[Day20]程序菜鸟自学C++资料结构演算法 – 杂凑法(Hash)
前言:之前谈到的方法都需要透过「关键字」的比较来找出想要的值,但是杂凑法与之前的搜寻法有些差异,究竟是甚麽原因让杂凑法如此特别,想知道原因就继续看下去吧!
甚麽是杂凑法?
基本上杂凑法就是将原本的资料经过一个特殊的公式所产生的产物,以便後续的利用,而这个特殊的公式称为杂凑函式,产物则称为杂凑值。
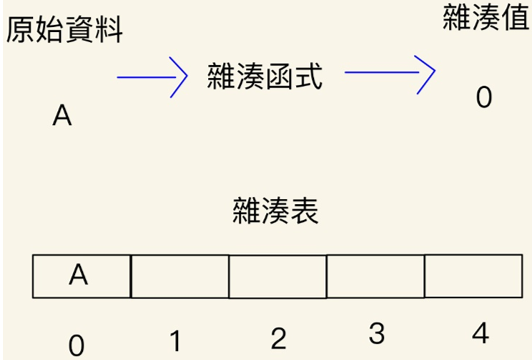
杂凑值最常用来当作储存原始资料的地址於杂凑表中,且杂凑值是不可逆的,无法将杂奏值推算回原始资料,也就是说如果没有杂凑表只有杂凑值是没有任何意义的。
杂凑的应用:第一个就是今天的重点杂凑表,再来因为杂凑值不可逆的关系起到保护资料的效果,其他也有语音辨识、错误校正等多种应用方式。
杂凑法名词整理:
介绍完了定义和应用,再把容易混淆的名词厘清吧!
杂凑函数 (Hashing Function)
可将资料转换成资料储存位址的公式。
杂凑值 (Hash Code)
原始资料经过杂凑函数所计算的结果,计算出来的结果无法回推原始资料。
杂凑表 (Hash Table)
为连续的记忆体,用来储存原始资料,类似一种索引表格,可根据杂凑值直接查询储存资料的位址。(可分为多个桶)
桶 (Bucket)
杂凑表中储存资料的地方,每一笔资料都对应到唯一的一个位址 (Bucket Address)。(可分为多个槽)
槽 (Slot)
每一笔资料种可会有好几个栏位,而「槽」就是指「桶」中的栏位。
碰撞 (Collision)
若多笔不同的资料,经过杂凑函数运算後得到相同的位址(杂凑值一样),则会使用到同一个Bucket。
溢位 (Overflow)
资料经过杂凑函数的计算後,如果桶已经被其它资料存满,则此笔资料无法储存在该位址,会使Bucket发生溢位。
同义字 (Synonym)
当两个识别字经杂凑函式计算後得到相同的数值时,则称这两个识别字与此凑函式是同义字。
载入密度 (Loading Factor)
指识别字的使用数目除以杂凑表内槽的总数。
公式:α(载入密度)=s(每一个桶内的槽数)b(桶的数目)
完美杂凑 (Perfect Hashing)
指没有碰撞和溢位的杂凑函式。
设计杂凑函式须注意的事:
- 降低碰撞和溢位的发生。
- 不要太过复杂,越容易计算越好。
- 尽量把文字的键值转成数字的键值,以方便计算。
- 得到的杂凑值尽量均匀的分布在各个桶内,不要太过於集中。
杂凑函式的常见类型:
没有特别规定必须要用哪种方法,只要多加注意溢位和碰撞的问题即可。
除法 (Mod /Division)
最简单的杂凑函式,将资料除以一个常数後,取於数来当杂凑值索引。
中间平方法 (Middle Sequare)
和除法类似,先讲资料乘上自己,在取中间的某段数字当作杂凑值索引。
折叠法 (Folding Addition)
将资料转换成一串数字後,在将这串数字分成多个部分,最後再相加起来。
可分为两种移动折叠法 (Shift Folding)和边界折叠法 (Boundary Folding)。
数位分析法 (Digits Analysis)
适用於资料都会更改的数字型静态表,在决定杂凑函式时会先检查资料的相对位置和分布情形,将重复性高的部分删除。
碰撞问题及溢为处理:
线性探测法 (Linear Probing)
当发生碰撞时,若该杂凑值已有资料,则以线性的方式往後寻找空的储存位置,一找到就将资料放入。这种方法通常把杂凑视为环状结构,一旦後面的位置被填满而前面还有位置时,可以将资料往前放。
平方探测法 (Quadratic Probing)
若发生溢位,可以代入公式 ,H(x)代表杂凑值,b为资料可储存在桶中的数量,i=1,2,3,4….持续增加,若i代入1还是有溢位,则将i代入2,以此类推。
再杂凑法 (Rehashing)
当使用第一种杂凑函式发生一位时,则准备第二种杂奏函式,若还是有溢位则再使用第三个,直到没有溢位为止。
连结串列 (Chaining)
将杂凑表的所有空间(桶)都建立成串列,如果发生溢位,则把一开始的串列当成列首,多出来的资料接在後方即可。
一样没有特定的方法处理溢位,如果杂凑函式和溢位处理的种类有那里不懂的可以查查看网路上的范例,会比较好理解。
本日小结:今天的资讯量已经很多了,在继续讲下去恐怕效果会不好,明天再来实作杂凑的内容,因为之前有学过链结串列,所以会用串列法来实作,忘记的人可以回去看看!
DAY16 机器学习专案实作-员工离职预测(上)
一、前言 前面学了这麽多的方法,大家是不是在烦恼要怎麽使用?或是不知道该用在什麽地方?今天就由小编来...
Day16 资料库-model的创建(2)
我们昨天教了最基本的model建立了,相信大家应该大致都懂那些流程了吧!(应该都懂吧...) 大家一...
30天学会 Python: Day 12-人生苦短,使用 Python
Python 还有很多不同功能的内建函式,以下列出一些满常用到的 数学相关 abs(x) 回传 x ...
[Python]使用Pillow,将图片由RGB转灰阶(Grayscale)
RGB -> Gray scale Gray scale(灰阶影像) from PIL imp...
React Custom hook 踩坑日记 - form hook
今天分享一个简单又常用到的方法来处理表单,先举个新手进入React处理表单时常用到的例子: // 使...