a > 标签内的文字部分
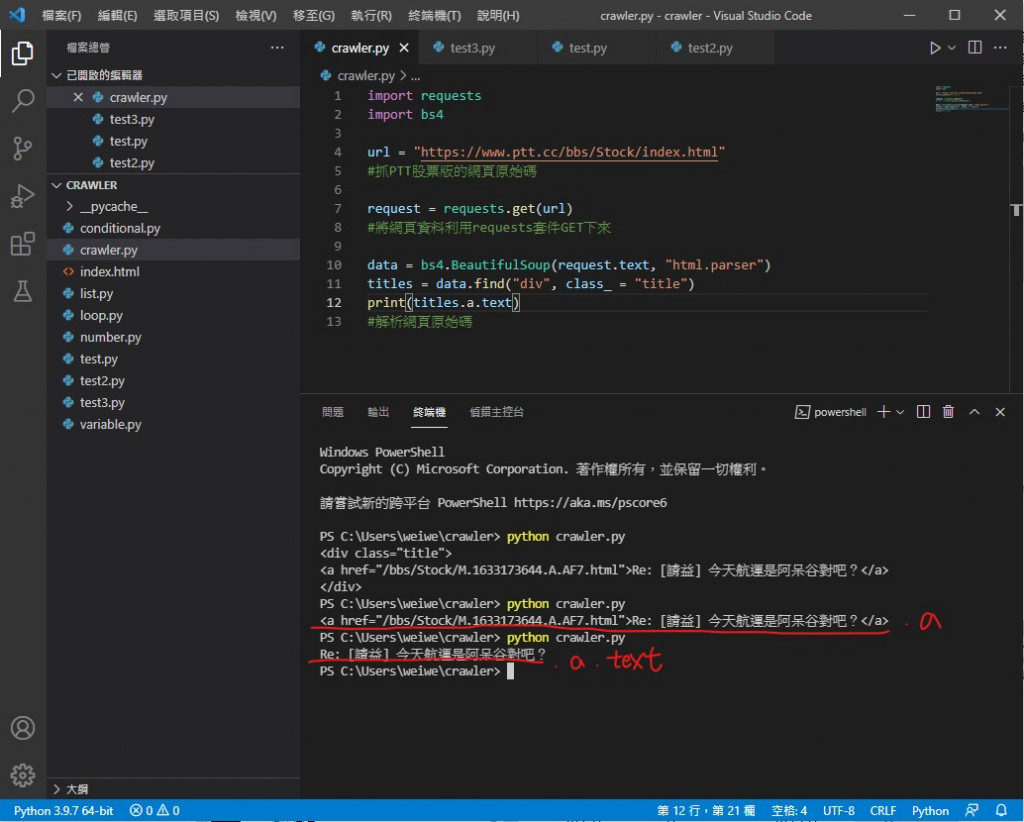
就像这样 成功只剩下文字了
但是我们要看不会只看第一个标题吧
所以要整页的标题就要 把 titles = data.find 改成 titles = data.find_all
就是从找到一个变成找到全部
但是光这样不行 直接执行会喷错
因为现在 titles 内有好几个 < div > 标签跟 < a > 标签
所以要用 for 回圈一个一个印出来
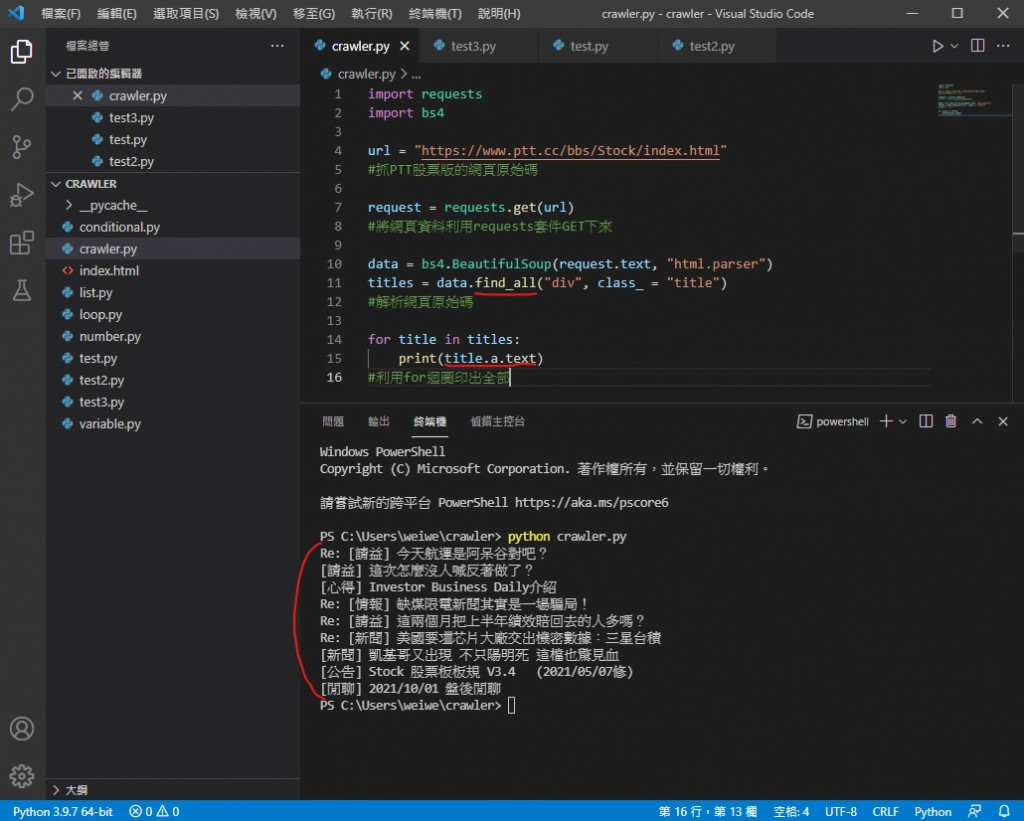
最後就像这样 得到整页的文章标题了
如果在执行上遇到错误 代表文章中有已经被删除的
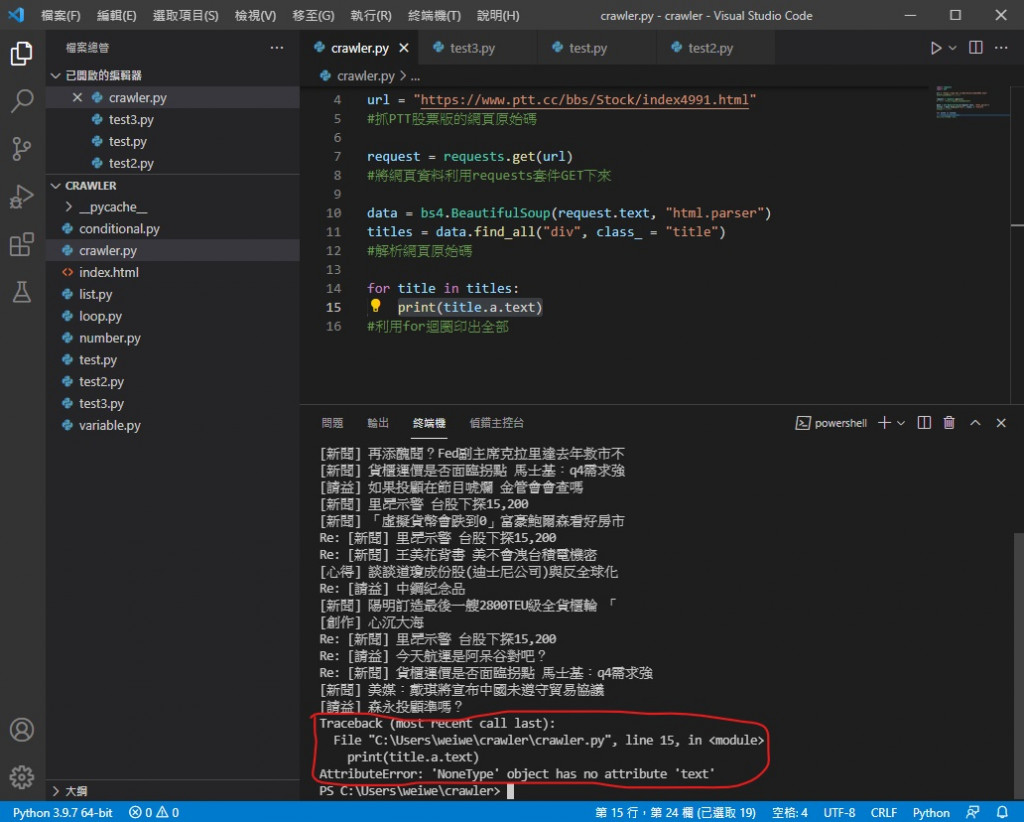
因为被删除的文章没有 a 标签 程序会找不到目标就喷错
必须在 for 回圈中加一个 if 用来去掉没标题的文章
改成这样就可以了
