Day 18 网页分析 - Web Application Analysis (Skipfish )
工具介绍
Skipfish是一个google开发的网页安全扫描工具,主要特色如下
- 纯C打造的高效工具、低CPU使用率,轻松实现每秒2000个请求
- 支援各种网页框架、混合型网页,具有自动学习功能、动态词表创建和表单自动完成功能。
- 高品质、低误报
使用方式的确很容易,用-o指定最後报表存放的资料夹名称,最後带目标网页,这边用靶机来测试
Skipfish -o folder http://192.168.1.86
执行後会先显示一些提示,可以直接Enter继续执行
Welcome to skipfish. Here are some useful tips:
1) To abort the scan at any time, press Ctrl-C. A partial report will be written
to the specified location. To view a list of currently scanned URLs, you can
press space at any time during the scan.
2) Watch the number requests per second shown on the main screen. If this figure
drops below 100-200, the scan will likely take a very long time.
3) The scanner does not auto-limit the scope of the scan; on complex sites, you
may need to specify locations to exclude, or limit brute-force steps.
4) There are several new releases of the scanner every month. If you run into
trouble, check for a newer version first, let the author know next.
More info: http://code.google.com/p/skipfish/wiki/KnownIssues
扫描需要很长的时间,像下面这张图就已经是跑了49分钟还没结束的状况,从纪录看来已经扫描出
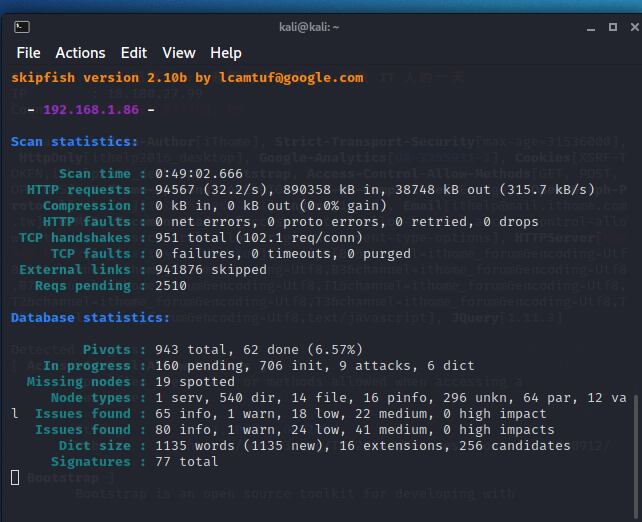
如果要中断扫描,可以按Ctrl + C,工具会结束并标明是由使用者中断,且扫描的所有纪录都会被放在执行时所指定的资料夹
[!] Scan aborted by user, bailing out!
[+] Copying static resources...
[+] Sorting and annotating crawl nodes: 1141
[+] Looking for duplicate entries: 1141
[+] Counting unique nodes: 1077
[+] Saving pivot data for third-party tools...
[+] Writing scan description...
[+] Writing crawl tree: 1141
[+] Generating summary views...
[+] Report saved to 'folder/index.html' [0x9d5cc49b].
[+] This was a great day for science!
储存的结果可以直接透过浏览器来打开
open folder/index.html
接着就可以用浏览网页的方式,点开问题来看细节
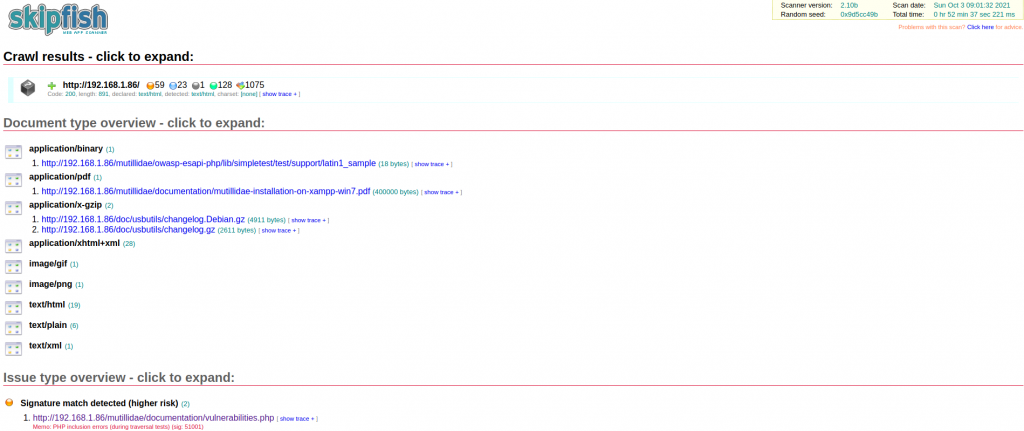
细节显示了完整的HTTP请求与回应,但具体的问题是什麽其实还是看不懂,而且整体扫描时间很长,这次的测试环境都是在区网内,要是去测试外网的网站,那需要的时间必定会长许多,所以其实工具在一开始执行的时候也有提到,如果需要在复杂站点上做测试,需要自行指定排除某些扫描行为。
<<: [Day18] Tally String Times with Reduce
图的连通 (4)
9 三连通图 如果一图 G 有至少 k 个点、并且拿掉任何 k-1 个点以後都还是保持连通的,那麽我...
Day 17 - Linux 上设定 PBR
我们需要使用 FRRouting,若还没安装的话,请先安装一下 这次使用的系统为 Ubuntu 20...
Batch Processing (4) - Materialization of Intermediate State
Beyond MapReduce 尽管 MapReduce 在 2000 年以後很夯,但它毕竟是分散...
Flutter基础介绍与实作-Day19 FireBase-设定问题
大家昨天设定完Firebase有没有发现一个问题啊,要开启Google登入时,专案必须要有SHA1指...
Day 13 | 元件状态:轮询 Polling
今天要介绍的功能 Polling ,用Google 翻译出来是「轮询」,不过这个词并不常见就是了,大...