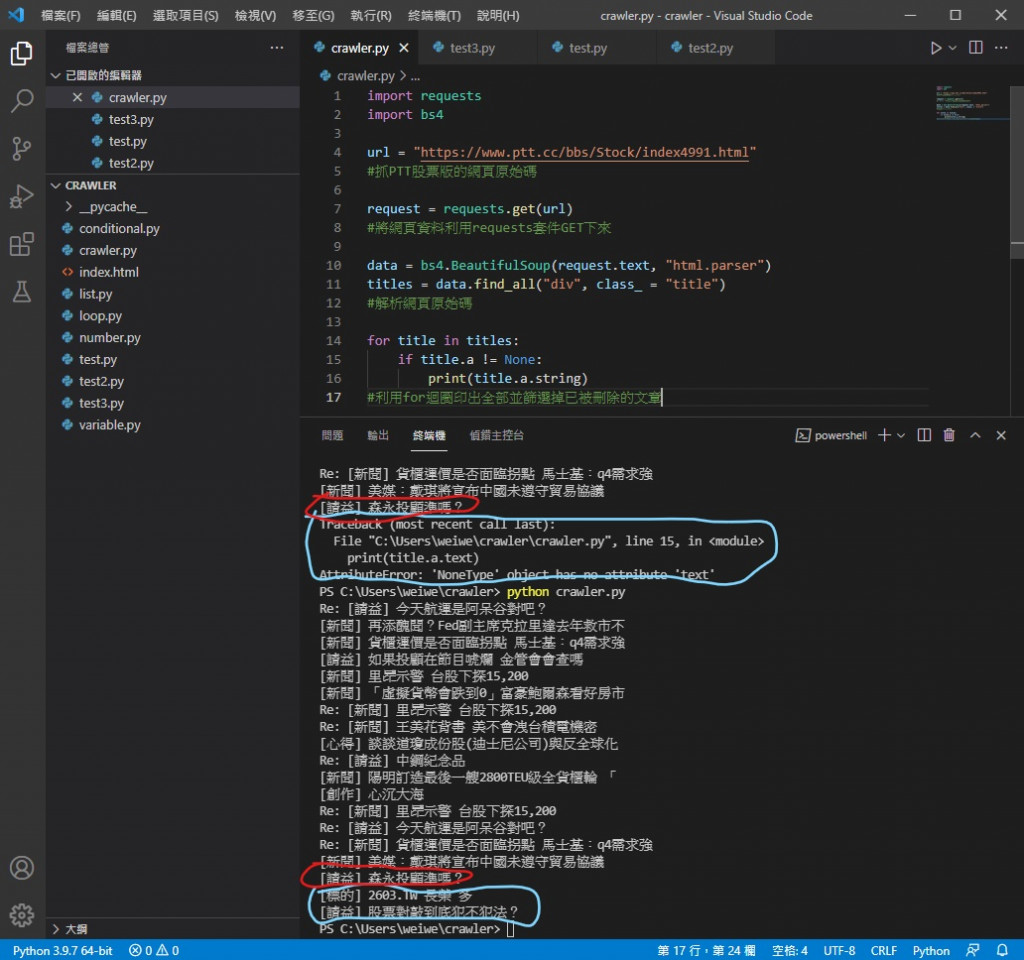
可以看到没有喷错 剩下的文章标题也正常印出
今天的程序码
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index4991.html"
#抓PTT股票版的网页原始码
request = requests.get(url)
#将网页资料利用requests套件GET下来
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
for title in titles:
if title.a != None:
print(title.a.string)
#利用for回圈印出全部并筛选掉已被删除的文章
今天我们已经能印出整页所有标题 而且没有标签影响美观 也筛选掉已删除的文章
明天我们要来实作更进阶的功能
早安闲聊区
你知道吗?
贩毒比吸毒判刑更重喔 (珍爱生命远离毒品 碰了不只犯法还会变笨喔)
每日二选一
你希望另一半比自己年长还年轻呢
Day 18 wait group 的使用
Wait group wait group 通常用来等待一组 goroutine 完成工作。 wai...
[机派X] Day2 - 树莓派碰上 Ubuntu
引言 今天是机派X系列文章的第二天,这篇文章终於要进入正题了! 首先,我们要在树莓派上安装 Linu...
求助 Excel VBA 搜寻关键字後贴到其他的tab的写法
各位先备好 如果有一个excel里面资料大概有50列,而每一行都是记载着不同的资讯,譬如:姓名/电话...
用 Python 畅玩 Line bot - 05:MessageEvent
除了文字讯息以外, Line 还有很多种讯息型态可以传送,例如图片,音档,贴图......。 我们可...
【第三天 - Flutter Route 规划分享】
今日的程序码 => GitHub 前言 大家应该都知道 Flutter 的跳页都会分成 2 ...